标签:and sklearn 随机过程 相互 html 最大 并且 抽取 补丁
集成学习(Ensemble Learning)有时也被笼统地称作提升(Boosting)方法,广泛用于分类和回归任务。它最初的思想很简单:使用一些(不同的)方法改变原始训练样本的分布,从而构建多个不同的分类器,并将这些分类器线性组合得到一个更强大的分类器,来做最后的决策。也就是常说的“三个臭皮匠顶个诸葛亮”的想法。
集成学习的理论基础来自于Kearns和Valiant提出的基于PAC(probably approximately correct)的可学习性理论 ,PAC 定义了学习算法的强弱:
弱学习算法:识别错误率小于1/2(即准确率仅比随机猜测略高的算法)
强学习算法:识别准确率很高并能在多项式时间内完成的算法
对于集成学习,我们面临两个主要问题:
1.如何改变数据的分布或权重
2.如何将多个弱分类器组合成一个强分类器
集成方法通常分为两种:
平均方法,该方法的原理是构建多个独立的估计器,然后取它们的预测结果的平均。一般来说组合之后的估计器是会比单个估计器要好的,因为它的方差减小了。
示例: Bagging 方法 , 随机森林 , …
相比之下,在 boosting 方法 中,基估计器是依次构建的,并且每一个基估计器都尝试去减少组合估计器的偏差。这种方法主要目的是为了结合多个弱模型,使集成的模型更加强大。
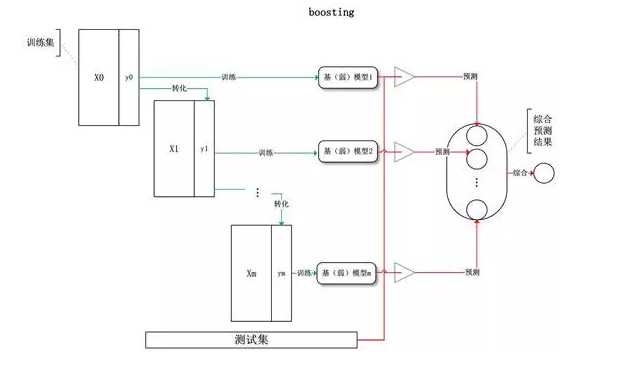
Boosting方法是一种典型的基于bootstrapping思想的应用,其特点是:每一次迭代时训练集的选择与前面各轮的学习结果有关,而且每次是通过更新各个样本权重的方式来改变数据分布。总结起来如下:
1.分步学习每个弱分类器,最终的强分类器由分步产生的分类器组合而成
2.根据每步学习到的分类器去改变各个样本的权重(被错分的样本权重加大,反之减小)
AdaBoost,是英文"Adaptive Boosting"(自适应增强)的缩写,由Yoav Freund和Robert Schapire在1995年提出。它的自适应在于:前一个基本分类器分错的样本会得到加强,加权后的全体样本再次被用来训练下一个基本分类器。同时,在每一轮中加入一个新的弱分类器,直到达到某个预定的足够小的错误率或达到预先指定的最大迭代次数。
具体说来,整个Adaboost 迭代算法就3步:
算法过程如下:

其中Zi是归一化因子,即分子的和,使得出的D为概率。
a因子的推导:

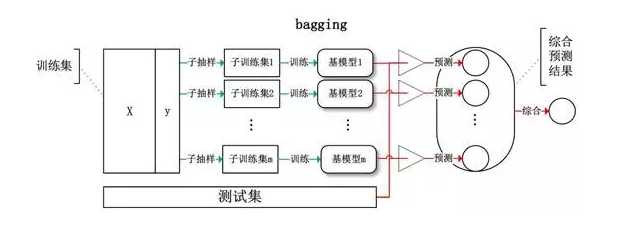
Bagging (bootstrap aggregating) 方法完全基于bootstrapping思想,即把训练集看做全体数据的子集,训练集对全体数据中某参数的估计等价于用训练集子采样获得的数据来估计训练集。其中,每一次迭代前,采用有放回的随机抽样来获取训练数据。这样做直接体现了bagging的一大特点:每次迭代不依赖之前建立的模型,即生成的各个弱模型之间没有关联,因此就可以彻底实现数据并行训练。这是bagging方法与上述boosting方法最大的区别。
对于一个样本,在一次含m个样本的训练集的随机采样,每次被抽到的概率是1/m。不被抽到的概率为1?1/m。如果m次采样都没有被抽到的概率是(1?1/m)mm。当m→∞时,(1?1/m)mm→1e?0.368。就是说,在bagging的每轮随机采样中,训练集中大约有36.8%的数据没有被采样集抽到。这大约36.8%的没有被采样到的数据,我们常常称之为袋外数据(Out Of Bag, OOB)。这些数据没有参与训练集模型的拟合,因此可作为验证集检验模型的效果。
