标签:possible col time 发送 Once bubuko one jmx str
前面几篇博客,我们依次介绍了local和remote的一些内容,其实再分析cluster就会简单很多,后面关于cluster的源码分析,能够省略的地方,就不再贴源码而是一句话带过了,如果有不理解的地方,希望多翻翻之前的博客。
在使用cluster时,配置文件中的akka.actor.provider值是cluster,所以ActorSystem对应的provider就是akka.cluster.ClusterActorRefProvider。
/**
* INTERNAL API
*
* The `ClusterActorRefProvider` will load the [[akka.cluster.Cluster]]
* extension, i.e. the cluster will automatically be started when
* the `ClusterActorRefProvider` is used.
*/
private[akka] class ClusterActorRefProvider(
_systemName: String,
_settings: ActorSystem.Settings,
_eventStream: EventStream,
_dynamicAccess: DynamicAccess) extends RemoteActorRefProvider(
_systemName, _settings, _eventStream, _dynamicAccess) {
override def init(system: ActorSystemImpl): Unit = {
super.init(system)
// initialize/load the Cluster extension
Cluster(system)
}
override protected def createRemoteWatcher(system: ActorSystemImpl): ActorRef = {
// make sure Cluster extension is initialized/loaded from init thread
Cluster(system)
import remoteSettings._
val failureDetector = createRemoteWatcherFailureDetector(system)
system.systemActorOf(ClusterRemoteWatcher.props(
failureDetector,
heartbeatInterval = WatchHeartBeatInterval,
unreachableReaperInterval = WatchUnreachableReaperInterval,
heartbeatExpectedResponseAfter = WatchHeartbeatExpectedResponseAfter), "remote-watcher")
}
/**
* Factory method to make it possible to override deployer in subclass
* Creates a new instance every time
*/
override protected def createDeployer: ClusterDeployer = new ClusterDeployer(settings, dynamicAccess)
}
上面是ClusterActorRefProvider的源码,就问你惊不惊喜意不意外,它就是简单的继承了RemoteActorRefProvider,然后重写了三个函数,好像跟remote差不多啊。那它关于cluster的功能是如何实现的呢?在init中有一行代码值得注意:Cluster(system)。Cluster是什么呢?
/**
* Cluster Extension Id and factory for creating Cluster extension.
*/
object Cluster extends ExtensionId[Cluster] with ExtensionIdProvider {
override def get(system: ActorSystem): Cluster = super.get(system)
override def lookup = Cluster
override def createExtension(system: ExtendedActorSystem): Cluster = new Cluster(system)
/**
* INTERNAL API
*/
private[cluster] final val isAssertInvariantsEnabled: Boolean =
System.getProperty("akka.cluster.assert", "off").toLowerCase match {
case "on" | "true" ? true
case _ ? false
}
}
很显然Cluster是Akka的一个扩展,Cluster(system)会创建一个Cluster类的实例,由于Cluster类的源码过多,此处只贴出了它的UML图。
之前的博客分析过Akka的扩展机制,如果读过该文章,就一定知道Cluster是如何初始化的。因为Cluster的createExtension就是new了一个Cluster,所以所有的初始化过程都在Cluster类的主构造函数中,主构造函数是啥?Cluster中除了字段定义、方法定义,其他的代码块都是。其实Cluster的这种实现,我是很不喜欢的,毕竟把类的初始化过程和定义柔和到一块,是不便于分析的,没办法,还得硬着头皮上啊。
/** * This module is responsible cluster membership information. Changes to the cluster * information is retrieved through [[#subscribe]]. Commands to operate the cluster is * available through methods in this class, such as [[#join]], [[#down]] and [[#leave]]. * * Each cluster [[Member]] is identified by its [[akka.actor.Address]], and * the cluster address of this actor system is [[#selfAddress]]. A member also has a status; * initially [[MemberStatus]] `Joining` followed by [[MemberStatus]] `Up`. */ class Cluster(val system: ExtendedActorSystem) extends Extension
首先分析Cluster这个扩展的定义,官方注释说的也很清楚,这个模块就是负责集群的成员信息的,当然还可以对集群进行操作,比如加入集群、关闭集群、离开集群等。集群中的每个成员被它的Address唯一标志,每个成员也有一个状态,及其对应的生命周期。
下面我们把Cluster主构造函数中所有的代码块摘录出来。
class Cluster(val system: ExtendedActorSystem) extends Extension {
logInfo("Starting up...")
system.registerOnTermination(shutdown())
if (JmxEnabled)
clusterJmx = {
val jmx = new ClusterJmx(this, log)
jmx.createMBean()
Some(jmx)
}
logInfo("Started up successfully")
}
摘出来之后就清晰多了,抛开日志打印,一共两段代码,调用system.registerOnTermination注册shutdown函数,JmxEnabled为true就初始化clusterJmx。JmxEnabled默认就是true。其实这样看来,cluster主构造函数也没有太多的逻辑。当然了字段初始化的过程,也可以认为是主构造函数的一部分,字段代码这里就不一一分析,用到的时候再具体分析。
分析到这里,希望读者有一点认识:cluster模式是基于remote模式创建的,它额外使用Cluster这个Extension来管理集群的状态、成员信息、成员生命周期等。下面会基于Cluster的demo来分析,cluster是如何实现成员管理等功能的。
To enable cluster capabilities in your Akka project you should, at a minimum, add the Remoting settings, but with
cluster. Theakka.cluster.seed-nodesshould normally also be added to yourapplication.conffile.
