标签:fine 软件开发过程 sign 流程图 res 问题分析 平台 sigsegv notify
我们在项目开发过程中,很多时候会出现由于某种原因经常会导致手机系统死机重启的情况(重启分Android重启跟kernel重启,而我们这里只讨论kernel重启也就是 kernel panic 的情况),死机重启基本算是影响最严重的系统问题了,有稳定复现的,也有概率出现的,解题难度也千差万别,出现问题后,通常我们会拿到类似这样的kernel log信息(下面log仅以调用BUG()为例,其它异常所致的死机log信息会有一些不同之处):
[ 2.052157] <2>-(2)[1:swapper/0]------------[ cut here ]------------
[ 2.052163] <2>-(2)[1:swapper/0]Kernel BUG at c04289dc [verbose debug info unavailable]
[ 2.052169] <2>-(2)[1:swapper/0]Internal error: Oops - BUG: 0 [#1] PREEMPT SMP ARM
[ 2.052178] <2>-(2)[1:swapper/0]disable aee kernel api[ 3.052192] <2>-(2)[1:swapper/0]Non-crashing CPUs did not react to IPI
[ 3.052204] <2>-(2)[1:swapper/0]CPU: 2 PID: 1 Comm: swapper/0 Tainted: G W 3.18.35+ #3
[ 3.052211] <2>-(2)[1:swapper/0]task: df060000 ti: df04a000 task.ti: df04a000
[ 3.052227] <2>-(2)[1:swapper/0]PC is at ltr553_i2c_probe+0x94/0x9c
[ 3.052233] <2>-(2)[1:swapper/0]LR is at 0x0
[ 3.052242] <2>-(2)[1:swapper/0]pc : [<c04289dc>] lr : [<00000000>] psr: a0000113
[ 3.052242] <2>sp : df04bd30 ip : 00000000 fp : df04bd4c
[ 3.052249] <2>-(2)[1:swapper/0]r10: 00000003 r9 : de348fc0 r8 : c0428948
[ 3.052255] <2>-(2)[1:swapper/0]r7 : dea1bc00 r6 : dea1bc04 r5 : dea1bc20 r4 : c0b53358
[ 3.052262] <2>-(2)[1:swapper/0]r3 : c115ef4c r2 : 00000000 r1 : 00000000 r0 : de366a00
[ 4.354655] <2>-(2)[1:swapper/0] oops_end, 1, 11
[ 4.354740] <2>-(2)[1:swapper/0]Kernel panic - not syncing: Fatal exception这是linux 内核在死机之前输出的相关重要信息,包括PC指针、调用栈等在内的非常重要的便于Debug的线索,比如我们可以借助GUN tools(add2Line)工具结合内核符号映射表vmlinux来定位当前PC指针所在的代码具体行数(定位到出错代码行并不意味着就找到了问题的根本原因跟修复异常,这个需要根据异常的复杂程度而论)。深入理解这些关键打印log信息的含义和机制非常有助于我们对于此类死机问题的定位和分析(对于内存被踩、硬件不稳定导致的一类问题分析有局限性),这也是我们需要深入学习内核异常流程的初衷。
这里我们必须弄清楚几个问题:
为此,本文就从最常见的主动触发BUG()为例解析上面的疑问及分析整个kernel panic流程。
有过驱动调试经验的人肯定都知道这个东西,这里的BUG跟我们一般认为的“软件缺陷”可不是一回事,这里说的BUG()其实是linux kernel中用于拦截内核程序超出预期的行为,属于软件主动汇报异常的一种机制。这里有个疑问,就是什么时候会用到呢?一般来说有两种用到的情况,一是软件开发过程中,若发现代码逻辑出现致命fault后就可以调用BUG()让kernel死掉(类似于assert),这样方便于定位问题,从而修正代码执行逻辑;另外一种情况就是,由于某种特殊原因(通常是为了debug而需抓ramdump),我们需要系统进入kernel panic的情况下使用.
BUG()跟BUG_ON(1)其实本质是一回事,后者只是在前者的基础上做了简单的封装而已,BUG()的实现 本质是埋入一条未定义指令:0xe7f001f2,触发ARM发起Undefined Instruction异常(PS:ARM有分10种异常类型,详细可以复习ARM异常模型章节).
