标签:miss 来源 .so 关联性 因此 取数 slice 目录 方便
1. 问题描述
记录关联问题(Record Linkage):有大量从一个或多个源系统来的记录,其中有些记录可能代表了相同的基础实体。
每个实体有若干个属性,比如姓名、地址、生日。我们需要根据这些属性找到那些代表相同实体的记录。
不幸的是,有些属性值有问题:格式不一致,或有笔误,或信息缺失。如果简单的对这些属性做相等性测试,就会漏掉很多重复记录。
可以看出,下面两条记录看起来是两个不同的咖啡店,其实是同一个咖啡店:

而下面两条记录看起来是两条相同的记录,却是两个不同的业务部门:

2. 样例数据:
样例数据来自加州大学欧文分校机器学习资料库(UC Irvine Machine Learning Repository)。
这里要分析的数据集来源于一项纪录关联研究,是德国一家医院在2010年完成的。这个数据及包含数百万对病人记录,每队记录都根据不同标准来匹配。比如病人姓名、地址、生日。
每个匹配字段都被赋予一个数值评分,范围为0.0 到 1.0,分值根据字符串相似度得出。然后这些数据交给人工处理,标记出哪些代表同一个人哪些代表不同的人。
为了保护病人隐私,创建的数据集的每个字段原始值被删除。病人的ID、字段匹配分数、匹配对标识(包括匹配的和不匹配的)等信息是公开的,可用于纪录关联研究。
3. 获取数据:
$ mkdir linkage
$ cd linkage/
$ wget https://archive.ics.uci.edu/ml/machine-learning-databases/00210/donation.zip
$ unzip donation.zip
$ unzip ‘block_*.zip‘
放入HDFS:
$ hadoop fs -mkdir linkage
$ hadoop fs -put block_*.csv linkage
4. Spark 步骤:
一般来说,Spark 程序通常包括一系列相关步骤:
1. 在输入数据集上定义一组转换
2. 调用action,用以将转换后的数据保存到持久存储上,或者把结果返回到驱动程序的本地内存
3. 运行本地计算,本地计算处理分布式计算的结果。本地计算有助于你确定下一步的转换和action
5. Spark 基本操作:
在集群上启动Spark Shell:
spark-shell --master yarn
基本操作:
:help
:history
:paste => 进入paste模式,拷贝到里面,然后执行
Spark context available as ‘sc‘ (master = yarn, app id = application_1529488616304_14393).
sc表示对SparkContext的引用,它负责协调集群上Spark作业的执行
scala> sc
res0: org.apache.spark.SparkContext = org.apache.spark.SparkContext@58a7a58d
这个表示sc是一个SparkContext对象,这个对象为:对象名@对象内存地址
既然为对象,即会有方法。
6. RDD
SparkContext 里使用的最多的方法为创建RDD(Resilient Distributed Dataset),弹性分布式数据集。
RDD是Spark所提供的最基本的抽象,代表分布在集群中多台机器上的对象集合。
Spark 有两种方法可以创建RDD:
1. 用SparkContext 基于外部数据源创建 RDD, 外部数据源包括HDFS上的文件、通过jdbc 访问的数据库表或 Spark shell 中创建的本地对象集合;
2. 在一个或多个已有 RDD 上执行转换操作来创建 RDD,这些转换操作包括记录过滤、对具有相同键值的记录做汇总、把多个RDD 关联在一起等;
对 RDD 可以很方便地描述对数据要进行的一串小而独立的计算步骤。
RDD 特点:
1. RDD 以分区(partition)的形式分布在集群中多个机器上
2. 每个分区代表了数据集的一个子集
3. 分区定义了Spark 中数据的并行单位
4. Spark 框架并行处理多个分区,一个分区内的数据对象则是顺序处理
创建RDD 最简单的方法:
scala> var rdd = sc.parallelize(Array(1, 2, 2, 4), 4)
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:24
第一个代表待并行化的对象集合,第二个参数代表分区的个数。当要对一个分区内的对象进行计算时,Spark 从驱动程序进程里获取对象集合的一个子集
7. Spark 作业提交
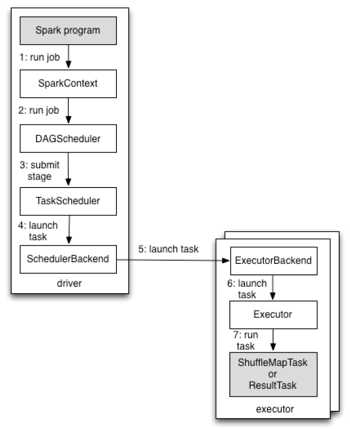
在最高层,它有两个独立的实体:driver 和 executor
the driver, which hosts the application (SparkContext) and schedules tasks for a job;
and the executors, which are exclusive to the application, run for the duration of the application, and execute the application’s tasks.
