标签:apach 包含 代码 继承 并行 乱序 大型 one 选择
在这个实例里我们使用简单的数据集,里面包含多条数据,每条数据由姓名、年龄、性别和成绩组成。实例要求是按照如下规则归档用户。
1.找出年龄小于20岁中男生和女生的最大分数
2.找出20岁到50岁男生和女生的最大分数
3.找出50岁以上的男生和女生的最大分数
样例输入:
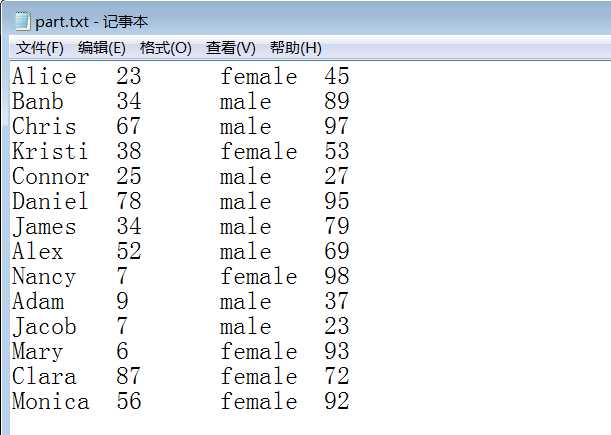
样例输出:
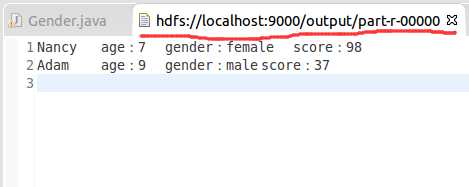
1.年龄小于20岁中男生和女生的最大分数
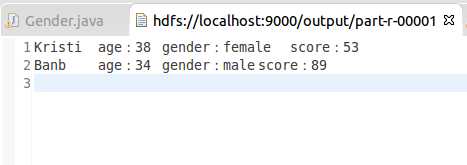
2.20岁到50岁男生和女生的最大分数
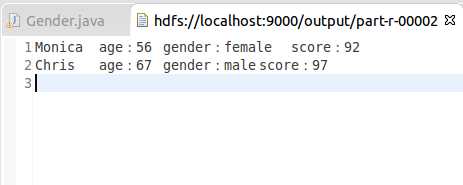
3.50岁以上的男生和女生的最大分数
基于实例需求,我们通过以下几步完成:第一步,编写Mapper类,按需求将数据集解析为key=gender,value=name+age+score,然后输出。第二步,编写Partitioner类,按年龄段,将结果指定给不同的Reduce执行。第三步,编写Reduce类,分别统计出男女学生的最高分。
得到map产生的记录后,他们该分配给哪些reducer来处理呢?hadoop默认是根据散列值来派发,但是实际中,这并不能很高效或者按照我们要求的去执行任务。例如,经过partition处理后,一个节点的reducer分配到了20条记录,另一个却分配到了10W万条,试想,这种情况效率如何。又或者,我们想要处理后得到的文件按照一定的规律进行输出,假设有两个reducer,我们想要最终结果中part-00000中存储的是”h”开头的记录的结果,part-00001中存储其他开头的结果,这些默认的partitioner是做不到的。所以需要我们自己定制partition来选择reducer。自定义partitioner很简单,只要自定义一个类,并且继承Partitioner类,重写其getPartition方法就好了,在使用的时候通过调用Job的setPartitionerClass指定一下即可。
如何使用mapreduce来做全排序?最简单的方法就是使用一个partition,因为一个partition对应一个reduce的task,然而reduce的输入本来就是对key有序的,所以很自然地就产生了一个全排序文件。但是这种方法在处理大型文件时效率极低,因为一台机器必须处理所有输出文件,从而完全丧失了mapreduce所提供的并行架构的优势。
如果是分多个partition呢,则只要确保partition是有序的就行了。首先创建一系列排好序的文件;其次,串联这些文件(类似于归并排序);最后得到一个全局有序的文件。比如有1000个1-10000的数据,跑10个ruduce任务,如果进行partition的时候,能够将在1-1000中数据的分配到第一个reduce中,1001-2000的数据分配到第二个reduce中,以此类推。即第n个reduce所分配到的数据全部大于第n-1个reduce中的数据。这样,每个reduce出来之后都是有序的了,我们只要concat所有的输出文件,变成一个大的文件,就都是有序的了。
这时候可能会有一个疑问,虽然各个reduce的数据是按照区间排列好的,但是每个reduce里面的数据是乱序的啊?当然不会,不要忘了排序是MapReduce的天然特性 — 在数据达到reducer之前,mapreduce框架已经对这些数据按key排序了。
但是这里又有另外一个问题,就是在定义每个partition的边界的时候,可能会导致每个partition上分配到的记录数相差很大,这样数据最多的partition就会拖慢整个系统。我们期望的是每个partition上分配的数据量基本相同,hadoop提供了采样器帮我们预估整个边界,以使数据的分配尽量平均。
在Hadoop中,patition我们可以用TotalOrderPartitioner替换默认的分区,然后将采样的结果传给他,就可以实现我们想要的分区。在采样时,可以使用hadoop的几种采样工具,如RandomSampler,InputSampler,IntervalSampler。
程序代码如下:
1 import java.io.IOException; 2 3 import org.apache.hadoop.conf.Configuration; 4 import org.apache.hadoop.fs.Path; 5 import org.apache.hadoop.io.LongWritable; 6 import org.apache.hadoop.io.Text; 7 import org.apache.hadoop.mapreduce.Job; 8 import org.apache.hadoop.mapreduce.Mapper; 9 import org.apache.hadoop.mapreduce.Partitioner; 10 import org.apache.hadoop.mapreduce.Reducer; 11 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 12 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 13 import org.apache.hadoop.util.GenericOptionsParser; 14 15 16 public class Gender { 17 18 private static String spiltChar = "\t"; // 字段分隔符 19 20 public static class GenderMapper extends Mapper<LongWritable, Text, Text, Text>{ 21 22 // 调用map解析一行数据,该行的数据存储在value参数中,然后根据\t分隔符,解析出姓名,年龄,性别和成绩 23 @Override 24 protected void map(LongWritable key, Text value,Mapper<LongWritable, Text, Text, Text>.Context context) 25 throws IOException, InterruptedException { 26 // super.map(key, value, context); 27 String [] tokens = value.toString().split(spiltChar); 28 String gender = tokens[2]; 29 String nameAgeScore = tokens[0]+spiltChar+tokens[1]+spiltChar+tokens[3]; 30 // 输出 key=gender value=name+age+score 31 context.write(new Text(gender), new Text(nameAgeScore)); 32 } 33 } 34 35 // 合并 Mapper 输出结果 36 public static class