<kernel-3.18/arch/arm/include/asm/bug.h>
#define BUG_INSTR_VALUE 0xe7f001f2
#define BUG_INSTR(__value) __inst_arm(__value)
#define BUG() _BUG(__FILE__, __LINE__, BUG_INSTR_VALUE)
#define _BUG(file, line, value) __BUG(file, line, value)
#define __BUG(__file, __line, __value) do { asm volatile(BUG_INSTR(__value) "\n"); unreachable(); } while (0)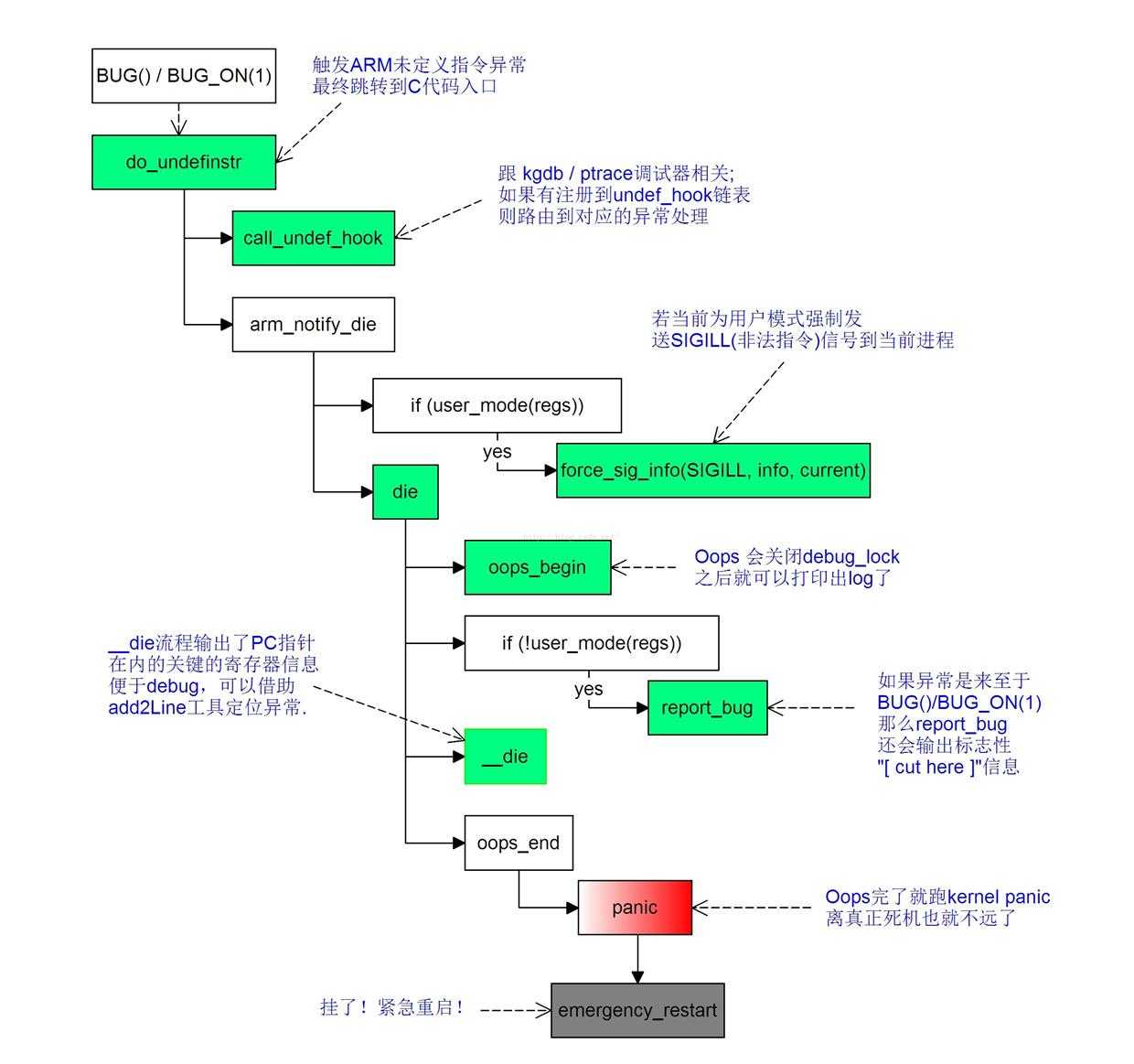
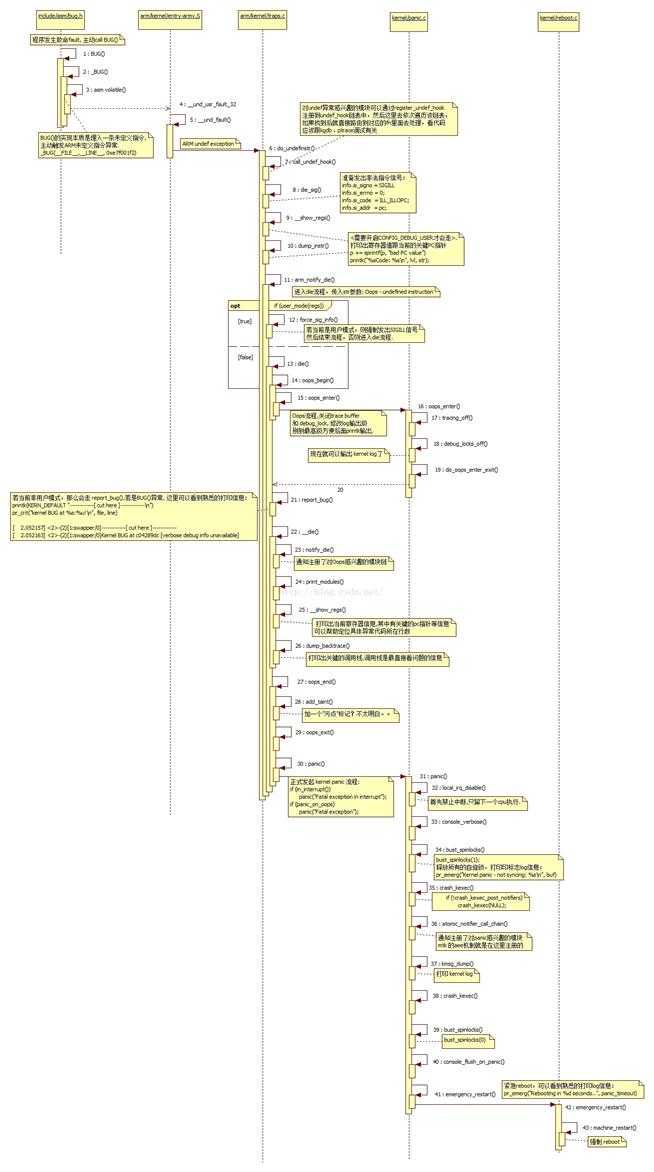
调用BUG()会向CPU下发一条未定义指令而触发ARM发起未定义指令异常,随后进入kernel异常处理流程历经 Oops,die(),__die()等流程输出用于调试分析的关键线索,最后进入panic()结束自己再获得重生的过程,这个就是整个过程的基本流程,下面先来看die()具体做了什么呢?
源码:
void die(const char *str, struct pt_regs *regs, int err)
{
enum bug_trap_type bug_type = BUG_TRAP_TYPE_NONE;
unsigned long flags = oops_begin();
int sig = SIGSEGV;
if (!user_mode(regs))
bug_type = report_bug(regs->ARM_pc, regs);
if (bug_type != BUG_TRAP_TYPE_NONE)
str = "Oops - BUG";
if (__die(str, err, regs))
sig = 0;
oops_end(flags, regs, sig);
}总流程大致如下:
通常来说,代码分析过程结合kernel log一起看会理解来得更加深刻,如果是BUG()/BUG_ON(1)导致的异常,那么走到report_bug 就可以看到下面标志性 log:
enum bug_trap_type report_bug(unsigned long bugaddr, struct pt_regs *regs)
{
...
if (!is_valid_bugaddr(bugaddr))
return BUG_TRAP_TYPE_NONE;
...
printk(KERN_DEFAULT "------------[ cut here ]------------\n");
if (file)
pr_crit("kernel BUG at %s:%u!\n", file, line);
else
pr_crit("Kernel BUG at %p [verbose debug info unavailable]\n",
(void *)bugaddr);