上面是官网关于cluster的说明,很简单,除了cluster的相关配置,remote相关的配置也要设置(akka.actor.provider必须是cluster),这也说明cluster是基于remote的,还有一个akka.cluster.seed-nodes需要配置。seed-nodes比较容易理解,其实就是集群的种子节点,通过种子节点就可以加入到指定的集群了。当然了加入集群还可以通过编程的方式实现,这里不做介绍。
akka {
actor {
provider = "cluster"
}
remote {
log-remote-lifecycle-events = off
netty.tcp {
hostname = "127.0.0.1"
port = 0
}
}
cluster {
seed-nodes = [
"akka.tcp://ClusterSystem@127.0.0.1:2551",
"akka.tcp://ClusterSystem@127.0.0.1:2552"]
}
}
上面是官网demo中的配置,可以看出,非常简单。
class SimpleClusterListener extends Actor with ActorLogging {
val cluster = Cluster(context.system)
// subscribe to cluster changes, re-subscribe when restart
override def preStart(): Unit = {
cluster.subscribe(self, initialStateMode = InitialStateAsEvents,
classOf[MemberEvent], classOf[UnreachableMember])
}
override def postStop(): Unit = cluster.unsubscribe(self)
def receive = {
case MemberUp(member) ?
log.info("Member is Up: {}", member.address)
case UnreachableMember(member) ?
log.info("Member detected as unreachable: {}", member)
case MemberRemoved(member, previousStatus) ?
log.info(
"Member is Removed: {} after {}",
member.address, previousStatus)
case _: MemberEvent ? // ignore
}
}
上面是SimpleClusterListener的源码,这是一个普通的actor,没有任何多余的继承信息。当然它覆盖了preStart方法,这个方法调用了cluster的subscribe方法。
/**
* Subscribe to one or more cluster domain events.
* The `to` classes can be [[akka.cluster.ClusterEvent.ClusterDomainEvent]]
* or subclasses.
*
* If `initialStateMode` is `ClusterEvent.InitialStateAsEvents` the events corresponding
* to the current state will be sent to the subscriber to mimic what you would
* have seen if you were listening to the events when they occurred in the past.
*
* If `initialStateMode` is `ClusterEvent.InitialStateAsSnapshot` a snapshot of
* [[akka.cluster.ClusterEvent.CurrentClusterState]] will be sent to the subscriber as the
* first message.
*
* Note that for large clusters it is more efficient to use `InitialStateAsSnapshot`.
*/
@varargs def subscribe(subscriber: ActorRef, initialStateMode: SubscriptionInitialStateMode, to: Class[_]*): Unit = {
require(to.length > 0, "at least one `ClusterDomainEvent` class is required")
require(
to.forall(classOf[ClusterDomainEvent].isAssignableFrom),
s"subscribe to `akka.cluster.ClusterEvent.ClusterDomainEvent` or subclasses, was [${to.map(_.getName).mkString(", ")}]")
clusterCore ! InternalClusterAction.Subscribe(subscriber, initialStateMode, to.toSet)
}
很简单,SimpleClusterListener这个actor在启动的时候调用cluster相关函数,监听对应的集群事件,而subscribe方法只不过把监听消息InternalClusterAction.Subscribe发送给了clusterCore这个ActorRef。
private[cluster] val clusterCore: ActorRef = {
implicit val timeout = system.settings.CreationTimeout
try {
Await.result((clusterDaemons ? InternalClusterAction.GetClusterCoreRef).mapTo[ActorRef], timeout.duration)
} catch {
case NonFatal(e) ?
log.error(e, "Failed to startup Cluster. You can try to increase ‘akka.actor.creation-timeout‘.")
shutdown()
// don‘t re-throw, that would cause the extension to be re-recreated
// from shutdown() or other places, which may result in
// InvalidActorNameException: actor name [cluster] is not unique
system.deadLetters
}
}
clusterCore是通过向clusterDaemons发送InternalClusterAction.GetClusterCoreRef消息获取的。
// create supervisor for daemons under path "/system/cluster"
private val clusterDaemons: ActorRef = {
system.systemActorOf(Props(classOf[ClusterDaemon], settings, joinConfigCompatChecker).
withDispatcher(UseDispatcher).withDeploy(Deploy.local), name = "cluster")
}
clusterDaemons是一个ActorRef,对应的actor是ClusterDaemon,也就是说cluster在启动时创建了一个actor,有该actor负责什么呢?
/**
* INTERNAL API.
*
* Supervisor managing the different Cluster daemons.
*/
@InternalApi
private[cluster] final class ClusterDaemon(settings: ClusterSettings, joinConfigCompatChecker: JoinConfigCompatChecker) extends Actor with ActorLogging
with RequiresMessageQueue[UnboundedMessageQueueSemantics] {
import InternalClusterAction._
// Important - don‘t use Cluster(context.system) in constructor because that would
// cause deadlock. The Cluster extension is currently being created and is waiting
// for response from GetClusterCoreRef in its constructor.
