标签:https fine 要求 color ict syn malloc ted inf
? 使用Jacobi 迭代求泊松方程的数值解
● 使用 data 构件,强行要求 u0 仅拷入和拷出 GPU 各一次,u1 仅拷入GPU 一次
1 #include <stdio.h> 2 #include <stdlib.h> 3 #include <math.h> 4 #include <openacc.h> 5 6 #if defined(_WIN32) || defined(_WIN64) 7 #include <C:\Program Files (x86)\Windows Kits\10\Include\10.0.10150.0\ucrt\sys\timeb.h> 8 #define gettime(a) _ftime(a) 9 #define usec(t1,t2) ((((t2).time - (t1).time) * 1000 + (t2).millitm - (t1).millitm)) 10 typedef struct _timeb timestruct; 11 #else 12 #include <sys/time.h> 13 #define gettime(a) gettimeofday(a, NULL) 14 #define usec(t1,t2) (((t2).tv_sec - (t1).tv_sec) * 1000 + ((t2).tv_usec - (t1).tv_usec)/1000) 15 typedef struct timeval timestruct; 16 #endif 17 18 #define ROW 8191 19 #define COL 1023 20 21 inline float uval(float x, float y) 22 { 23 return x * x + y * y; 24 } 25 26 int main() 27 { 28 const float width = 2.0, height = 1.0, hx = height / ROW, hy = width / COL, hx2 = hx * hx, hy2 = hy * hy; 29 const float fij = -4.0f; 30 const float maxIter = 100, errtol = 0.0f; 31 const int COLp1 = COL + 1; 32 const float c1 = hx2 * hy2 * fij, c2 = 1.0f / (2.0 * (hx2 + hy2)); 33 float *restrict u0 = (float *)malloc(sizeof(float)*(ROW + 1) * COLp1); 34 float *restrict u1 = (float *)malloc(sizeof(float)*(ROW + 1) * COLp1); 35 36 // 初始化 37 int ix, jy; 38 for (ix = 0; ix <= ROW; ix++) 39 { 40 u0[ix * COLp1 + 0] = u1[ix * COLp1 + 0] = uval(ix * hx, 0.0f); 41 u0[ix * COLp1 + COL] = u1[ix * COLp1 + COL] = uval(ix * hx, COL * hy); 42 } 43 for (jy = 0; jy <= COL; jy++) 44 { 45 u0[jy] = u1[jy] = uval(0.0f, jy * hy); 46 u0[ROW * COLp1 + jy] = u1[ROW * COLp1 + jy] = uval(ROW * hx, jy * hy); 47 } 48 for (ix = 1; ix < ROW; ix++) 49 { 50 for (jy = 1; jy < COL; jy++) 51 u0[ix * COLp1 + jy] = 0.0f; 52 } 53 54 // 计算 55 timestruct t1, t2; 56 float /*uerr, temp,*/ *tempp; 57 acc_init(4); 58 gettime(&t1); 59 #pragma acc data copy(u0[0:(ROW + 1) * COLp1]) copyin(u1[0:(ROW + 1) * COLp1]) // 在 迭代的外侧添加 data 构件,跨迭代(内核)构造数据空间 60 { 61 for (int iter = 1; iter < maxIter; iter++) 62 { 63 #pragma acc kernels present(u0[0:((ROW + 1) * COLp1)], u1[0:((ROW + 1) * COLp1)]) // 每次调用内核时声明 u0 和 u1 已经存在,不要再拷贝 64 { 65 //uerr = 0.0f; 66 #pragma acc loop independent 67 for (ix = 1; ix < ROW; ix++) 68 { 69 for (jy = 1; jy < COL; jy++) 70 { 71 u1[ix*COLp1 + jy] = c2 * 72 ( 73 hy2 * (u0[(ix - 1) * COLp1 + jy] + u0[(ix + 1) * COLp1 + jy]) + 74 hx2 * (u0[ix * COLp1 + (jy - 1)] + u0[ix * COLp1 + (jy + 1)]) + 75 c1 76 ); 77 //temp = fabs(u0[ix * COLp1 + jy] - u1[ix * COLp1 + jy]); 78 //uerr = max(temp, uerr); 79 } 80 } 81 } 82 //printf("\niter = %d, uerr = %e\n", iter, uerr); 83 //if (uerr < errtol) 84 // break; 85 tempp = u0, u0 = u1, u1 = tempp; // 代码块层数比较多,注意摆放位置时每次迭代的末尾 86 } 87 } 88 gettime(&t2); 89 acc_shutdown(4); 90 printf("\nElapsed time: %13ld ms.\n", usec(t1, t2)); 91 free(u0); 92 free(u1); 93 //getchar(); 94 return 0; 95 }