===>
[ 2.052157] <2>-(2)[1:swapper/0]------------[ cut here ]------------
[ 2.052163] <2>-(2)[1:swapper/0]Kernel BUG at c04289dc [verbose debug info unavailable]
[ 2.052169] <2>-(2)[1:swapper/0]Internal error: Oops - BUG: 0 [#1] PREEMPT SMP ARM所以如果在log中看到了这个 “[ cut here ]” 的信息就推断是软件发生致命fault而主动call了BUG()所致的系统重启了,就可以根据相关信息尝试定位分析修复异常了.**这里要注意的是还有另外一种__WARN()的情况也会打印出 “[ cut here ]” 的标志性log但是内核并不会挂掉,容易造成误导:**
#define __WARN() warn_slowpath_null(__FILE__, __LINE__)
#define __WARN_printf(arg...) warn_slowpath_fmt(__FILE__, __LINE__, arg)
void warn_slowpath_fmt(const char *file, int line, const char *fmt, ...)
{
...
warn_slowpath_common(file, line, __builtin_return_address(0),
TAINT_WARN, &args);
static void warn_slowpath_common(const char *file, int line, void *caller,
unsigned taint, struct slowpath_args *args)
{
...
pr_warn("------------[ cut here ]------------\n");
pr_warn("WARNING: CPU: %d PID: %d at %s:%d %pS()\n",
raw_smp_processor_id(), current->pid, file, line, caller);
===>
[ 1.106219] <2>-(2)[1:swapper/0]------------[ cut here ]------------
[ 1.107018] <2>-(2)[1:swapper/0]WARNING: CPU: 2 PID: 1 at /home/android/work/prj/n-6580/kernel-3.18/kernel/irq/manage.c:454 __enable_irq+0x50/0x8c()
所以其实从显现上很好区分两种情况,如果是BUG()/BUG_ON(1)那么内核一定会挂掉重启,而__WARN()只会dump_stack()而不会死机, 从源码跟log信息也可以容易区分两种情况,如果是BUG()/BUG_ON(1)的话一定有类似下面的log输出,只要搜索关键字:“Internal error: Oops” 即可.
