标签:示例 系统文件 mem 搜索 定时 oms 模块 throttle 知识
本章内容
垃圾回收器是什么,它如何工作,如何定位垃圾回收器产生的问题。
如何控制ElasticSearch的I/O操作数量。
预热器加快搜索速度的原理及其示例。
什么是热点线程以及如何获取热点线程的列表。
在诊断集群和节点故障时应使用哪个ElasticSearch API
JVM的内存空间分为以下区域:
Java对象的生命周期和垃圾回收
为了考察垃圾回收器的工作过程,我们来看一个简单Java对象的生命周期。
Java程序将新创建的对象放置在年轻代的Eden区。如果年轻代执行下一次垃圾回收时,这个对象仍然存活(一般来说,它不是一次性对象,Java程序仍然需要用到它),那么它会被挪到Survivor区(先进人Survivor 0区,如果经过年轻代的下一轮垃圾回收仍然存活,则它会被挪到Survivor 1区)。
当对象在Survivor 1区存活一段时间后,会被挪到年老代,成为年老代对象的一员,且从此以后,年轻代的垃圾回收不再对它起作用,因而该对象会一直在年老代中生存下去直到Java程序不再使用它。在这种情况下,如果它不再使用,那么在下次做全局垃圾回收时,会把它从堆空间中移除,并回收空间给新对象使用。
基于上面的介绍,我们可以断定(实质上也是如此):截至目前Java还在使用分代的垃圾回收机制;对象经历垃圾回收次数越多,越容易往年老代迁移。因此我们可以说,存在两种垃圾回收器在并行运行:年轻代垃圾回收器(也称为次垃圾回收器)和年老代垃圾回收器(也称为主垃圾回收器)。
打开垃圾回收日志
monitor.jvm.gc.ParNew.warn:1000ms
monitor.jvm.gc.ParNew.info:700ms
monitor.jvm.gc.ParNew.debug:400ms
monitor.jvm.gc.ConcurrentMarkSweep.warn:10s
monitor.jvm.gc.ConcurrentMarkSweep.info:5s
monitor.jvm.gc.ConcurrentMarkSweep.debug:2s使用jstat
使用jstat检查垃圾回收器的工作状况,只需输人如下简单命令:
jstat -gcutil 123456 2000 1000其中,-gcutil开关用来告知jstat监控垃圾回收器的工作状态;123456用于标识ElasticSearch所在的JVM ; 2000表示抽样间隔,单位是毫秒;1000表示的抽样数。
接下来,我们看一个关于jstat命令输出的示例:
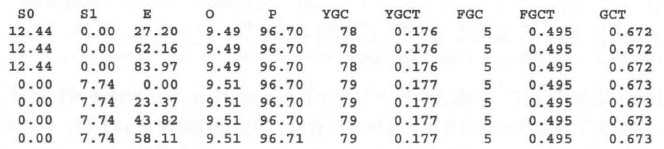
首先阐述一下每一列的含义:
如果你遇到以下情况,ElasticSearch运行不正常,或者S0, S1, E列的值达到100%,并且垃圾回收工作对这些堆空间不起作用,那么原因可能是:
年轻代太小了,你需要把它调大一些(当然,前提是拥有足够的物理内存);内存出问题了,比如说因为一些资源没有释放占用的内存而导致内存泄露。还有一种情况,如果年老代使用率达到100%且垃圾回收器多次尝试仍无法释放它的空间,这大概意味着没有足够的堆空间让ElasticSearch节点正常运作了。此时,如果你不想改变索引结构,就只能通过增大运行ElasticSearch的JVM的堆空间来解决了。
生成Memory Dump(jmap)
JVM还拥有把堆空间转储到文件的能力。Java允许我们获取特定时间点的一个内存快照,并通过分析快照的存储内容,从而发现问题。
jmap -dump:file=heap.dump 123456123456表示需要转储的Java进程号。-dump:file=heap.dump指定转储的目标文件为heap.dump。
内存交换是一个把内存中的页( page)写人外存磁盘(Linux系统中指swap分区)的过程,且发生在物理内存不足时,或者操作系统由于某些原因需要把部分内存数据写人磁盘时。
使用ElasticSearch时,我们要确保它的内存空间不会被换出。可以想象一下,如果让ElasticSearch的部分内存交换到磁盘中,紧接着读取这块被换出的数据,就会对查询和索引的性能造成负面影响。因此ElasticSearch允许我们关闭针对它的内存交换,具体通过设置elasticsearch.yml的bootstrap.mlockall为true来实现。
除了前面的设置,我们还需要确保JVM的堆大小固定。要做到这一点,我们需要设置Xmx和Xms参数为相同值(或者设置ES MAX MEM和ES MIN MEM为相同值)。仍需谨记,要有足够的物理内存来支持以上设置。
此时运行ElasticSearch,可以看到如下日志:
Unknown mlockall error 0
这个错误意味着内存锁定未起作用,因而我们还需修改两个系统文件(需要系统管理员权限)。在做修改之前,了段定运行ElasticSearch服务的用户为elasticsearch.
