标签:com tar 分享图片 问题 页面 src beautiful ref bubuko
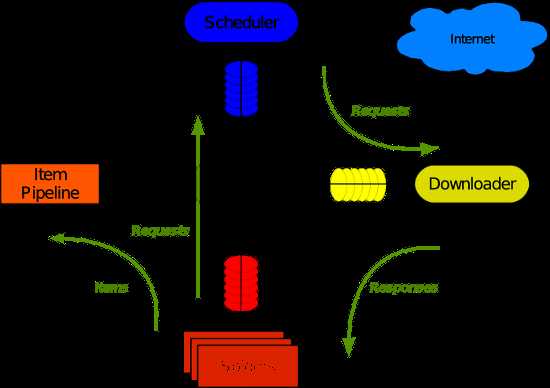
自己利用requests模块下载页面,使用Beautifulsoup解析Html内容,久而久之会遇到各种性能问题,所有专业级的爬虫还得使用 爬虫框架----Scrapy
Scrapy功能
----引用twisted模块异步下载页面
-----HTML解析成对象
-----代理
----延迟下载
----URL字段去重
----指定深度、广度
...........................
参考:http://www.cnblogs.com/wupeiqi/articles/6229292.html
标签:com tar 分享图片 问题 页面 src beautiful ref bubuko
原文地址:https://www.cnblogs.com/sss4/p/9429835.html