[ 2.052163] <2>-(2)[1:swapper/0]Kernel BUG at c04289dc [verbose debug info unavailable]
[ 2.052169] <2>-(2)[1:swapper/0]Internal error: Oops - BUG: 0 [#1] PREEMPT SMP ARM
从上面输出的log信息还不足以定位具体出问题的代码位置,包括定位异常所需要的最关键的 PC指针、调用栈等这些对于调试来说至关重要的线索信息都是在__die()中输出.
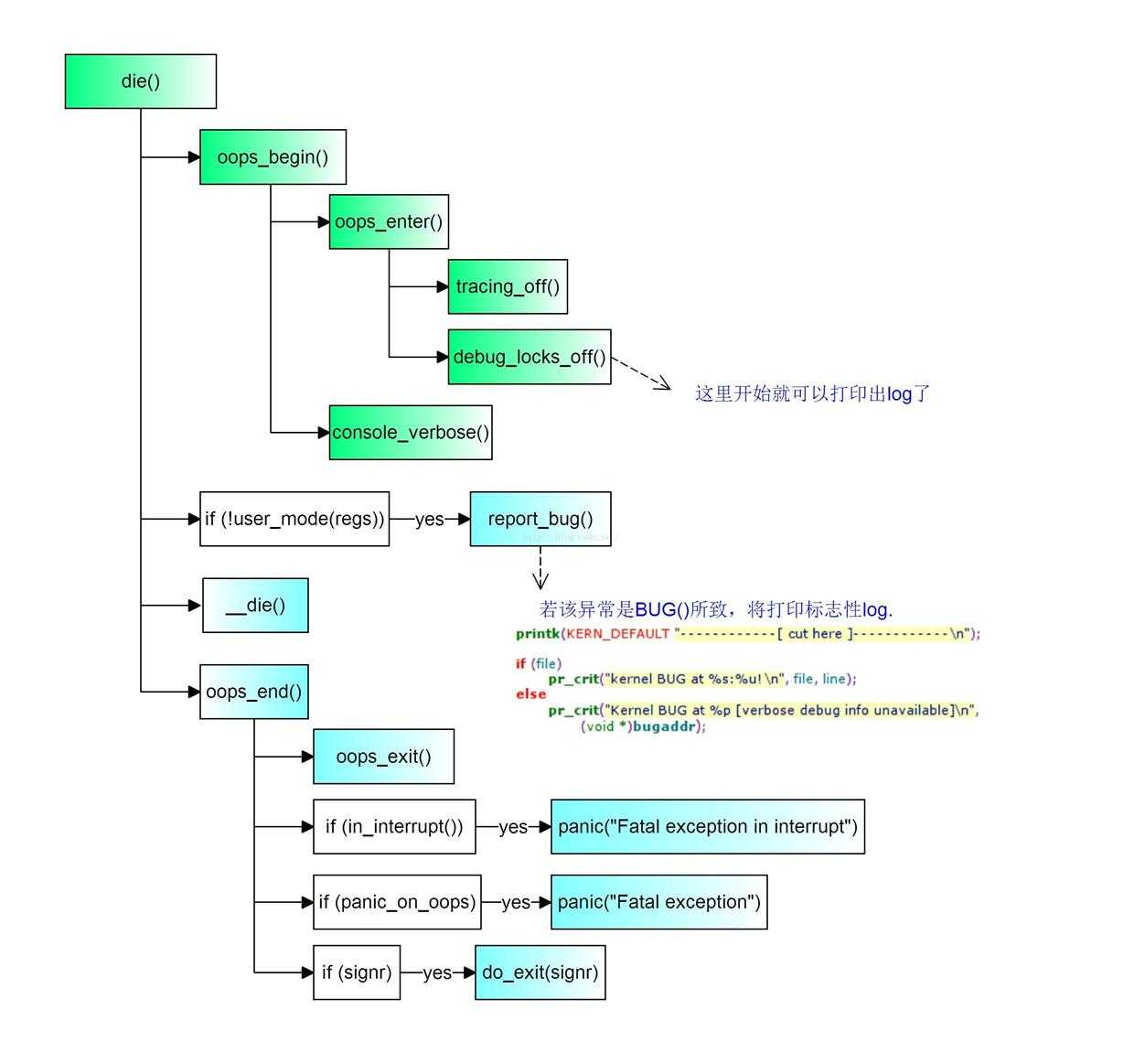
流程图:
打印出标志性log信息:
static int __die(const char *str, int err, struct pt_regs *regs)
{
...
printk(KERN_EMERG "Internal error: %s: %x [#%d]" S_PREEMPT S_SMP
S_ISA "\n", str, err, ++die_counter);
===>
[ 2.052169] <2>-(2)[1:swapper/0]Internal error: Oops - BUG: 0 [#1] PREEMPT SMP ARM
log 显示异常str是Oops - BUG,error-code 为0,die计数器次数:1
Oops 的本意为 “哎呀” 的一个俚语,这里意形象的意指kernel出现了一件意外而不知道该如何处理的事件.
