标签:dss 信息论 cga justify adp ima 大小 info wls
熵值法是一种客观赋权法,是指根据各项指标观测值所提供的信息的大小来确定指标权重。在信息论中,熵是对不确定性信息的一种度量。信息量越大,不确定性就越小,熵也就越小;信息量越小,不确定性就越大,熵也越大。
|
熵大 |
越不确定 |
信息量小 |
影响小 |
权重小 |
|
熵小 |
越确定 |
信息量大 |
影响大 |
权重大 |
根据指标的特性,我们可以用熵值来判断某个指标的离散程度:指标熵值越小,离散程度越大,该指标对综合评价的影响(即权重)也越大。
业务情景:设有m个样本,n个评价指标,形成原始数据矩阵
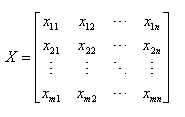
对某项指标![]() ,指标值
,指标值![]() 的差距越大,则该指标在综合评价中所起的作用越大;如果某项指标的指标值全部相等,则该指标在综合评价中不起作用。
的差距越大,则该指标在综合评价中所起的作用越大;如果某项指标的指标值全部相等,则该指标在综合评价中不起作用。
1. 空值处理:指标值如果含有空值,则剔除整条数据
2. 异常值处理:对于占比大于1的剔除(对特殊指标占比除外),再分别计算每个指标下数据的均值和标准差,如果数据大于均值+3*标准差或小于均值-3*标准差,则剔除整条数据。
3. 数据标准化:
由于正向指标和负向指标数值代表的含义不同(正向指标数值越高越好,负向指标数值越低越好),因此,对于高低指标我们用不同的算法进行数据标准化处理。其具体方法如下:
对于正向指标:

对于负向指标:

其中,![]() 为标准化后第i个样本的第j个指标的数值,
为标准化后第i个样本的第j个指标的数值,![]()
4. 计算第j个指标下第i个样本占该指标的比重:

![]()
5. 计算第j个指标的熵值:
![]()
其中,![]() ,ln为自然对数,
,ln为自然对数,![]() 。式中常数k与样本数m有关,一般
。式中常数k与样本数m有关,一般![]() ,则
,则![]()
6. 计算第j个指标的信息效用值:
![]()
7. 计算各项指标的权重:

8. 计算各样本的综合得分:
![]()
![]()
熵值法避免了人为因素带来的偏差,但由于忽略了指标本身重要程度,有时确定的指标权重会与预期的结果相差甚远,同时熵值法不能减少评价指标的维数。
2018-08-05 21:30:06
标签:dss 信息论 cga justify adp ima 大小 info wls
原文地址:https://www.cnblogs.com/Amy9/p/9280994.html