当对RDD 执行一个动作(比如 count)时,会自动提交一个Spark job,从内部来看:
1. 对SparkContext 调用runJob()
2. 将调用传递给调度程序 DAGScheduler
3. DAG调度把作业分解为多个阶段(stages),并由这些构成
一个DAG
4. 任务调度程序则负责把每个阶段中的任务提交
给集群
这里 DAG和任务调度程序便构成了driver实体,而执行任务的为executor实体
8. 创建数据RDD
1. 要在分布式文件系统(比如HDFS)上的文件或目录上创建RDD,可以给textFile 方法传入文件或目录的名称:
scala> var textFile = sc.textFile("hdfs:///user/hadoop/hi2", 4)
textFile: org.apache.spark.rdd.RDD[String] = hdfs:///user/hadoop/hi2 MapPartitionsRDD[11] at textFile at <console>:24
2. 如果输入是目录而不是单个文件,Spark会把该目录下所有文件作为RDD输入
3. 实际上Spark 并未将数据读取到集群内存中。当需要对分区内的对象进行计算时,Spark 才会读入输入文件的某个部分(也称切片),然后应用其他RDD 定义的后续转换操作(过滤和汇总等)
9. 读取数据
$ val rawblocks = sc.textFile("hdfs:///user/hadoop/linkage")
rawblocks: org.apache.spark.rdd.RDD[String] = hdfs:///user/hadoop/linkage MapPartitionsRDD[19] at textFile at <console>:24
声明了一个rawblocks 的变量,它的类型为 RDD[String]
虽然我们没有在变量声明时指定它的类型,但是 Scala 会使用“类型推断”来判断变量的类型。
在上面的例子中,Scala 会查找 SparkContext 对象 textFile 函数的返回值类型,发现该函数返回 RDD[String] 类型,于是就将 RDD[String] 类型赋值给rawblocks 变量
10. 把数据从集群获取到客户端
现在数据在集群上,如何在saprk-shell 里查看这些数据?
1. first 方法:返回RDD 第一个元素(对数据集做常规检查)
2. collect:返回一个包含所有 RDD 内容的数组(一般不这么做,因为不知道数据量大小)
3. take:向客户端返回一个包含指定数量记录的数组
scala> rawblocks.first
res3: String = "id_1","id_2","cmp_fname_c1","cmp_fname_c2","cmp_lname_c1","cmp_lname_c2"…
scala> val head = rawblocks.take(10)
head: Array[String] = Array("id_1","id_2" …)
scala> head.length
res6: Int = 10
11. 动作(Action)
1. 创建RDD 的操作(action)并不会导致集群执行分布式计算。相反,RDD 只是定义了作为计算过程中间步骤的逻辑数据集。只有调用RDD 上的 action 时分布式计算才会执行。如 count,collect等。
2. 动作不一定会向本地进程返回结果。saveAsTextFile 动作将RDD 的内容保存到持久化存储(如HDFS)。
该动作创建一个目录并为每个分区输出一个文件。
12. foreach
之前可以看到 head 是一个数组,打印head 的数据后,并不整齐。在此我们可以用foreach 方法:
scala> head.foreach(println)
"id_1","id_2","cmp_fname_c1","cmp_fname_c2","cmp_lname_c1","cmp_lname_c2","cmp_sex","cmp_bd","cmp_bm","cmp_by","cmp_plz","is_match"
37291,53113,0.833333333333333,?,1,?,1,1,1,1,0,TRUE
39086,47614,1,?,1,?,1,1,1,1,1,TRUE
70031,70237,1,?,1,?,1,1,1,1,1,TRUE
84795,97439,1,?,1,?,1,1,1,1,1,TRUE
36950,42116,1,?,1,1,1,1,1,1,1,TRUE
42413,48491,1,?,1,?,1,1,1,1,1,TRUE
25965,64753,1,?,1,?,1,1,1,1,1,TRUE
49451,90407,1,?,1,?,1,1,1,1,0,TRUE
39932,40902,1,?,1,?,1,1,1,1,1,TRUE
13. def
查看head 打印的数据,可以发现对于这次的数据分析任务来说,第一行我们是不需要的,所以我们需要将它清洗掉。
这里我们写一个函数判断哪些行是我们不需要的,如:
scala> def isHeader(line:String) = line.contains("id_1")
isHeader: (line: String)Boolean
def定义一个方法,line为参数,String为参数类型。SparkContext根据 line.contains() 方法的返回类型,指定了方法 isHeader() 的返回类型。
如果方法比较复杂且包含多个return,那么建议在定义方法时显示指定返回类型以获取更好的可读性,如:
scala> def isHeader(line:String) : Boolean = {
| line.contains("id_1")
| }
isHeader: (line: String)Boolean
14. filter
使用Scala 的 Array 类的filter/filterNot 方法可以过滤 Array 里的数据:
head.filterNot(isHeader).foreach(println)
scala> head.filterNot(isHeader).foreach(println)
37291,53113,0.833333333333333,?,1,?,1,1,1,1,0,TRUE
39086,47614,1,?,1,?,1,1,1,1,1,TRUE
70031,70237,1,?,1,?,1,1,1,1,1,TRUE
84795,97439,1,?,1,?,1,1,1,1,1,TRUE
36950,42116,1,?,1,1,1,1,1,1,1,TRUE
42413,48491,1,?,1,?,1,1,1,1,1,TRUE
25965,64753,1,?,1,?,1,1,1,1,1,TRUE
49451,90407,1,?,1,?,1,1,1,1,0,TRUE
39932,40902,1,?,1,?,1,1,1,1,1,TRUE
如果是用匿名函数:
scala> head.filter(x => !isHeader(x)).length
res10: Int = 9
这里 x 为一个变量,遍历head数组,每次执行一个isHeader()
当然,匿名函数可以简写为:
scala> head.filter(!isHeader(_)).length
res11: Int = 9
15. 把代码从客户端发送到集群
现在我们对head的处理仍在客户端,如果要应用到整个集群的RDD上:
scala> val noheader = rawblocks.filter(!isHeader(_))
noheader: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[2] at filter at <console>:27
然后使用新的变量.first 来查验结果:
scala> noheader.first
res12: String = 37291,53113,0.833333333333333,?,1,?,1,1,1,1,0,TRUE
这意味着,我们可以先从集群采样得到小数据及,在小数据集上开发和调试数据处理代码,等一切就绪后再把代码发送到集群上处理完整的数据集。
16. 数据结构化
我们看看head 数组的内容:
scala> head
res7: Array[String] = Array("id_1","id_2","cmp_fname_c1","cmp_fname_c2","cmp_lname_c1","cmp_lname_c2","cmp_sex","cmp_bd","cmp_bm","cmp_by","cmp_plz","is_match", 37291,53113,0.833333333333333,?,1,?,1,1,1,1,0,TRUE, 39086,47614,1,?,1,?,1,1,1,1,1,TRUE, 70031,70237,1,?,1,?,1,1,1,1,1,TRUE, 84795,97439,1,?,1,?,1,1,1,1,1,TRUE, 36950,42116,1,?,1,1,1,1,1,1,1,TRUE, 42413,48491,1,?,1,?,1,1,1,1,1,TRUE, 25965,64753,1,?,1,?,1,1,1,1,1,TRUE, 49451,90407,1,?,1,?,1,1,1,1,0,TRUE, 39932,40902,1,?,1,?,1,1,1,1,1,TRUE)
数据的结构如下:
现在的每行数据都是一条String,为了更容易分析这些数据,我们需要把字符串解析成结构化的格式,把不同字段转化成正确的数据类型,比如整数或双精度浮点数。
取一行进行分割:
scala> var line = head(5)
scala> val pieces =line.split(",")
scala> val id1 = pieces(0).toInt
scala> val id2 = pieces(1).toInt
scala> val matched = pieces(11).toBoolean
matched: Boolean = true
这里我们可以发现Scala 访问数组的方式是:
val id2 = pieces(1)
这里访问数组用的是函数调用,不是特殊操作符。Scala 允许在类里定义一个特殊函数 apply,当把对象当作函数处理的时候,这个apply 函数会被调用,所以 pieces(1) 等同于 pieces.apply(5)
与之前的 contains 方法和 split 方法不同的是:toInt 和 toBoolean 方法并不是由 Java 的 String 类定义的
这里用到了 Scala 的特性:隐式类型转换
工作原理如下:
当调用 Scala 对象的方法时,如果在定义该对象的类中找不到方法的定义,Scala 编译器就将该对象转换成有相应方法定义的类的实例。
在这个例子中,编译器发现Java 的 String 类没有定义 toInt 方法而 StringOps有,既然StringOps 定义了这个方法,那么就可以将String 类的实例转换成 StringOps 类的实例。
这时编译器就悄悄把String 对象转换成了 StringOps 对象,然后在新对象上调用 toInt 方法。
在转换了前三个字段后,我们仍需要转换双精度浮点数类型。