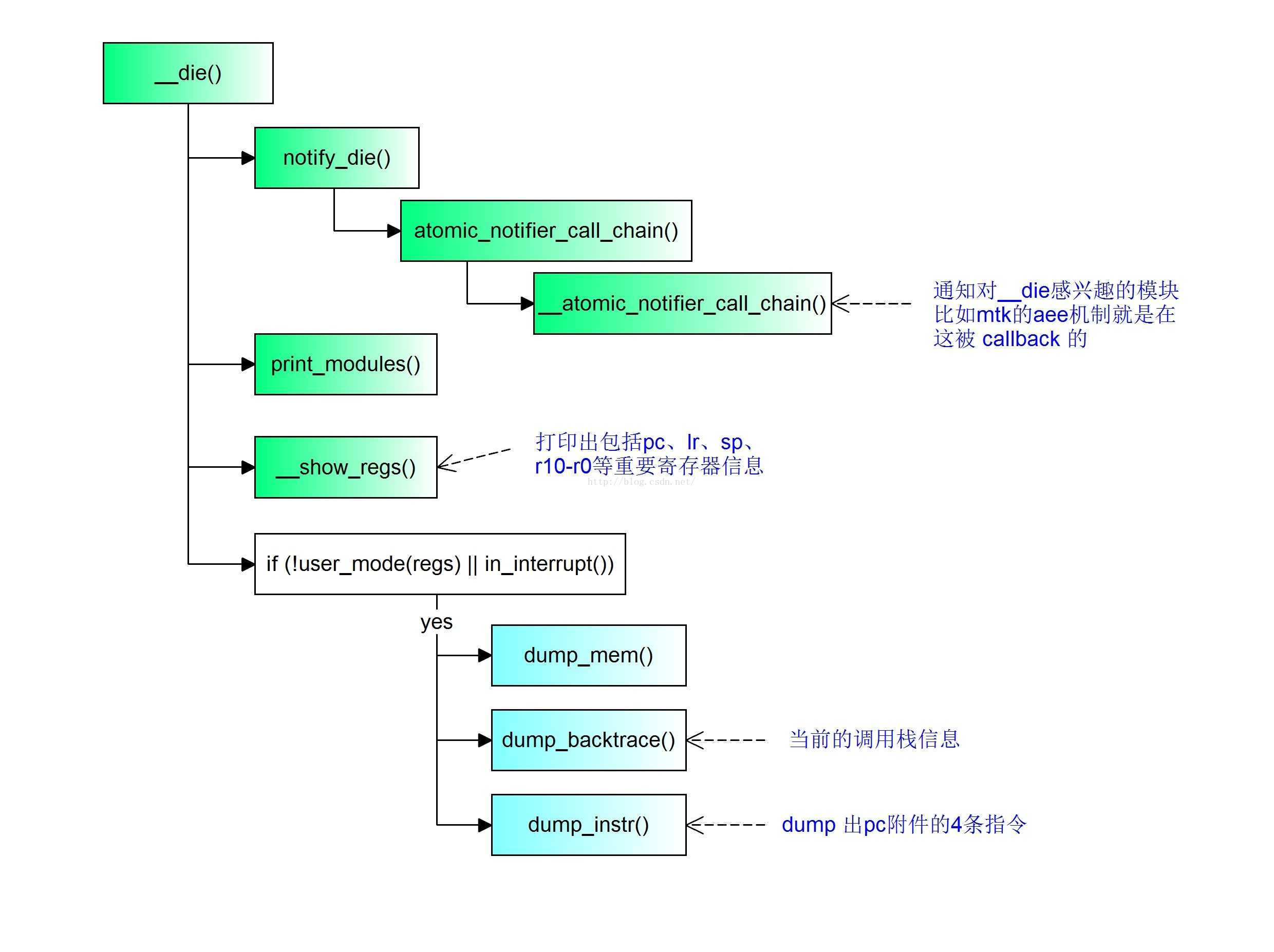
notify_die() 会通知对Oops感兴趣的模块执行相关回调,比如mtk的aee异常引擎模块就是通过注册到die_chain通知链上的.
int notrace notify_die(enum die_val val, const char *str,
struct pt_regs *regs, long err, int trap, int sig)
{
struct die_args args = {
.regs = regs,
.str = str,
.err = err,
.trapnr = trap,
.signr = sig,
};
return atomic_notifier_call_chain(&die_chain, val, &args);
}mtk的aee异常引擎在kernel初始化的时候会去注册到die_chain通知链,而且我们可以看到其实还注册了panic通知链.
