标签:三层 类型 dfs input mapred 相对 思想 exti pre
MapReduce设计构思
①如何对付大数据处理:分而治之
②构建抽象模型:Map 和 Reduce两个函数
MapReduce 处理的数据类型是<key,value>键值对
③统一构架,隐藏系统层细节
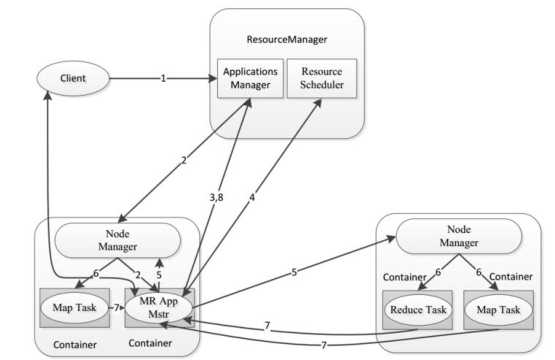
MapReduce框架结构
①MRAppMaster:负责整个程序的过程调度及状态协调
②MapTask:负责 map 阶段的整个数据处理流程
③ReduceTask:负责 reduce 阶段的整个数据处理流程

标签:三层 类型 dfs input mapred 相对 思想 exti pre
原文地址:https://www.cnblogs.com/lifuwei/p/9403496.html