// Child actors are therefore created when GetClusterCoreRef is received
var coreSupervisor: Option[ActorRef] = None
val clusterShutdown = Promise[Done]()
val coordShutdown = CoordinatedShutdown(context.system)
coordShutdown.addTask(CoordinatedShutdown.PhaseClusterLeave, "leave") {
val sys = context.system
() ?
if (Cluster(sys).isTerminated || Cluster(sys).selfMember.status == Down)
Future.successful(Done)
else {
implicit val timeout = Timeout(coordShutdown.timeout(CoordinatedShutdown.PhaseClusterLeave))
self.ask(CoordinatedShutdownLeave.LeaveReq).mapTo[Done]
}
}
coordShutdown.addTask(CoordinatedShutdown.PhaseClusterShutdown, "wait-shutdown") { () ?
clusterShutdown.future
}
override def postStop(): Unit = {
clusterShutdown.trySuccess(Done)
if (Cluster(context.system).settings.RunCoordinatedShutdownWhenDown) {
// if it was stopped due to leaving CoordinatedShutdown was started earlier
coordShutdown.run(CoordinatedShutdown.ClusterDowningReason)
}
}
def createChildren(): Unit = {
coreSupervisor = Some(context.actorOf(Props(classOf[ClusterCoreSupervisor], joinConfigCompatChecker).
withDispatcher(context.props.dispatcher), name = "core"))
context.actorOf(Props[ClusterHeartbeatReceiver].
withDispatcher(context.props.dispatcher), name = "heartbeatReceiver")
}
def receive = {
case msg: GetClusterCoreRef.type ?
if (coreSupervisor.isEmpty)
createChildren()
coreSupervisor.foreach(_ forward msg)
case AddOnMemberUpListener(code) ?
context.actorOf(Props(classOf[OnMemberStatusChangedListener], code, Up).withDeploy(Deploy.local))
case AddOnMemberRemovedListener(code) ?
context.actorOf(Props(classOf[OnMemberStatusChangedListener], code, Removed).withDeploy(Deploy.local))
case CoordinatedShutdownLeave.LeaveReq ?
val ref = context.actorOf(CoordinatedShutdownLeave.props().withDispatcher(context.props.dispatcher))
// forward the ask request
ref.forward(CoordinatedShutdownLeave.LeaveReq)
}
}
官方注释说这是一个监督者,用来管理各个集群daemon实例。它收到GetClusterCoreRef后,会调用createChildren创建两个actor:ClusterCoreSupervisor、ClusterHeartbeatReceiver。然后把GetClusterCoreRef消息转发给他们。
/**
* INTERNAL API.
*
* ClusterCoreDaemon and ClusterDomainEventPublisher can‘t be restarted because the state
* would be obsolete. Shutdown the member if any those actors crashed.
*/
@InternalApi
private[cluster] final class ClusterCoreSupervisor(joinConfigCompatChecker: JoinConfigCompatChecker) extends Actor with ActorLogging
with RequiresMessageQueue[UnboundedMessageQueueSemantics] {
// Important - don‘t use Cluster(context.system) in constructor because that would
// cause deadlock. The Cluster extension is currently being created and is waiting
// for response from GetClusterCoreRef in its constructor.
// Child actors are therefore created when GetClusterCoreRef is received
var coreDaemon: Option[ActorRef] = None
def createChildren(): Unit = {
val publisher = context.actorOf(Props[ClusterDomainEventPublisher].
withDispatcher(context.props.dispatcher), name = "publisher")
coreDaemon = Some(context.watch(context.actorOf(Props(classOf[ClusterCoreDaemon], publisher, joinConfigCompatChecker).
withDispatcher(context.props.dispatcher), name = "daemon")))
}
override val supervisorStrategy =
OneForOneStrategy() {
case NonFatal(e) ?
log.error(e, "Cluster node [{}] crashed, [{}] - shutting down...", Cluster(context.system).selfAddress, e.getMessage)
self ! PoisonPill
Stop
}
override def postStop(): Unit = Cluster(context.system).shutdown()
def receive = {
case InternalClusterAction.GetClusterCoreRef ?
if (coreDaemon.isEmpty)
createChildren()
coreDaemon.foreach(sender() ! _)
}
}
首先ClusterCoreSupervisor这个actor收到GetClusterCoreRef后,又通过createChildren创建了两个actor:ClusterDomainEventPublisher、ClusterCoreDaemon。然后把ClusterCoreDaemon的ActorRef返回。
ClusterHeartbeatReceiver源码不再分析,他就是一个心跳检测的actor,功能简单独立。
分析到这里,我们知道了Cluster类中的clusterCore其实是一个ClusterCoreDaemon实例的ActorRef。ClusterCoreDaemon源码太长,这里就不粘贴了,读者只需要知道它是用来处理所有与集群有关的消息的就可以了。但它的preStart函数需要我们关注一下。
override def preStart(): Unit = {
context.system.eventStream.subscribe(self, classOf[QuarantinedEvent])
cluster.downingProvider.downingActorProps.foreach { props ?