int __init aee_ipanic_init(void)
{
spin_lock_init(&ipanic_lock);
mrdump_init();
atomic_notifier_chain_register(&panic_notifier_list, &panic_blk);
register_die_notifier(&die_blk);
register_ipanic_ops(&ipanic_oops_ops);
ipanic_log_temp_init();
ipanic_msdc_init();
LOGI("ipanic: startup, partition assgined %s\n", AEE_IPANIC_PLABEL);
return 0;
}而对我们调试追踪有用的关键信息是在 __show_regs() 里面打印的:
void __show_regs(struct pt_regs *regs)
{
unsigned long flags;
char buf[64];
show_regs_print_info(KERN_DEFAULT);
print_symbol("PC is at %s\n", instruction_pointer(regs));
print_symbol("LR is at %s\n", regs->ARM_lr);
printk("pc : [<%08lx>] lr : [<%08lx>] psr: %08lx\n"
"sp : %08lx ip : %08lx fp : %08lx\n",
regs->ARM_pc, regs->ARM_lr, regs->ARM_cpsr,
regs->ARM_sp, regs->ARM_ip, regs->ARM_fp);
printk("r10: %08lx r9 : %08lx r8 : %08lx\n",
regs->ARM_r10, regs->ARM_r9,
regs->ARM_r8);
printk("r7 : %08lx r6 : %08lx r5 : %08lx r4 : %08lx\n",
regs->ARM_r7, regs->ARM_r6,
regs->ARM_r5, regs->ARM_r4);
printk("r3 : %08lx r2 : %08lx r1 : %08lx r0 : %08lx\n",
regs->ARM_r3, regs->ARM_r2,
regs->ARM_r1, regs->ARM_r0);
flags = regs->ARM_cpsr;
buf[0] = flags & PSR_N_BIT ? 'N' : 'n';
buf[1] = flags & PSR_Z_BIT ? 'Z' : 'z';
buf[2] = flags & PSR_C_BIT ? 'C' : 'c';
buf[3] = flags & PSR_V_BIT ? 'V' : 'v';
buf[4] = '\0';
printk("Flags: %s IRQs o%s FIQs o%s Mode %s ISA %s Segment %s\n",
buf, interrupts_enabled(regs) ? "n" : "ff",
fast_interrupts_enabled(regs) ? "n" : "ff",
processor_modes[processor_mode(regs)],
isa_modes[isa_mode(regs)],
get_fs() == get_ds() ? "kernel" : "user");
show_extra_register_data(regs, 128);
}
void dump_stack_print_info(const char *log_lvl)
{
printk("%sCPU: %d PID: %d Comm: %.20s %s %s %.*s\n",
log_lvl, raw_smp_processor_id(), current->pid, current->comm,
print_tainted(), init_utsname()->release,
(int)strcspn(init_utsname()->version, " "),
init_utsname()->version);
...
这里打印出了重要的pc停下的位置、相关寄存器信息,发生的是user还是kernel的异常、发生异常的cpu、进程pid等信息.
===>

接下来 dump_mem() 用于dump出当前线程的内存信息:
dump_mem(KERN_EMERG, "Stack: ", regs->ARM_sp,
THREAD_SIZE + (unsigned long)task_stack_page(tsk));
使用 dump_backtrace(regs, tsk) 打印出调试最直观的调用栈信息:
===>
[ 3.056363] <2>-(2)[1:swapper/0]Backtrace: -(2)[1:swapper/0]
[ 3.056386] <2>-(2)[1:swapper/0][<c010badc>] (dump_backtrace) from [<c010bc7c>] (show_stack+0x18/0x1c)
[ 3.056393] <2>-(2)[1:swapper/0] r6:c103d790-(2)[1:swapper/0] r5:ffffffff-(2)[1:swapper/0] r4:00000000-(2)[1:swapper/0] r3:00000000-(2)[1:swapper/0]
[ 3.056426] <2>-(2)[1:swapper/0][<c010bc64>] (show_stack) from [<c0a91e64>] (dump_stack+0x90/0xa4)
[ 3.056439] <2>-(2)[1:swapper/0][<c0a91dd4>] (dump_stack) from [<c072d264>] (ipan6503] <2>-(2)[1:swapper/0][<c013e6bc>] (notifier_call_chain) from [<c013eb84>] (atomic_notifier_call_chain+0x3c/0x50)
[ 3.056509] <2>-(2)[1:swapper/0] r10:c10efec4-(2)[1:swapper/0] r9:df060000-(2)[1:swapper/0] r8:df04a020-(2)[1:swapper/0] r7:c0caaaf0-(2)[1:swapper/0] r6:c10f0c88-(2)[1:swapper/0] r5:00000001
[ 3.056539] <2>-(2)[1:swapper/0] r4:df04bb74-(2)[1:swapper/0]