首先修改/etc/security/limits.conf文件,添加如下两行记录:
elasticsearch - nofile 64000
elasticsearch - memlock unlimited然后修改/etc/pam.d/common-session文件,添加一行:
session required pam_limits.so重新用elasticsearch用户登录后,再次运行ElasticSearch,就不会看到mlockall error的日志了。
索引合并的过程是异步的,从Lucene的角度看是不会干扰索引和查询过程 的。然而,这很可能会出现问题,因为合并操作非常消耗I/O,需要先读取旧索引段,然后合并写人新索引段中。如果在此同时进行查询和索引,那么I/O子系统的负荷会非常大,这个问题在那些I/O速度较慢的系统中表现得尤为突出。这就是I/O节流的切入点。我们可以控制ElasticSearch使用的I/O量。
在节点级和索引级都可以配置I/O节流。这意味着你可以分别配置节点和索引的资源 使用量。
节流类型
在节点级配置节流,indices.store.throttle.type属性。它支持none , merge , all这三个属性值
index.store.throttle.type属性,还支持一个默认的node属性值,即表示使用节点级配置取代索 引级配置。每秒最大吞吐量
index.store.throttle.max_bytes_per_sec属性indices.store.throttle.max_bytes_per_sec属性以上配置都可以通过elasticsearch.yml文件配置,也可以动态更新: 使用集群更新设 置接口来更新节点级配置,使用索引更新设置接口来更新索引级配置。
示例
curl -XPUT ‘localhost:9200/_cluster/settings‘ -d ‘{
"persistent":{
"indices.store.throttle.type":"merge",
"indices.store .throttle.max_bytes_per_sec":"50mb"
}
}‘curl -XPUT ‘localhost:9200/payments/_settings‘ -d ‘{
"index.store.throttle.type":"merge",
"index.store.throttle.max_bytes_per_sec":"10mb"
}‘curl -XPOST ‘localhost:9200/payments/_close‘
curl -XPOST ‘localhost:9200/payments/_open‘curl -XGET ‘localhoat:9200/payments/_settings?pretty‘
ElasticSearch需要提前加载 一些数据到缓存中,目的是使用一些如父-子关系、切面计算和基于字段的排序等特定功能。预加载过程需要花费一些时间和资源,在某些时候会使查询变慢。更要命的是,如果索引频繁更新,缓存就需要频繁刷新,而查询性能也就更糟了。
这也是ElasticSearch 0.20版本引人预热器API的原因。预热器是一些标准查询,这些 查询在ElasticSearch尚未对外提供查询服务时,先在冷的(尚未使用的)索引段上执行。查询操作不仅会在ElasticSearch启动时执行,在新索引段提交后也会执行。
ElasticSearch允许我们创建、检索和删除预热器。每个预热器都关联了一个索引,或 者索引和类型的组合。我们在如下场合引入预热器:
使用PUT Warmer API (_warmer 端点)
添加预热器最简单的方法是使用PUT Warmer API。为此我们需要给_warmer REST端 点发送一个带查询的HTTP PUT请求。
curl -XPUT ‘localhost:9200/mastering/doc/_warmer/testWarmer‘ -d ‘{
"query":{
"match all":{}
},
"facets":{
"nameFacet":{
"terms":(
"field":"name"
}
}
}
}’每个预热器都有唯一的名称(如本例中的testWarmer)。我们可以使用这个名称来检索和删除它。
也可以针对整个mastering索引建立预热器
在创建索引时添加预热器
我们需要在请求体中和mappings配置节同一层级的地方添加一个warmers配置节。
