标签:地图 print 目的 和我 border path trace 朋友 今天
前几天就想写一个爬虫系列的文章,因为比较忙所以没有写(还不是因为懒),趁着现在屋里比较的凉爽,心也比较的静,总结下目前遇到的一些爬虫知识,本系列将从简单的爬虫开始说起,后会逐渐的提升难度,同时会对反爬手段做一个总结,以及用具体的事例来演示,不同的反爬现象和实现手段。
本系列侧重点是应用和实战,所以,对于软件的安装这些基本操作不做详细讲解,我这里认为你已经有了一定的python基础,所以对于python的安装一定会有一定的了解了,这里废话不多说让我们进入正题。
鉴于大多数人的系统是windows系统,所以这里的所有内容都是在Windows下进行的,另外推荐安装谷歌浏览器,使用语言python,版本3.6(低版本不能使用requests_html)。主要的爬虫模块requests_html。
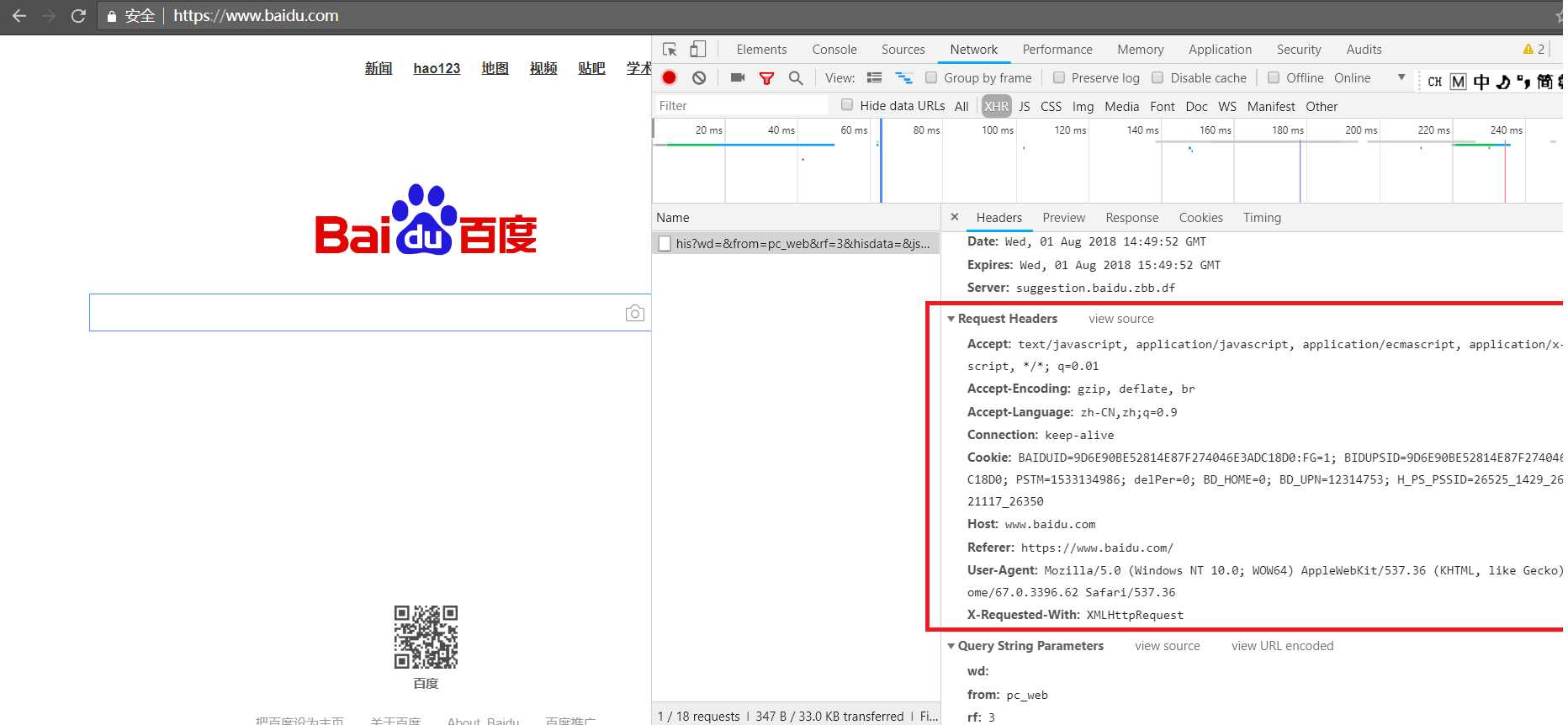
作为一个合格的爬虫,首先得有一个headers,如何理解headers,我们打开谷歌浏览器,然后F12,选择network选项卡,打开百度的首页,然后打开然后选择其中的一个链接,然后点击新弹出的窗口的headers,看到有一个‘Request Headers‘,我们看到下面红框的内容,这些由:组成的数据结构,共同构成了一个headers,在python中可以把这些字段作为一个字典传入。
下面我来看一个基本爬虫代码,爬取百度的导航栏文字内容。
1.导入requests_html模块。
from requests_html import HTMLSession
2.创建一给session对象,目的是维持一次完整的会话。
session=HTMLSession()
3.通过get方法访问网络
url=‘https://www.baidu.com‘
headers={‘User-Agent‘:‘Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.62 Safari/537.36‘}
req=session.get(url=url,headers=headers)
get方法需要传入两个参数,一个是url,一个是headers(字典类型)。一般的我们传入一个user_agent就可以愉快的使用了。(这里只是说一般的对于有先网站服务器还会监测headers的其他属性内容)。我们会获取一个response对象。
拓展:如果查看requests_html的源码会发现默认是给了几个headers属性的。
def default_headers():
"""
:rtype: requests.structures.CaseInsensitiveDict
"""
return CaseInsensitiveDict({
‘User-Agent‘: default_user_agent(), #这个就是一个随机的useragent
‘Accept-Encoding‘: ‘, ‘.join((‘gzip‘, ‘deflate‘)),#接收编码类型
‘Accept‘: ‘*/*‘,#接收文件类型
‘Connection‘: ‘keep-alive‘,#保持链接
})
4.获取网页返回的状态码
一般的我们把200状态码认为是响应成功(并不一定是你想要的结果,比如登陆失败有些也是200)。
其他常见的还有,404网页访问失败,500服务器拒绝访问,302和301作为网页的重定向。
if req.status_code==200:
print("ok")
5.获取正确的网页编码