val propsWithDispatcher =
if (props.dispatcher == Deploy.NoDispatcherGiven) props.withDispatcher(context.props.dispatcher)
else props
context.actorOf(propsWithDispatcher, name = "downingProvider")
}
if (seedNodes.isEmpty)
logInfo("No seed-nodes configured, manual cluster join required")
else
self ! JoinSeedNodes(seedNodes)
}
最后一个if语句比较关键,它首先判断当前seedNode是不是为空,为空则打印一条日志,仅做提醒;如果不为空,则给自己发一个JoinSeedNodes消息。这条日志也验证了我们可以通过编程的方式加入某个集群中。
通过上下文分析,我们找到了seedNodes的最终定义。
val SeedNodes: immutable.IndexedSeq[Address] =
immutableSeq(cc.getStringList("seed-nodes")).map { case AddressFromURIString(address) ? address }.toVector
很明显,SeedNodes就是一个Address列表。
def uninitialized: Actor.Receive = ({
case InitJoin ?
logInfo("Received InitJoin message from [{}], but this node is not initialized yet", sender())
sender() ! InitJoinNack(selfAddress)
case ClusterUserAction.JoinTo(address) ?
join(address)
case JoinSeedNodes(newSeedNodes) ?
resetJoinSeedNodesDeadline()
joinSeedNodes(newSeedNodes)
case msg: SubscriptionMessage ?
publisher forward msg
case Welcome(from, gossip) ?
welcome(from.address, from, gossip)
case _: Tick ?
if (joinSeedNodesDeadline.exists(_.isOverdue))
joinSeedNodesWasUnsuccessful()
}: Actor.Receive).orElse(receiveExitingCompleted)
根据以上定义,可知收到JoinSeedNodes后调用了两个函数:resetJoinSeedNodesDeadline、joinSeedNodes。resetJoinSeedNodesDeadline不再具体分析,其意义可参考shutdown-after-unsuccessful-join-seed-nodes这个配置的说明。
# The joining of given seed nodes will by default be retried indefinitely until
# a successful join. That process can be aborted if unsuccessful by defining this
# timeout. When aborted it will run CoordinatedShutdown, which by default will
# terminate the ActorSystem. CoordinatedShutdown can also be configured to exit
# the JVM. It is useful to define this timeout if the seed-nodes are assembled
# dynamically and a restart with new seed-nodes should be tried after unsuccessful
# attempts.
shutdown-after-unsuccessful-join-seed-nodes = off
joinSeedNodes方法源码如下。
def joinSeedNodes(newSeedNodes: immutable.IndexedSeq[Address]): Unit = {
if (newSeedNodes.nonEmpty) {
stopSeedNodeProcess()
seedNodes = newSeedNodes // keep them for retry
seedNodeProcess =
if (newSeedNodes == immutable.IndexedSeq(selfAddress)) {
self ! ClusterUserAction.JoinTo(selfAddress)
None
} else {
// use unique name of this actor, stopSeedNodeProcess doesn‘t wait for termination
seedNodeProcessCounter += 1
if (newSeedNodes.head == selfAddress) {
Some(context.actorOf(Props(classOf[FirstSeedNodeProcess], newSeedNodes, joinConfigCompatChecker).
withDispatcher(UseDispatcher), name = "firstSeedNodeProcess-" + seedNodeProcessCounter))
} else {
Some(context.actorOf(Props(classOf[JoinSeedNodeProcess], newSeedNodes, joinConfigCompatChecker).
withDispatcher(UseDispatcher), name = "joinSeedNodeProcess-" + seedNodeProcessCounter))
}
}
}
}
上面代码显示,如果配置的种子节点只有一个,而且就是当前节点,则给self发一个ClusterUserAction.JoinTo消息;否则会判断,配置种子节点的第一个address是不是当前地址,如果是则创建FirstSeedNodeProcess,否则创建JoinSeedNodeProcess。
首先分析配置的种子节点只有一个,且就是当前节点的情况,当前节点收到ClusterUserAction.JoinTo(selfAddress)消息后,会调用join函数。
/**
* Try to join this cluster node with the node specified by `address`.
* It‘s only allowed to join from an empty state, i.e. when not already a member.
* A `Join(selfUniqueAddress)` command is sent to the node to join,
* which will reply with a `Welcome` message.
*/
def join(address: Address): Unit = {
if (address.protocol != selfAddress.protocol)
log.warning(
"Trying to join member with wrong protocol, but was ignored, expected [{}] but was [{}]",
selfAddress.protocol, address.protocol)
else if (address.system != selfAddress.system)
log.warning(
"Trying to join member with wrong ActorSystem name, but was ignored, expected [{}] but was [{}]",
selfAddress.system, address.system)
else {
require(latestGossip.members.isEmpty, "Join can only be done from empty state")
// to support manual join when joining to seed nodes is stuck (no seed nodes available)
stopSeedNodeProcess()
if (address == selfAddress) {
becomeInitialized()
joining(selfUniqueAddress, cluster.selfRoles)
} else {
val joinDeadline = RetryUnsuccessfulJoinAfter match {
case d: FiniteDuration ? Some(Deadline.now + d)
case _ ? None
}
context.become(tryingToJoin(address, joinDeadline))
clusterCore(address) ! Join(selfUniqueAddress, cluster.selfRoles)
}
}
}
由于就是当前节点,所以会执行becomeInitialized()、joining(selfUniqueAddress, cluster.selfRoles)两个函数。
def becomeInitialized(): Unit = {
// start heartbeatSender here, and not in constructor to make sure that
// heartbeating doesn‘t start before Welcome is received
val internalHeartbeatSenderProps = Props(new ClusterHeartbeatSender()).withDispatcher(UseDispatcher)
context.actorOf(internalHeartbeatSenderProps, name = "heartbeatSender")
val externalHeartbeatProps = Props(new CrossDcHeartbeatSender()).withDispatcher(UseDispatcher)
context.actorOf(externalHeartbeatProps, name = "crossDcHeartbeatSender")
// make sure that join process is stopped
stopSeedNodeProcess()
joinSeedNodesDeadline = None
context.become(initialized)
}
becomeInitialized这个函数创建了两个心跳发送器,一个是集群内,一个是跨数据中心的,最后修改当前行为函数为initialized,意味着初始化完成。
// check by address without uid to make sure that node with same host:port is not allowed
// to join until previous node with that host:port has been removed from the cluster
localMembers.find(_.address == joiningNode.address) match {
case Some(m) if m.uniqueAddress == joiningNode ?