curl -XPUT ‘localhost:9200/mastering‘ -d ‘{
"warmers":{
"testWarmer":{
"types":[ "doc" ],
"source":{
"query":{
"match_all":{ }
},
"facets":{
"nameFacet":{
"terms":{
"field":"name"
}
}
}
}
},
"mappings":{
"doc":{
"properties":{
"name":{
"type":"string",
"store":"yes",
"index":"analyzed"
}
}
}
}
}
}‘在模板中添加预热器
curl -XPUT ‘localhost:9200/_template/templateone‘ -d ‘{
"warmers":{
"testWarmer":{
"types":[
"doc"
],
"source":{
"query":{
"match_all":{ }
},
"facets":{
"nameFacet":{
"terms":{
"field":"name"
}
}
}
}
}
},
"template":"test*"
}‘检索预热器
可以通过名称来检索某个预热器:
curl -XGET ‘localhost:9200/mastering/_warmer/warmerOne‘ 通配符检索名字带有特定前缀的预热器 :
curl -XGET ‘localhost:9200/mastering/_warmer/w*‘ 还可以获取某个索引下的所有预热器:
curl -XGET ‘localhost:9200/mastering/_warmer/‘ 删除预热器
与检索预热器类型,不过使用-XDELETE代替-XGET。
禁用预热器
预热器如果暂不使用,又不想删除,则可以禁用它们,只需将index.warmer.enabled属 性设置为false即可。这个属性可以在elasticsearch.yml文件中设置,也可以通过更新设置API设置,例如:
curl -XPUT ‘localhost:9200/mastering/_settings‘ -d ‘{
"index.warmer.enabled":false
}‘当集群变慢且占用较多CPU资源时,你有必要采取一些处理措施来恢复它。然而,热 点线程API就提供了必要的信息,帮助你找到问题根源。热点线程指CPU占用高且执行时间较长的Java线程,而热点线程API可以返回如下信息:从CPU视角看到的ElasticSearch 中执行最频繁的代码段,以及ElasticSearch卡在什么地方。
检查所有节点上的热点线程:
curl localhost:9200/_nodes/hot_threads热点线程API支持如下参数:
例如:
curl `localhost:9200/_nodes/hot_threads?type=wait&interval=1s‘curl ‘localhost:9200/_stats?pretty‘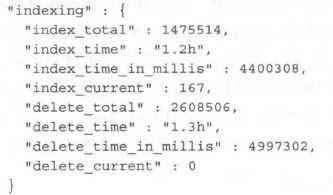

curl localhoat:9200/_cluster/state?pretty
| node.data | node.master | 说明 |
|---|---|---|
| true | true | 节点可以存储索引数据、可以被选为主节点,可以处理查询请求 |
| true | false | 节点可以存储索引数据,但永远不会被选为主节点, 可以处理查询请求 |
| false | true | 节点不存储索引数据,但可以被选为主节点,也可以处理查询请求 |
| false | false | 节点永远不会存储索引数据,也不会被选为主节点,但可以处理查询请求-聚合器节点 |
若大量使用了切面计算,因此我们决定将其中一部分 节点分离出来,命名为聚合器节点,即该节点不持有数据,不做主节点,只负责处理查询请求:多亏了这类节点,我们可以把请求只发送给它们而不会给数据节点带来聚合操作的压力。总之,这意味着给予了数据节点处理更多索引请求的能力。
标签:示例 系统文件 mem 搜索 定时 oms 模块 throttle 知识
原文地址:https://www.cnblogs.com/myitroad/p/mastering_es_ch06_failure_recovery.html