要一次完成转换,可以先用Scala Array 类的 slice 方法提取一部分数组元素,然后调用高阶函数 map 把 slice 中每个元素的类型从 String 转换为 Double:
scala> val rawscores = pieces.slice(2, 11)
rawscores: Array[String] = Array(1, ?, 1, 1, 1, 1, 1, 1, 1)
scala> rawscores.map(_.toDouble)
java.lang.NumberFormatException: For input string: "?"
at sun.misc.FloatingDecimal.readJavaFormatString(FloatingDecimal.java:2043)
从上面的报错,我们可以看到:由于数组里有未知元素’?’,所以StringOps 的 toDouble 方法不知道如何把 ? 转换成 double。
这里我们可以再写一个toDouble函数:
scala> def toDouble(line:String) = {
| if ("?".equals(line)) Double.NaN else line.toDouble
| }
toDouble: (line: String)Double
如果碰到”?”,则设置为 NaN 的值。
scala> rawscores.map(toDouble)
// 这里调用的是定义的toDouble函数而_.toDouble调用的是StringOps的toDouble
res22: Array[Double] = Array(1.0, NaN, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0)
最后把解析代码合并到一个函数,在一个元组中返回所有解析好的值:
def parse(line: String) = {
val pieces = line.split(",")
val id1 = pieces(0).toInt
val id2 = pieces(1).toInt
val scores = pieces.slice(2,11).map(toDouble)
val matched = pieces(11).toBoolean
(id1, id2, scores, matched)
}
scala> parse(line)
res6: (Int, Int, Array[Double], Boolean) = (36950,42116,Array(1.0, NaN, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0), true)
17. 元组
从元组中获取单个字段的值,可以用下标函数,从 _1 开始,或者用 productElement 方法,它是从 0 开始计数。也可以用 productArity 方法得到元组大小:
scala> var y = parse(line)
y: (Int, Int, Array[Double], Boolean) = (36950,42116,Array(1.0, NaN, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0),true)
scala> y.productArity
res14: Int = 4
18. case class
在定义好元组数据后,我们需要使用下标来访问数据。如果我们可以使用更有意义的名称来访问数据,会使代码更容易理解。
这里我们使用case class (其实有点像Java 里定义为某个需求单独定义的一个类):
scala> case class MatchData(id1:Int, id2:Int, scores:Array[Double], matched:Boolean)
defined class MatchData
将 case class 加入到方法parse:
scala> def parse(line:String) = {
| val pieces = line.split(‘,‘)
| val id1 = pieces(0).toInt
| val id2 = pieces(1).toInt
| val scores = pieces.slice(2, 11).map(toDouble)
| val matched = pieces(11).toBoolean
| MatchData(id1, id2, scores, matched)
| }
parse: (line: String)MatchData
19. 将方法应用到集群数据
1. 在小数据集上进行测试:
scala> head.filter(!isHeader(_)).map(parse(_))
2. 然后将方法用于集群上的数据:
scala> val parsed = noheader.map(parse(_))
parsed: org.apache.spark.rdd.RDD[MatchData] = MapPartitionsRDD[4] at map at <console>:27
由于没有对RDD 执行某个需要输出的调用,所以实际上这个方法还没有应用到原RDD 数据集
20. 缓存
现在数据已经解析好,我们想以解析了的格式把数据存到集群上,这样就不需要每次遇到新问题时都重新解析。
在实例上调用cache 方法,可以指示在内存里缓存某个RDD:
parsed.cache()
parsed.cache() => 下次计算RDD 后,要把RDD 存储起来
parsed.count() => 计算RDD,由于设置了cache,RDD结果会保存在内存