// node retried join attempt, probably due to lost Welcome message
logInfo("Existing member [{}] is joining again.", m)
if (joiningNode != selfUniqueAddress)
sender() ! Welcome(selfUniqueAddress, latestGossip)
case Some(m) ?
// node restarted, same host:port as existing member, but with different uid
// safe to down and later remove existing member
// new node will retry join
logInfo("New incarnation of existing member [{}] is trying to join. " +
"Existing will be removed from the cluster and then new member will be allowed to join.", m)
if (m.status != Down) {
// we can confirm it as terminated/unreachable immediately
val newReachability = latestGossip.overview.reachability.terminated(selfUniqueAddress, m.uniqueAddress)
val newOverview = latestGossip.overview.copy(reachability = newReachability)
val newGossip = latestGossip.copy(overview = newOverview)
updateLatestGossip(newGossip)
downing(m.address)
}
case None ?
// remove the node from the failure detector
failureDetector.remove(joiningNode.address)
crossDcFailureDetector.remove(joiningNode.address)
// add joining node as Joining
// add self in case someone else joins before self has joined (Set discards duplicates)
val newMembers = localMembers + Member(joiningNode, roles) + Member(selfUniqueAddress, cluster.selfRoles)
val newGossip = latestGossip copy (members = newMembers)
updateLatestGossip(newGossip)
logInfo("Node [{}] is JOINING, roles [{}]", joiningNode.address, roles.mkString(", "))
if (joiningNode == selfUniqueAddress) {
if (localMembers.isEmpty)
leaderActions() // important for deterministic oldest when bootstrapping
} else
sender() ! Welcome(selfUniqueAddress, latestGossip)
publishMembershipState()
}
由于joining源码太长,只贴上面部分代码,很显然会命中case None,第一次加入集群吗,肯定是None。updateLatestGossip这个函数不再分析,它应该是用来更新与Gossip协议相关的状态的。由于joiningNode == selfUniqueAddress且localMembers是空,因为此时还没有成员,所以会执行leaderActions()。leaderActions方法暂时也不分析,它应该就是计算当前集群leader的,很显然当前种子节点就是leader。
然后我们分析当前配置不止一个种子节点的情况,此时会分两种情况,第一个节点启东时会创建FirstSeedNodeProcess,其余节点启动时会创建JoinSeedNodeProcess。
先来看FirstSeedNodeProcess,在主构造函数中有一段代码:self ! JoinSeedNode。也就是给自己发送了一个JoinSeedNode消息。
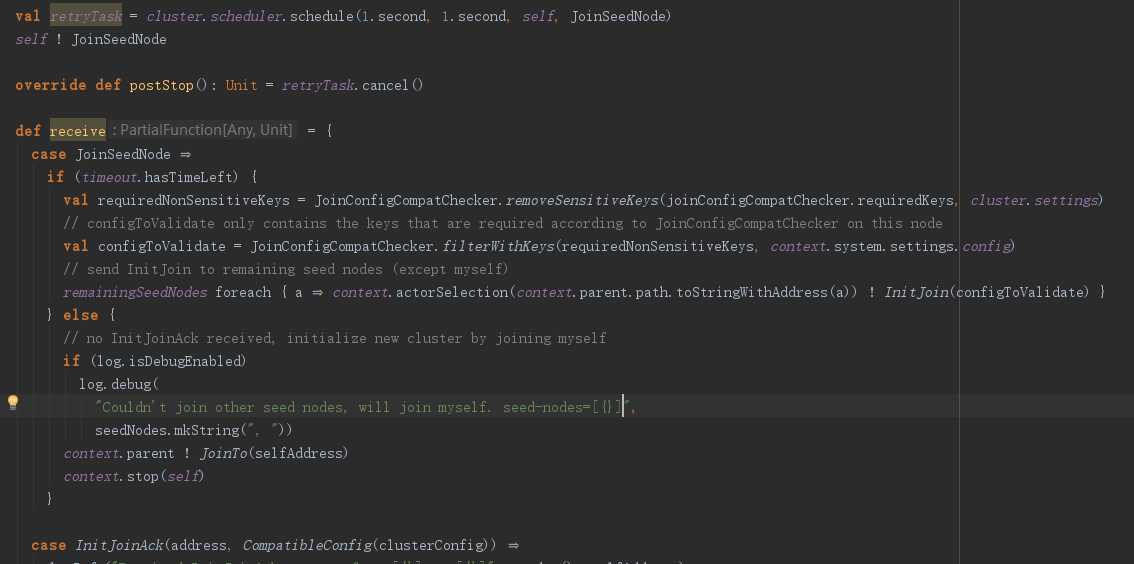
收到JoinSeedNode消息后,给剩余的节点发送了InitJoin消息,FirstSeedNodeProcess就算处理结束了。
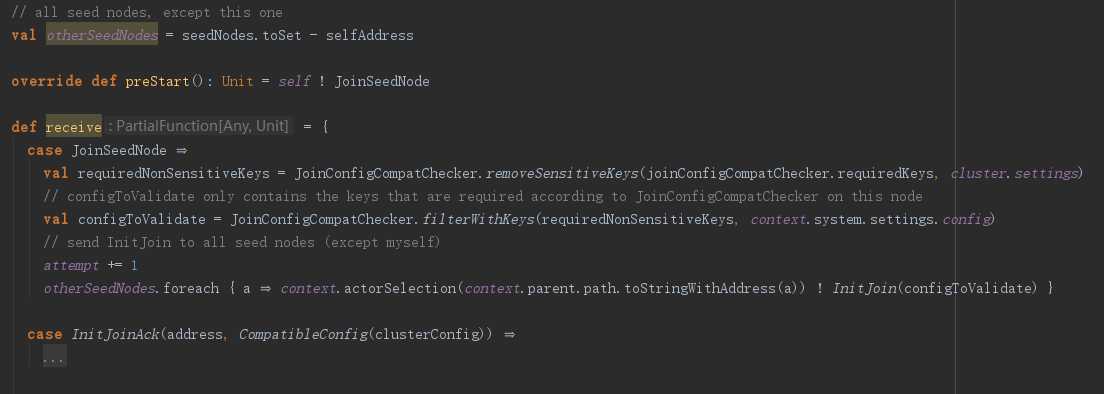
我们来看JoinSeedNodeProcess,这个actor在preStart时给自己发了一个JoinSeedNode消息,收到消息后,会给其他种子节点发送InitJoin消息,当然了,其他节点也会返回InitJoinAck消息。