因为每个页面的编码不同,可能导致在解析的时候出现乱码的情况,对此requests_html模块为我们提供了一个可以高准确率获取编码的方法,目前来看对于绝大对数html页面是没有问题的,所以可以放心使用。
req.encoding=req.apparent_encoding
6.查看获取html源码
此时我们已经获取了编码之后的对象了,如果我们需要查看获取的内容以及编码是否正确我们可以使用text属性来获取网页的源码,它是一个字符串格式的。
7.xpath表达式的使用
requets_html模块的一个好处就是集合了众多的网页解析模块比如,bs4,pyquery,lxml等,可以说相当的强大了,requests_html通过response的html属性调用xpath方法,来直接操作dom对象,通过观察我们获取百度导航栏的标题的xpath,代码我们可以这样写。
node_list=req.html.xpath("//div[@id=‘u1‘]/a/text()")
简单说下上面xpath表达式的含义,//从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。/表示从根节点选取。后面跟的ediv表示是div节点,中括号里面一般是做属性判断@id就是判断id属性然后取其值为ul的,后面紧跟的/a,表示上面div节点的下级所有含有a的节点,然后后面的text()是表示获取该节点的文本信息。
8.综合整理下上面的代码如下:
from requests_html import HTMLSession
from traceback import format_exc
class BaiDu():
def __init__(self):
self.session=HTMLSession()
self.url=‘https://www.baidu.com‘
self.headers={‘User-Agent‘:‘Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.62 Safari/537.36‘}
self.timeout=20
def gethtml(self):
try:
req=self.session.get(url=self.url,headers=self.headers,timeout=self.timeout)
if req.status_code==200:
req.encoding=req.apparent_encoding
title_info=self.parse_html(req)
return ‘ | ‘.join(title_info)
except:
print("出错了错误内容是",format_exc)
def parse_html(self,req):
node_list=req.html.xpath("//div[@id=‘u1‘]/a/text()")
return node_list
if __name__ == ‘__main__‘:
baidu=BaiDu()
title=baidu.gethtml()
print(title)
输出结果:
新闻 | hao123 | 地图 | 视频 | 贴吧 | 学术 | 登录 | 设置 | 更多产品
好了,今天的内容就到这,内容比较的简单,简单的说了下爬虫的基本思路,后面会一步步加大难度,如有任何问题和疑问欢迎留言,如果您喜欢我的文章不防动动小手,转发到朋友圈分享给更多的朋友。
标签:地图 print 目的 和我 border path trace 朋友 今天
原文地址:https://www.cnblogs.com/c-x-a/p/pyt.html