parsed.take(10) => take RDD里的10 个条目,会直接从内存中取
Spark 为持久化RDD 定义了几种不同的机制,用不同的 StorageLevel 值表示:
1. rdd.cache() 是 rdd.persist(StorageLevel.MEMORY) 的简写,它将 RDD 存储为未序列化的Java
对象。当Spark 估计内存不够存放一个分区时,它干脆就不在内存中存放该分区,这样在下次需要时就必须重新计算。
在对象需要频繁访问或低延访问时适合使用此级别,因为它可以避免序列化开销。但是相比其他选项,此方法要占用更大的内存空间。
另外,大量小对象会对Java的垃圾回收造成压力,会导致程序停顿和常见的速度缓慢问题。
2. MEMORY_SER 的存储级别:用于在内存中分配大字节缓冲区以存储 RDD 序列化内容。如果使用的当,序列化数据占用的空间比未经序列化的数据占用的空间往往要少两到五倍。
Spark 也可以用磁盘来缓存 RDD。存储级别为 MEMORY_AND_DISK 和 MEMORY_AND_DISK_SER 分别类似于 MEMORY 和 MEMORY_SER。
对于 MEMORY 和 MEMORY_SER,如果一个分区在内存里放不下,整个分区都不会放在内存。
对于MEMORY_AND_DISK 和 MEMORY_AND_DISK_SER,如果分区在内存里放不下,Spark 会将其溢写到磁盘上。
一般情况下,如果多个动作需要用到某个RDD,而它的计算代价又很高,那么就应该把这个RDD 缓存起来。
21. 聚合
因为大规模的数据集分布在多台机器上,对数据进行聚合时,我们更担心的是数据传输的效率。
我们接下来分别在本地客户端和集群上分别对MatchData 做简单的聚合操作,目的是计算匹配和不匹配的记录数量。
对于mds 数组的本地MatchData 记录,我们用groupBy 方法来创建一个 Scala Map[Boolean, Array[MatchData]],它的键是基于MatchData的matched 字段:
scala> val grouped = mds.groupBy(_.matched)
grouped: scala.collection.immutable.Map[Boolean,Array[MatchData]] = Map(true -> Array(MatchData(37291,53113,[D@39f29540,true], MatchData(39086,47614,[D@2bb5637a,true], MatchData(70031,70237,[D@1decf3e3,true], MatchData(84795,97439,[D@722b4f64,true], MatchData(36950,42116,[D@5fde8cf4,true], MatchData(42413,48491,[D@5f708ac6,true], MatchData(25965,64753,[D@25f90920,true], MatchData(49451,90407,[D@d813294,true], MatchData(39932,40902,[D@2613a6fc,true]))
得到grouped 的变量后,就可以通过在 grouped 上调用 mapValues() 方法得到计数。mapValues 方法和 map 方法类似,但作用在Map 对象中的值:
scala> grouped.mapValues(_.size).foreach(println)
(true,9)
以上只是对本地客户端数据进行聚合,但是对集群进行聚合时,一定要记住:
RDD 类定义了一个名为 countByValue 的动作,该动作对于计数类运算效率非常高,它向客户端返回 Map[T, Long] 类型的结果。
scala> val matchCounts = parsed.map(_.matched).countByValue()
matchCounts: scala.collection.Map[Boolean,Long] = Map(true -> 20931, false -> 5728201)
22. Seq
Scala 的Map 类没有提供根据内容的键或值排序的方法,但是我们可以将 Map 转换成Scala 的Seq 类型,而Seq 支持排序。
Scala 的 Seq 类和 Java 的 List 类接口类似,都是可迭代集合,即具有确定的长度并且可以根据下标来查找值。
scala> val matchCountsSeq = matchCounts.toSeq
matchCountsSeq: Seq[(Boolean, Long)] = ArrayBuffer((true,20931), (false,5728201))
23. Scala集合
Scala 集合类库很庞大,包括 list、set、map 和 array。利用 toList、toSet 和 toArray 方法,各种集合类型可以方便地相互转换。
24. sortBy
我们可以看到 matchCountSeq 的类型是:
Seq[(Boolean, Long)] = ArrayBuffer((true,20931), (false,5728201))
我们可以用 sortBy 方法控制用哪个指标排序:
scala> matchCountsSeq.sortBy(_._1).foreach(println) // 用第一列的指标
(false,5728201)
(true,20931)
scala> matchCountsSeq.sortBy(_._2).foreach(println) // 用第二列的指标
(true,20931)
(false,5728201)