请特别注意,上面两个actor所说的其他种子节点,是指其他的ActorSystem系统的ClusterCoreDaemon这个actor。那么收到InitJoin消息的节点ClusterCoreDaemon是如何处理的呢?
def uninitialized: Actor.Receive = ({
case InitJoin ?
logInfo("Received InitJoin message from [{}], but this node is not initialized yet", sender())
sender() ! InitJoinNack(selfAddress)
case ClusterUserAction.JoinTo(address) ?
join(address)
case JoinSeedNodes(newSeedNodes) ?
resetJoinSeedNodesDeadline()
joinSeedNodes(newSeedNodes)
case msg: SubscriptionMessage ?
publisher forward msg
case Welcome(from, gossip) ?
welcome(from.address, from, gossip)
case _: Tick ?
if (joinSeedNodesDeadline.exists(_.isOverdue))
joinSeedNodesWasUnsuccessful()
}: Actor.Receive).orElse(receiveExitingCompleted)
其实此时,对于其他节点都是出于uninitialized状态的,收到InitJoin时,会发送InitJoinNack消息。
case InitJoinNack(address) ?
logInfo("Received InitJoinNack message from [{}] to [{}]", sender(), selfAddress)
remainingSeedNodes -= address
if (remainingSeedNodes.isEmpty) {
// initialize new cluster by joining myself when nacks from all other seed nodes
context.parent ! JoinTo(selfAddress)
context.stop(self)
}
对于FirstSeedNodeProcess,收到所有其他节点的InitJoinNack消息后会给parent也就是ClusterCoreDaemon发送JoinTo(selfAddress)消息,然后stop掉自己。如果Deadline.now + cluster.settings.SeedNodeTimeout指定的时间内没有收到其他节点的InitJoinNack消息,同样给ClusterCoreDaemon发送JoinTo(selfAddress)消息,然后stop掉自己。
对于JoinSeedNodeProcess收到InitJoinNack消息是不作任何处理的。
case InitJoinNack(_) ? // that seed was uninitialized
case ReceiveTimeout ?
if (attempt >= 2)
log.warning(
"Couldn‘t join seed nodes after [{}] attempts, will try again. seed-nodes=[{}]",
attempt, seedNodes.filterNot(_ == selfAddress).mkString(", "))
// no InitJoinAck received, try again
self ! JoinSeedNode
那么此时FirstSeedNodeProcess所在节点ClusterCoreDaemon对JoinTo消息的处理就很重要了。
很显然第一个种子节点的ClusterCoreDaemon还没有初始化,对JoinTo消息的处理,前面已经分析过,就是调用join(address),而address就是selfAddress,即当前节点成功加入集群,并且状态变成已初始化,即当前集群已经有一个节点了,就是第一个种子节点。那么JoinSeedNodeProcess怎么办呢,好像没人管他了呢。
幸好,它的主构造函数设置了timeout
context.setReceiveTimeout(SeedNodeTimeout)
上面代码显示,收到timeout消息后,又给自己发送了JoinSeedNode消息,重新加入其它节点,此时第一个种子节点已经完成初始化。
def initialized: Actor.Receive = ({
case msg: GossipEnvelope ? receiveGossip(msg)
case msg: GossipStatus ? receiveGossipStatus(msg)
case GossipTick ? gossipTick()
case GossipSpeedupTick ? gossipSpeedupTick()
case ReapUnreachableTick ? reapUnreachableMembers()
case LeaderActionsTick ? leaderActions()
case PublishStatsTick ? publishInternalStats()
case InitJoin(joiningNodeConfig) ?