[ 3.056554] <2>-(2)[1:swapper/0][<c013eb48>] (atomic_notifier_call_chain) from [<c013f244>] (notify_die+0x44/0x4c)
[ 3.056560] <2>-(2)[1:swapper/0] r6:df04bce8-(2)[1:swapper/0] r5:00000000-(2)[1:swapper/0] r4:00000001-(2)[1:swapper/0]
[ 3.056585] <2>-(2)[1:swapper/0][<c013f200>] (notify_die) from [<c010bd94>] (die+0x114/0x41c)
[ 3.056590] <2>-(2)[1:swapper/0] r4:c102826c-(2)[1:swapper/0]
[ 3.056607] <2>-(2)[1:swapper/0][<c010bc80>] (die) from [<c010c0c0>] (arm_notify_die+0x24/0x5c)
[ 3.056612] <2>-(2)[1:swapper/0] r10:df04a000-(2)[1:swapper/0] r9:00000000-(2)[1:swapper/0] r8:df04bce8-(2)[1:swapper/0] r7:e7f001f2-(2)[1:swapper/0] r6:df04a000-(2)[1:swapper/0] r5:c04289dc
[ 3.056642] <2>-(2)[1:swapper/0] r4:00000004-(2)[1:swapper/0]
[ 3.056658] <2>-(2)[1:swapper/0][<c010c09c>] (arm_notify_die) from [<c01001cc>] (do_undefinstr+0x1a4/0x1ec)
[ 3.056670] <2>-(2)[1:swapper/0][<c0100028>] (do_undefinstr) from [<c010c98c>] (__und_svc_finish+0x0/0x34)
[ 3.056676] <2>-(2)[1:swapper/0]Exception stack(0xdf04bce8 to 0xdf04bd30)
[ 3.056687] <2>-(2)[1:swapper/0]bce0: de366a00 00000000 00000000 c115ef4c c0b53358 dea1bc20
[ 3.056698] <2>-(2)[1:swapper/0]bd00: dea1bc04 dea1bc00 c0428948 de348fc0 00000003 df04bd4c 00000000 df04bd30
[ 3.056706] <2>-(2)[1:swapper/0]bd20: 00000000 c04289dc a0000113 ffffffff
[ 3.056711] <2>-(2)[1:swapper/0] r9:c010c98c-(2)[1:swapper/0] r8:e7100000-(2)[1:swapper/0] r7:00000000-(2)[1:swapper/0] r6:c010cd98-(2)[1:swapper/0] r5:00000000-(2)[1:swapper/0] r4:c04289e0
[ 3.056750] <2>-(2)[1:swapper/0][<c0428948>] (ltr553_i2c_probe) from [<c07d88d8>] (i2c_device_probe+0xd0/0x12c)
[ 3.056756] <2>-(2)[1:swapper/0] r5:dea1bc20-(2)[1:swapper/0] r4:c0b53358-(2)[1:swapper/0]
[ 3.056778] <2>-(2)[1:swapper/0][<c07d8808>] (i2c_device_probe) from [<c03c298c>] (driver_probe_device+0x160/0x43c)
通过上面的调用栈信息结合GUN Tools(add2Line)基本就可以定位发生异常的具体代码位置了.
最后会通过dump_instr(KERN_EMERG, regs) 打印出pc指针和前4条指令:
static void dump_instr(const char *lvl, struct pt_regs *regs)
{
...
for (i = -4; i < 1 + !!thumb; i++) {
unsigned int val, bad;
if (thumb)
bad = __get_user(val, &((u16 *)addr)[i]);
else
bad = __get_user(val, &((u32 *)addr)[i]);
if (!bad)
p += sprintf(p, i == 0 ? "(%0*x) " : "%0*x ", width, val);
else {
p += sprintf(p, "bad PC value");
break;
}
}
printk("%sCode: %s\n", lvl, str);
..
===>
[ 3.226706] <2>-(2)[1:swapper/0][<c0a8ae74>] (/0]Code: e89da830 e30e3f4c e34c3115 e5830000 (e7f001f2)
看到这个 e7f001f2 了吧,是不是很眼熟?这个就是BUG()中埋入的未定义指令!
到这一步,大部分关键信息都已经输出了,可以通过add2Line工具定位出具体死在的代码行号,大致看看发生了什么,如果是BUG()导致的异常,那么就可以考虑分析和修复异常了,因为BUG()属于主动汇报异常,一般来说debug难度会相对其它的被动上报方式容易得多.
例如:
从上面log知PC死在的地址<c04289dc>,通过add2Line工具结合内核符号映射表 vmlinux 就可以定位出具体代码所在文件行号:
arm-linux-androideabi-addr2line -e out/target/product/$project/obj/KERNEL_OBJ/vmlinux -f -C c04289dc
ltr553_i2c_probe
/aosp/kernel-3.18/drivers/misc/mediatek/alsps/ltr553/ltr553.c:3278定位到了具体代码行号就可以进一步分析代码log找出问题原因修复异常了(一般来说BUG()导致的异常比较好解,其它的情况难度就是天差地别了..)。 那么接下来kernel要干什么呢?重要信息都输出完了接下来就直接走 kernel panic 流程了.
panic 本意是“恐慌”的意思,这里意旨kernel发生了致命错误导致无法继续运行下去的情况.