默认sortBy 函数对数值按升序排列,如果需要用降序,可以用 reverse 方法,在打印前改变排序方式:
scala> matchCountsSeq.sortBy(_._2).reverse.foreach(println)
(false,5728201)
(true,20931)
如果对于离散型变量,可以使用countByValue 动作计算各个变量的数量。但是如果是连续型变量?
对于连续型变量,我们一般需要获取其分布的基本统计信息,如均值、标准差和极值(最大值与最小值)
RDD[Double] 有个隐式动作叫 stats,它可以提供RDD 值概要统计信息:
scala> parsed.map(_.scores(0)).stats
res23: org.apache.spark.util.StatCounter = (count: 5749132, mean: NaN, stdev: NaN, max: NaN, min: NaN)
但是由于数据不干净,有缺失值,所以影响了统计信息。
25. java.lang.Double.isNaN
对于缺失值,我们可以引入 Java Double 类的 isNaN 函数手动过滤:
scala> import java.lang.Double.isNaN
scala> parsed.map(_.scores(0)).filter(!isNaN(_)).stats()
res24: org.apache.spark.util.StatCounter = (count: 5748125, mean: 0.712902, stdev: 0.388758, max: 1.000000, min: 0.000000)
使用Scala 的 Range 结构创建一个循环,遍历下标并计算该列的统计信息:
val stats = (0 until 9).map( i => {
parsed.map(_.scores(i)).filter(!isNaN(_)).stats()
})
scala> stats(1)
res25: org.apache.spark.util.StatCounter = (count: 103698, mean: 0.900018, stdev: 0.271316, max: 1.000000, min: 0.000000)
25. NAStatCounter
如果使用上面的循环方法,我们需要一遍遍的遍历数据,并不是一个好的方式。所以我们使用一个类来跟踪之前的score 值:
这个类里有两个变量:stats 和 missing
stats 用于记录统计信息
missing 用于记录缺失值的数量
scala> val ns1 = NAStatCounter(10.0)
ns1: NAStatCounter = stat(count: 1, mean: 10.000000, stdev: 0.000000, max: 10.000000, min: 10.000000)NAN: 0
scala> ns1.add(2.1)
res1: NAStatCounter = stat(count: 2, mean: 6.050000, stdev: 3.950000, max: 10.000000, min: 2.100000)NAN: 0
scala> ns1.add(java.lang.Double.NaN)
res2: NAStatCounter = stat(count: 2, mean: 6.050000, stdev: 3.950000, max: 10.000000, min: 2.100000)NAN: 1
将NAStateCounter 应用到数据集:
scala> val nasRDD = parsed.map(_.scores.map(NAStatCounter(_)))
nasRDD: org.apache.spark.rdd.RDD[Array[NAStatCounter]] = MapPartitionsRDD[35] at map at <console>:30
也就是把scores 里的每一个Double 转换为NAStatCounter 的形式:stats 与 missing
scala> nasRDD.first
res46: Array[org.apache.spark.util.StatCounter] = Array((count: 1, mean: 0.833333, stdev: 0.000000, max: 0.833333, min: 0.833333), (count: 1, mean: NaN, stdev: NaN, max: NaN, min: NaN), (count: 1, mean: 1.000000, stdev: 0.000000, max: 1.000000, min: 1.000000), (count: 1, mean: NaN, stdev: NaN, max: NaN, min: NaN), (count: 1, mean: 1.000000, stdev: 0.000000, max: 1.000000, min: 1.000000), (count: 1, mean: 1.000000, stdev: 0.000000, max: 1.000000, min: 1.000000), (count: 1, mean: 1.000000, stdev: 0.000000, max: 1.000000, min: 1.000000), (count: 1, mean: 1.000000, stdev: 0.000000, max: 1.000000, min: 1.000000), (count: 1, mean: 0.000000, stdev: 0.000000, max: 0.000000, min: 0.000000))