● 输出结果,在 Windows 里运行结果如下,在 WSL 里运行时间为 959 ms
1 D:\Code\OpenACC\OpenACCProject\OpenACCProject>pgcc -acc -Minfo main.c -o main_acc.exe 2 main: 3 50, Memory zero idiom, loop replaced by call to __c_mzero4 4 59, Generating copy(u0[:COLp1*8192]) 5 Generating copyin(u1[:COLp1*8192]) 6 61, Generating present(u1[:COLp1*8192],u0[:COLp1*8192]) 7 67, Loop is parallelizable 8 69, Loop is parallelizable 9 Accelerator kernel generated 10 Generating Tesla code 11 67, #pragma acc loop gang, vector(4) /* blockIdx.y threadIdx.y */ 12 69, #pragma acc loop gang, vector(32) /* blockIdx.x threadIdx.x */ 13 69, FMA (fused multiply-add) instruction(s) generated 14 uval: 15 23, FMA (fused multiply-add) instruction(s) generated 16 17 D:\Code\OpenACC\OpenACCProject\OpenACCProject>main_acc.exe 18 launch CUDA kernel file=D:\Code\OpenACC\OpenACCProject\OpenACCProject\main.c function=main 19 line=69 device=0 threadid=1 num_gangs=32768 num_workers=4 vector_length=32 grid=32x1024 block=32x4 20 launch CUDA kernel file=D:\Code\OpenACC\OpenACCProject\OpenACCProject\main.c function=main 21 line=69 device=0 threadid=1 num_gangs=32768 num_workers=4 vector_length=32 grid=32x1024 block=32x4 22 23 ... // 省略 97 行 24 25 launch CUDA kernel file=D:\Code\OpenACC\OpenACCProject\OpenACCProject\main.c function=main 26 line=69 device=0 threadid=1 num_gangs=32768 num_workers=4 vector_length=32 grid=32x1024 block=32x4 27 28 Elapsed time: 78 ms. 29 PGI: "acc_shutdown" not detected, performance results might be incomplete. 30 Please add the call "acc_shutdown(acc_device_nvidia)" to the end of your application to ensure that the performance results are complete. 31 32 Accelerator Kernel Timing data 33 D:\Code\OpenACC\OpenACCProject\OpenACCProject\main.c 34 main NVIDIA devicenum=0 35 time(us): 7,704 36 59: data region reached 2 times 37 59: data copyin transfers: 4 38 device time(us): total=5,141 max=1,288 min=1,284 avg=1,285 39 88: data copyout transfers: 3 40 device time(us): total=2,563 max=1,278 min=7 avg=854 41 61: data region reached 198 times 42 63: compute region reached 99 times 43 69: kernel launched 99 times 44 grid: [32x1024] block: [32x4] 45 elapsed time(us): total=48,000 max=1000 min=0 avg=484
● 在 Nvvp 中的结果,非常清晰了
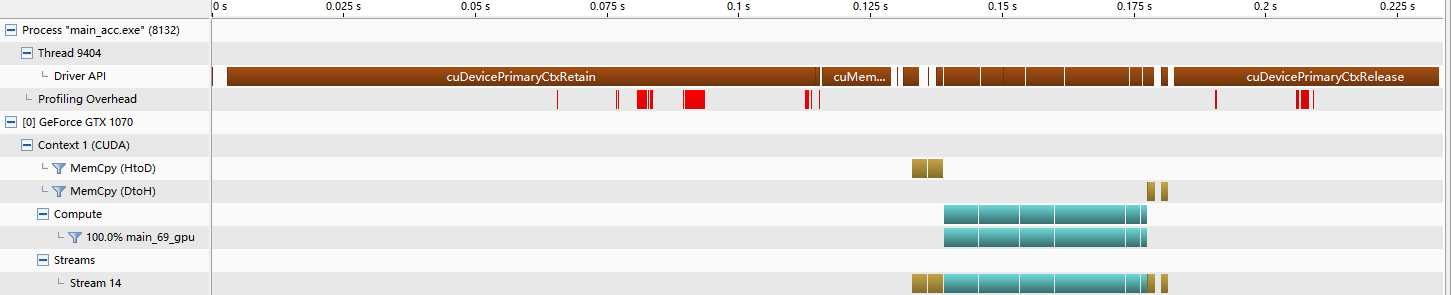