logInfo("Received InitJoin message from [{}] to [{}]", sender(), selfAddress)
initJoin(joiningNodeConfig)
case Join(node, roles) ? joining(node, roles)
case ClusterUserAction.Down(address) ? downing(address)
case ClusterUserAction.Leave(address) ? leaving(address)
case SendGossipTo(address) ? sendGossipTo(address)
case msg: SubscriptionMessage ? publisher forward msg
case QuarantinedEvent(address, uid) ? quarantined(UniqueAddress(address, uid))
case ClusterUserAction.JoinTo(address) ?
logInfo("Trying to join [{}] when already part of a cluster, ignoring", address)
case JoinSeedNodes(nodes) ?
logInfo(
"Trying to join seed nodes [{}] when already part of a cluster, ignoring",
nodes.mkString(", "))
case ExitingConfirmed(address) ? receiveExitingConfirmed(address)
}: Actor.Receive).orElse(receiveExitingCompleted)
初始化的ClusterCoreDaemon收到InitJoin消息后,会去调用initJoin方法。
def initJoin(joiningNodeConfig: Config): Unit = {
val selfStatus = latestGossip.member(selfUniqueAddress).status
if (removeUnreachableWithMemberStatus.contains(selfStatus)) {
// prevents a Down and Exiting node from being used for joining
logInfo("Sending InitJoinNack message from node [{}] to [{}]", selfAddress, sender())
sender() ! InitJoinNack(selfAddress)
} else {
logInfo("Sending InitJoinAck message from node [{}] to [{}]", selfAddress, sender())
// run config compatibility check using config provided by
// joining node and current (full) config on cluster side
val configWithoutSensitiveKeys = {
val allowedConfigPaths = JoinConfigCompatChecker.removeSensitiveKeys(context.system.settings.config, cluster.settings)
// build a stripped down config instead where sensitive config paths are removed
// we don‘t want any check to happen on those keys
JoinConfigCompatChecker.filterWithKeys(allowedConfigPaths, context.system.settings.config)
}
joinConfigCompatChecker.check(joiningNodeConfig, configWithoutSensitiveKeys) match {
case Valid ?
val nonSensitiveKeys = JoinConfigCompatChecker.removeSensitiveKeys(joiningNodeConfig, cluster.settings)
// Send back to joining node a subset of current configuration
// containing the keys initially sent by the joining node minus
// any sensitive keys as defined by this node configuration
val clusterConfig = JoinConfigCompatChecker.filterWithKeys(nonSensitiveKeys, context.system.settings.config)
sender() ! InitJoinAck(selfAddress, CompatibleConfig(clusterConfig))
case Invalid(messages) ?
// messages are only logged on the cluster side
log.warning("Found incompatible settings when [{}] tried to join: {}", sender().path.address, messages.mkString(", "))
sender() ! InitJoinAck(selfAddress, IncompatibleConfig)
}
}
}
其实InitJoin也就是把其他节点的配置与当前节点的配置做了兼容性测试,然后发送InitJoinAck作为InitJoin的应答,同时包含兼容性结果。然后种子actor(JoinSeedNodeProcess)收到应答后,给parent发送JoinTo(address)消息,将行为函数改成done,其实也就是在timeout消息后再stop(self),而不是立即stop。此时JoinSeedNodeProcess所在的ClusterCoreDaemon还没有完成初始化,所以会调用join(address),只不过这里的address是第一个初始化的种子节点的地址。
val joinDeadline = RetryUnsuccessfulJoinAfter match {
case d: FiniteDuration ? Some(Deadline.now + d)
case _ ? None
}
context.become(tryingToJoin(address, joinDeadline))
clusterCore(address) ! Join(selfUniqueAddress, cluster.selfRoles)
所以join函数会执行以上代码段。修改当前行为函数为tryingToJoin,然后给对应的address(也就是第一个种子节点)发送Join消息。由于第一个种子节点已经完成初始化,所以会命中initialized函数中的一下分支
case Join(node, roles) ? joining(node, roles)
上面代码中的node对于第一个种子节点来说是JoinSeedNodeProcess所在节点的地址,也就是远程节点地址,所以joining方法中下面的代码会走else代码块。
if (joiningNode == selfUniqueAddress) {
if (localMembers.isEmpty)
leaderActions() // important for deterministic oldest when bootstrapping
} else
sender() ! Welcome(selfUniqueAddress, latestGossip)
也就是给sender发送一个Welcome消息,由于JoinSeedNodeProcess所在节点的ClusterCoreDaemon行为函数还是tryingToJoin。
def tryingToJoin(joinWith: Address, deadline: Option[Deadline]): Actor.Receive = ({
case Welcome(from, gossip) ?
welcome(joinWith, from, gossip)
case InitJoin ?
logInfo("Received InitJoin message from [{}], but this node is not a member yet", sender())
sender() ! InitJoinNack(selfAddress)
case ClusterUserAction.JoinTo(address) ?
becomeUninitialized()
join(address)
case JoinSeedNodes(newSeedNodes) ?
resetJoinSeedNodesDeadline()
becomeUninitialized()
joinSeedNodes(newSeedNodes)
case msg: SubscriptionMessage ? publisher forward msg
case _: Tick ?
if (joinSeedNodesDeadline.exists(_.isOverdue))
joinSeedNodesWasUnsuccessful()
else if (deadline.exists(_.isOverdue)) {
// join attempt failed, retry
becomeUninitialized()
if (seedNodes.nonEmpty) joinSeedNodes(seedNodes)
else join(joinWith)
}
}: Actor.Receive).orElse(receiveExitingCompleted)
收到消息后调用了welcome方法。
**
* Accept reply from Join request.