26. 数据小结
现在我们对我们的数据做一下小结:
1. parsed 里的数据为:
scala> parsed.first
res2: MatchData = MatchData(37291,53113,[D@3789bd95,true]
对原数据处理后,有四个字段,分别为id1,id2,scores,matched。对于matched 字段我们已进行过简单的分析。
2. parsed.first.scores:
res5: Array[Double] = Array(0.833333333333333, NaN, 1.0, NaN, 1.0, 1.0, 1.0, 1.0, 0.0)
scores 是一个Double 数组,长度为9,里面存放了各个字段的相关系数,有缺失值。
3. nasRDD.first:
res4: Array[NAStatCounter] = Array(stat(count: 1, mean: 0.833333, stdev: 0.000000, max: 0.833333, min: 0.833333)NAN: 0, stat(count: 0, mean: 0.000000, stdev: NaN, max: -Infinity, min: Infinity)NAN: 1 ……)
length = 9
nasRDD 里存放的是NAStatCounter 的数组。9个元素与scores里的9个元素一一对应。
之前提到对于连续型变量,我们希望得到它们的统计值。所以接下来,我们统计的应该是9个列里每个列的stat()。如果要这么做,那么应该是单独计算:
nasRDD.first(0)、nasRDD.second(0) … nasRDD.nth(0)
nasRDD.first(1)、nasRDD.second(1) … nasRDD.nth(1)
…
27. zip
zip 函数可以将两个Array 合并:
a: Array[Int] = Array(1, 2, 3)
b: Array[Int] = Array(4, 5, 6)
scala> a.zip(b)
res18: Array[(Int, Int)] = Array((1,4), (2,5), (3,6))
我们可以使用zip 将每列的数据合并,然后用merge函数将每列的数据整合,如:
var azip = a.zip(b)
scala> naszip.map(a => a._1.merge(a._2))
res20: Array[NAStatCounter] = Array(stat(count: 2, mean: 0.916667, stdev: 0.083333, max: 1.000000, min: 0.833333)NAN: 0, …)
length = 9
在对整个数据集的时候,我们可以使用reduce函数。
reduce函数的输入是一个关联函数,该函数把两个 T 类型的参数映射为一个 T 类型的返回值。
之前写的合并逻辑是关联性的,所以我们可以把它作为reduce的输入,并应用在Array[NAStatCounter] 类型的集合上。
scala> val merged = nasRDD.reduce( (nas1, nas2) => {
| nas1.zip(nas2).map(a => a._1.merge(a._2)) })
merged: Array[NAStatCounter] = Array(stat(count: 5748125, mean: 0.712902, stdev: 0.388758, max: 1.000000, min: 0.000000)NAN: 1007, stat(count: 103698, mean: 0.900018, stdev: 0.271316, max: 1.000000, min: 0.000000)NAN: 5645434, …
length = 9
在reduce后得到的9个指标的统计值:
scala> merged.foreach(println)
stat(count: 5748125, mean: 0.712902, stdev: 0.388758, max: 1.000000, min: 0.000000)NAN: 1007
stat(count: 103698, mean: 0.900018, stdev: 0.271316, max: 1.000000, min: 0.000000)NAN: 5645434
stat(count: 5749132, mean: 0.315628, stdev: 0.334234, max: 1.000000, min: 0.000000)NAN: 0
stat(count: 2464, mean: 0.318413, stdev: 0.368492, max: 1.000000, min: 0.000000)NAN: 5746668
stat(count: 5749132, mean: 0.955001, stdev: 0.207301, max: 1.000000, min: 0.000000)NAN: 0
stat(count: 5748337, mean: 0.224465, stdev: 0.417230, max: 1.000000, min: 0.000000)NAN: 795
stat(count: 5748337, mean: 0.488855, stdev: 0.499876, max: 1.000000, min: 0.000000)NAN: 795
stat(count: 5748337, mean: 0.222749, stdev: 0.416091, max: 1.000000, min: 0.000000)NAN: 795
