标签:模型 之间 测试数据 避免 parse image 向量 sub 性能
2018-1-26
虽然我们不断追求更好的模型泛化力,但是因为未知数据无法预测,所以又期望模型可以充分利用训练数据,避免欠拟合。这就要求在增加模型复杂度、提高在可观测数据上的性能表现得同时,又需要兼顾模型的泛化力,防止发生过拟合的情况。为了平衡这两难的选择,通常采用两种模型正则化的方法:L1范数正则化与L2范数正则化。
正则化的目的:提高模型在未知测试数据上的泛化力,避免参数过拟合。
正则化常见方法:在原模型优化目标的基础上,增加对参数的惩罚项。
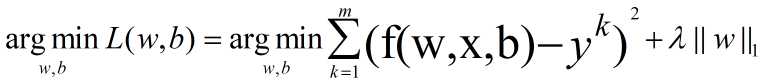
这种正则化方法结果会让参数向量的许多元素趋向于0,使得大部分特征失去对优化目标的贡献。这种让有效特征变得稀疏(Sparse)的L1正则化模型,通常被称为Lasso。
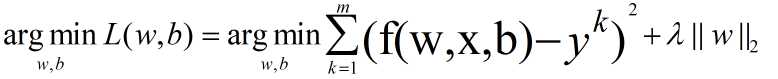
为了使新优化目标最小化,这种正则化方法的结果会让参数向量中的大部分元素都变得很小,压制了参数之间的差异性。这种压制参数之间的差异性的L2正则化模型,通常被称为Ridge。
标签:模型 之间 测试数据 避免 parse image 向量 sub 性能
原文地址:https://www.cnblogs.com/HongjianChen/p/8361822.html