和boosting方法一样,bagging方法常用的基本模型也是决策树和神经网络,而且基本模型越简单,往往最终的集成模型泛化能力越强,越不易发生过拟合。模型组合的方法也很简单,对于分类任务,一般采用多数投票;对于回归任务,则采用算术平均法。
bagging 方法有很多种,其主要区别在于随机抽取训练子集的方法不同:
Boosting利用前一轮迭代的误差率(或残差)进行拟合训练(相当于改变原始样本的权重),每轮的训练集分布依赖之前的训练结果,因而每轮模型只能顺序生成。主要关注降低偏差,因此Boosting能基于泛化性能很弱的分类器构建出很强的集成模型。
Bagging采取对原始样本有放回的均匀抽样方式获取每一次的数据来训练,每轮训练集相互独立,因而模型可以并行生成。主要关注降低方差,因此它在不剪枝的决策树、神经网络等弱模型上效果更好。
随机森林(Random Forest)算法由上世纪八十年代Breiman等人提出来,基本思想就是构造多棵相互独立的CART决策树,形成一个森林,利用这些决策树共同决策输出类别。随机森林算法秉承了bagging方法的思想,以构建单一决策树为基础,同时也是单一决策树算法的延伸和改进。
在整个随机森林算法的过程中,有两个随机过程:
1.输入数据是随机的:从全体训练数据中选取一部分来构建一棵决策树,并且是有放回的选取
2.每棵决策树的构建所需的特征是从全体特征中随机选取的
随机森林算法具体流程:
1.从原始训练数据中随机选取n个数据作为训练数据输入(通常n远小于全体训练数据N,这样就存在一部分“袋外数据”始终不被取到,它们可以直接用于测试误差(而无需单独的测试集或验证集)。
2.选取了要输入的训练数据后,开始构建决策树,具体方法是每一个结点从全体特征集M中选取m个特征进行构建(通常m远小于M)。
3.在构造每棵决策树时,选取基尼指数最小的特征来分裂节点构建决策树。决策树的其他结点都采取相同的分裂规则进行构建,直到该节点的所有训练样例都属于同一类或者达到树的最大深度。(该步骤与构建单一决策树相同)
4.重复第2步和第3步多次,每一次输入数据对应一颗决策树,这样就得到了一个随机森林,用于对预测数据进行决策。
5.对待预测数据进行预测时,多棵决策树同时进行决策,采用多数投票的方式产生最终决策结果。
随机森林的优点:
1.两个随机性的引入,使得随机森林抗噪声能力强,方差小泛化能力强,不易陷入过拟合(因此不需要剪枝)
2.易于高度并行训练,且训练速度快,适合处理大数据
3.由于可以随机选择决策树节点划分的特征,因此能够处理高维度(特征多)的数据,事先不用做特征选择;而且连续和离散数据均可,且无需归一化数据。
4.创建随机森林时,是对参数的无偏估计
5.训练后,可以给出各个特征对于输出结果的重要性排序,并且能够检测到特征间的相互影响
6.相对于boosting系列算法,实现简单
7.对部分特征缺失不敏感
8.由于随机森林对误差率是无偏估计,因此在算法中不需要再进行交叉验证或者设置单独的测试集来获取测试集上误差的无偏估计
随机森林的缺点:
对于取值划分比较多的特征,容易对随机森林的决策产生较大影响,从而影响拟合效果。
标签:and sklearn 随机过程 相互 html 最大 并且 抽取 补丁
原文地址:https://www.cnblogs.com/hotsnow/p/9404499.html