stat(count: 5736289, mean: 0.005529, stdev: 0.074149, max: 1.000000, min: 0.000000)NAN: 12843
我们把分析缺失值分析代码打包为一个函数,放入之前的 StatsWtihMissing.scala 里:
def StatsWithMissing(rdd: RDD[Array[Double]]): Array[NAStatCounter]={
val nastats = rdd.mapPartitions((iter: Iterator[Array[Double]]) => {
val nas: Array[NAStatCounter] = iter.next().map( d => NAStatCounter(d)) iter.foreach(arr => {
nas.zip(arr).foreach({ case (n, d) => n.add(d)}) })
Iterator(nas)
})
nastats.reduce((n1, n2) => { n1.zip(n2).map({case (a, b) => a.merge(b)}) })}
28. 变量选择与评分
有了StatsWithMissing 函数,我们就可以分析 parsed RDD 中匹配和不匹配记录的匹配分值数组的分布差异了:
scala> val statsm = StatsWithMissing(parsed.filter(_.matched).map(_.scores))
scala> val statsn = StatsWithMissing(parsed.filter(!_.matched).map(_.scores))
statsm 与 statsn 对应两个不同的数据子集,分别是匹配的与不匹配的分值数组的概要统计信息。
一个好的特征有两个属性:
1. 对匹配和不匹配记录,它的值往往差别很大(因此均值的差异也很大)
2. 在数据中出现的频率高,这样我们才能指望它在任何一对记录里都有值
我们将匹配与不匹配的数据做一个简单的差异分析:
scala> statsm.zip(statsn).map{ case(m, n) =>
| (m.missing + n.missing, m.stats.mean - n.stats.mean)
| }.foreach(println)
(1007,0.2854529057466858)
(5645434,0.09104268062279874)
(0,0.6838772482597569)
(5746668,0.8064147192926269)
(0,0.03240818525033462)
(795,0.7754423117834042)
(795,0.5109496938298719)
(795,0.7762059675300521)
(12843,0.9563812499852178)
通过观察评分结果,我们可以得到以下信息:
现在我们用一个简单的评分模型,该模型把记录对的相似度排序。相似度的计算为特征2、5、6、7 和 8 的值相加,这些特征明显是好特征。少数记录中这几个特征有缺失的情况,对于这些记录的相加结果我们以 0 代替NaN。
scala> def naz(d: Double) = if (Double.NaN.equals(d)) 0.0 else d
scala> case class Scored(md: MatchData, score: Double)
scala> val ct = parsed.map(md => {
| val score = Array(2, 5, 6, 7, 8).map( i => naz(md.scores(i))).sum
| Scored(md, score)
| })
scala> ct.filter(s => s.score >= 4.0).map(s => s.md.matched).countByValue()
res1: scala.collection.Map[Boolean,Long] = Map(true -> 20871, false -> 637)
scala> ct.filter(s => s.score >= 2.0).map(s => s.md.matched).countByValue()
res2: scala.collection.Map[Boolean,Long] = Map(true -> 20931, false -> 596414)
scala> ct.filter(s => s.score >= 4.0).map(s => s.md.matched).countByValue()
res1: scala.collection.Map[Boolean,Long] = Map(true -> 20871, false -> 637)
过滤阀值为4.0,意味着5个特征的平均值是0.8。我们过滤掉了几乎所有不匹配的记录,同时保留了超过90% 的匹配记录。
scala> ct.filter(s => s.score >= 2.0).map(s => s.md.matched).countByValue()
res2: scala.collection.Map[Boolean,Long] = Map(true –> 20931, false -> 596414)
较低的阈值 2.0,我们可以捕捉所有已知的匹配记录,但代价是误报率高
源数据:
(true,20931)
(false,5728201)
标签:miss 来源 .so 关联性 因此 取数 slice 目录 方便
原文地址:https://www.cnblogs.com/zackstang/p/9404381.html