● 将 tempp 放到了更里一层循环,产生如下的运行时错误,关于这个错误 715,参考https://stackoverflow.com/questions/41366915/openacc-create-data-while-running-inside-a-kernels,大意是关于内存泄露
1 D:\Code\OpenACC\OpenACCProject\OpenACCProject>pgcc -acc main.c -o main_acc.exe -Minfo 2 main: 3 0, Accelerator kernel generated 4 Generating Tesla code 5 50, Memory zero idiom, loop replaced by call to __c_mzero4 6 59, Generating copyin(u1[:COLp1*8192]) 7 Generating copy(u0[:COLp1*8192]) 8 67, Loop is parallelizable 9 69, Loop is parallelizable 10 Accelerator kernel generated 11 Generating Tesla code 12 67, #pragma acc loop gang, vector(4) /* blockIdx.y threadIdx.y */ 13 69, #pragma acc loop gang, vector(32) /* blockIdx.x threadIdx.x */ 14 69, FMA (fused multiply-add) instruction(s) generated 15 80, Accelerator serial kernel generated 16 uval: 17 23, FMA (fused multiply-add) instruction(s) generated 18 19 D:\Code\OpenACC\OpenACCProject\OpenACCProject>main_acc.exe 20 launch CUDA kernel file=D:\Code\OpenACC\OpenACCProject\OpenACCProject\main.c function=main 21 line=69 device=0 threadid=1 num_gangs=32768 num_workers=4 vector_length=32 grid=32x1024 block=32x4 22 launch CUDA kernel file=D:\Code\OpenACC\OpenACCProject\OpenACCProject\main.c function=main 23 line=80 device=0 threadid=1 num_gangs=1 num_workers=1 vector_length=1 grid=1 block=1 24 call to cuStreamSynchronize returned error 715: Illegal instruction 25 26 call to cuMemFreeHost returned error 715: Illegal instruction
● 另外,将 PGI_ACC_TIME 打开会强行分析运行时间,而不报运行时错误。如上错误的基础上,把 PGI_ACC_TIME 打开会获得如下的结果:
D:\Code\OpenACC\OpenACCProject\OpenACCProject>set PGI_ACC_TIME=1 D:\Code\OpenACC\OpenACCProject\OpenACCProject>main_acc.exe launch CUDA kernel file=D:\Code\OpenACC\OpenACCProject\OpenACCProject\main.c function=main line=69 device=0 threadid=1 num_gangs=32768 num_workers=4 vector_length=32 grid=32x1024 block=32x4 PGI: "acc_shutdown" not detected, performance results might be incomplete. Please add the call "acc_shutdown(acc_device_nvidia)" to the end of your application to ensure that the performance results are complete. Accelerator Kernel Timing data D:\Code\OpenACC\OpenACCProject\OpenACCProject\main.c main NVIDIA devicenum=0 time(us): 5,129 59: data region reached 1 time 59: data copyin transfers: 4 device time(us): total=5,129 max=1,286 min=1,280 avg=1,282 63: compute region reached 1 time 69: kernel launched 1 time grid: [32x1024] block: [32x4] device time(us): total=0 max=0 min=0 avg=0
OpenACC 书上的范例代码(Jacobi 迭代),part 3
标签:https fine 要求 color ict syn malloc ted inf
原文地址:https://www.cnblogs.com/cuancuancuanhao/p/9417047.html