*/
def welcome(joinWith: Address, from: UniqueAddress, gossip: Gossip): Unit = {
require(latestGossip.members.isEmpty, "Join can only be done from empty state")
if (joinWith != from.address)
logInfo("Ignoring welcome from [{}] when trying to join with [{}]", from.address, joinWith)
else {
membershipState = membershipState.copy(latestGossip = gossip).seen()
logInfo("Welcome from [{}]", from.address)
assertLatestGossip()
publishMembershipState()
if (from != selfUniqueAddress)
gossipTo(from, sender())
becomeInitialized()
}
}
简单点来说上述代码的公共就是更新gossip协议相关的数据,然后调用becomeInitialized完成初始化,并修改行为函数为initialized,结束初始化过程。
这样,所有的种子节点都加入了集群,其他所有非种子节点,都会按照第二个种子节点的方法(也就是通过JoinSeedNodeProcess)加入集群。至此,节点加入集群的过程就分析清楚了,但还要一些细节没有研究,比如gossip协议是怎样实现的,种子节点restart之后如何重新加入集群,非种子节点restart如何加入集群。
那么我们就可以分析clusterCore对InternalClusterAction.Subscribe的处理了。
case msg: SubscriptionMessage ? publisher forward msg
因为当前ClusterCoreDaemon已经完成了初始化,所以会命中initialized函数的上面的case,其实就是简单的把消息转发给了publisher,而publisher又是啥呢?根据创建的上下文publisher是ClusterDomainEventPublisher这个actor
def receive = {
case PublishChanges(newState) ? publishChanges(newState)
case currentStats: CurrentInternalStats ? publishInternalStats(currentStats)
case SendCurrentClusterState(receiver) ? sendCurrentClusterState(receiver)
case Subscribe(subscriber, initMode, to) ? subscribe(subscriber, initMode, to)
case Unsubscribe(subscriber, to) ? unsubscribe(subscriber, to)
case PublishEvent(event) ? publish(event)
}
ClusterDomainEventPublisher这个actor其实就是保存当前集群中的各成员节点信息和状态的,当然这些状态是通过gossip协议之后发布的。收到对应的Subscribe消息后,会把当前节点状态发送给订阅者。当然这里有两个模式,一个是把当前集群成员状态一次性发出去另一个是把各个集群成员状态分别发送出去,其实可以理解为批量与单条的区别。
不管如何,在preStart调用cluster.subscribe的Actor,都会受到集群成员状态的信息。不过读者需要注意,集群成员状态,只是各个节点host、port、角色等信息,并不是某一个特定actor的信息。那读者要问了,我仅仅知道集群中成员节点的host/port信息有啥用呢?我要跟集群中某个actor通信啊。嗯,你说的有道理,我之前也是这么想的。但再想想就不对了,既然你都知道了集群中所有节点的host、port、角色信息了,肯定能通过这些信息构造ActorPath传给actorSelection给远程节点任意actor发消息啊!!!
下面我们来分析一下在配置中没有种子节点信息的情况下,如何加入集群。首先,肯定不会报错,前面分析过,只是打印了一条日志而已。
val cluster = Cluster(system) val list: List[Address] = ??? //your method to dynamically get seed nodes cluster.joinSeedNodes(list)
官方也说明了如何编程的方式加入集群,是不是很简单,就是调用了joinSeedNodes方法。
/**
* Join the specified seed nodes without defining them in config.
* Especially useful from tests when Addresses are unknown before startup time.
*
* An actor system can only join a cluster once. Additional attempts will be ignored.
* When it has successfully joined it must be restarted to be able to join another
* cluster or to join the same cluster again.
*/
def joinSeedNodes(seedNodes: immutable.Seq[Address]): Unit =
clusterCore ! InternalClusterAction.JoinSeedNodes(seedNodes.toVector.map(fillLocal))
其实就是给clusterCore发送了JoinSeedNodes消息,还记得ClusterCoreDaemon在preStart发的是什么消息么?嗯,没错,就是这个消息。
那cluster.joinSeedNodes应该在哪里调用呢?其实吧,cluster这个变量只会初始化一次,你在哪里调用都可以,main方法中,某个actor的主构造函数中,某个actor的preStart中。不过,我一般都在ActorSystem创建完成后紧接着调用,
val system = ActorSystem("ClusterSystem", config)
val cluster = Cluster(system)
val list: List[Address] = ??? //your method to dynamically get seed nodes
cluster.joinSeedNodes(list)
cluster.joinSeedNodes(list)执行完毕后,就可以创建你自己的actor了,actor在preStart订阅成员信息的相关状态就可以了。
怎么样,这样分析下来,cluster是不是也很简单呢?当然了,还有很多其他细节没有分析,比如Gossip协议、成员的生命周期什么的。
标签:possible col time 发送 Once bubuko one jmx str
原文地址:https://www.cnblogs.com/gabry/p/9403260.html