流程图:
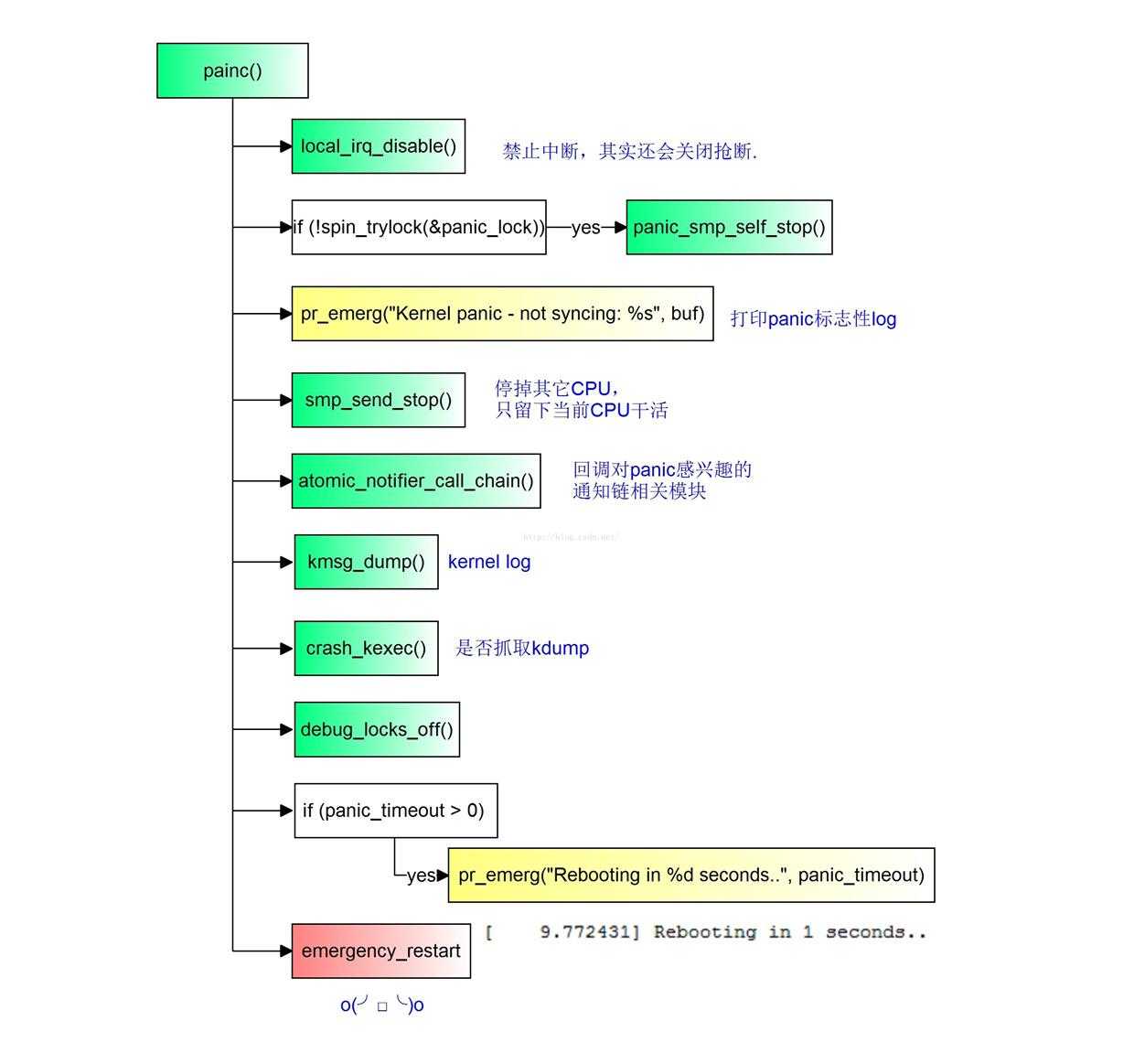
相关重要的debug信息已经在之前的__die()流程输出完成了,panic()其实要干的主要事情就是让系统先死掉再重生,kernel panic有标志性的log打印,可以作为是否发生panic的搜索关键字.
[ 4.354740] <2>-(2)[1:swapper/0]Kernel panic - not syncing: Fatal exception虽然主要的工作就是让系统复位,但在去的路上还是会做一些事情,尽可能的不遗余力给事后分析提供线索,比如atomic_notifier_call_chain()会去遍历panic_notifier_list链表,依次通知对panic感兴趣的模块(比如mtk的aee机制在这里会把异常的一小块内存给dump处理放到expdb分区,不过后面新的机制是改在reboot后再来做了)做一些事情,如果打开了ramdump支持就直接陷入download模式,抓取ramdump供离线分析用,单从这块来讲MTK/QCOM平台流程差不多.
[ 9.772431] Rebooting in 1 seconds..另外还要说的一点是,以上所有的分析都是基于log信息的分析,简单易行,这是系统异常调试中最基本也是最重要的分析手段,对于BUG()导致的问题通常可以比较顺利的分析解决,但是也有其局限性,比如内存被踩、硬件不稳定导致的概率死机等类型问题分析起来就往往很吃力,而这就需要借助ramdump分析手段才能进一步比较顺利的分析解题.
最后附上总时序图
标签:fine 软件开发过程 sign 流程图 res 问题分析 平台 sigsegv notify
原文地址:https://www.cnblogs.com/linhaostudy/p/9429511.html