GenderCombiner extends Reducer<Text, Text, Text, Text>{ 37 @Override 38 protected void reduce(Text key, Iterable<Text> values,Reducer<Text, Text, Text, Text>.Context context) 39 throws IOException, InterruptedException { 40 // super.reduce(arg0, arg1, arg2); 41 int maxScore = Integer.MIN_VALUE; 42 int score = 0; 43 String name = " "; 44 String age = " "; 45 for(Text val:values){ 46 String [] valTokens = val.toString().split(spiltChar); 47 score = Integer.parseInt(valTokens[2]); 48 if(score>maxScore){ 49 name = valTokens[0]; 50 age = valTokens[1]; 51 maxScore = score; 52 } 53 } 54 context.write(key, new Text(name + spiltChar + age + spiltChar + maxScore)); 55 } 56 } 57 58 // 根据age年龄段将map输出结果均匀分布在reduce 上 59 public static class GenderPartitioner extends Partitioner<Text, Text>{ 60 @Override 61 public int getPartition(Text key, Text value, int numReduceTasks) { 62 String [] nameAgeScore = value.toString().split(spiltChar); 63 int age = Integer.parseInt(nameAgeScore[1]); 64 65 // 默认指定分区0 66 if (numReduceTasks == 0) { 67 return 0; 68 } 69 // 年龄小于等于20,指定分区0 70 if (age <= 20) { 71 return 0; 72 }else if (age <= 50) { // 年龄大于20,小于等于50,指定分区1 73 return 1 % numReduceTasks; 74 }else { // 剩余年龄指定分区2 75 return 2 % numReduceTasks; 76 } 77 } 78 } 79 80 // 统计出不同性别的最高分 81 public static class GenderReducer extends Reducer<Text, Text, Text, Text>{ 82 @Override 83 protected void reduce(Text key, Iterable<Text> values,Reducer<Text, Text, Text, Text>.Context context) 84 throws IOException, InterruptedException { 85 // super.reduce(arg0, arg1, arg2); 86 int maxScore = Integer.MIN_VALUE; 87 int score = 0; 88 String name = " "; 89 String age = " "; 90 String gender = " "; 91 92 // 根据key,迭代value集合,求出最高分 93 for(Text val:values){ 94 String[] valTokens = val.toString().split(spiltChar); 95 score = Integer.parseInt(valTokens[2]); 96 if (score > maxScore) { 97 name = valTokens[0]; 98 age = valTokens[1]; 99 gender = key.toString(); 100 maxScore = score; 101 } 102 } 103 context.write(new Text(name), new Text("age:" + age + spiltChar + "gender:" + gender + spiltChar + "score:" + maxScore)); 104 } 105 } 106 107 public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { 108 Configuration conf = new Configuration(); 109 String[] otherArgs = new GenericOptionsParser(conf,args).getRemainingArgs(); 110 if(otherArgs.length!=2){ 111 System.out.println("Usage:wordcount <in> <out>"); 112 System.exit(2); 113 } 114 Job job = new Job(conf,"Gender"); 115 job.setJarByClass(Gender.class); 116 117 job.setMapperClass(GenderMapper.class); 118 job.setReducerClass(GenderReducer.class); 119 job.setMapOutputKeyClass(Text.class); 120 job.setMapOutputValueClass(Text.class); 121 job.setOutputKeyClass(Text.class); 122 job.setOutputValueClass(Text.class); 123 124 job.setCombinerClass(GenderCombiner.class); 125 job.setPartitionerClass(GenderPartitioner.class); 126 job.setNumReduceTasks(3); // reduce个数设置为3 127 128 FileInputFormat.addInputPath(job,new Path(args[0])); 129 FileOutputFormat.setOutputPath(job, new Path(args[1])); 130 System.exit(job.waitForCompletion(true)?0:1); 131 } 132 133 }
标签:apach 包含 代码 继承 并行 乱序 大型 one 选择
原文地址:https://www.cnblogs.com/xiaoyh/p/9412921.html