标签:的区别 number test 数据库 info 外部表 name 字段 相同
创建一个内部表:
hive> CREATE TABLE IF NOT EXISTS student1 (sno INT,name STRING,age INT,sex STRING)
> ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘\t‘ STORED AS TEXTFILE;

查看
hive> show tables;
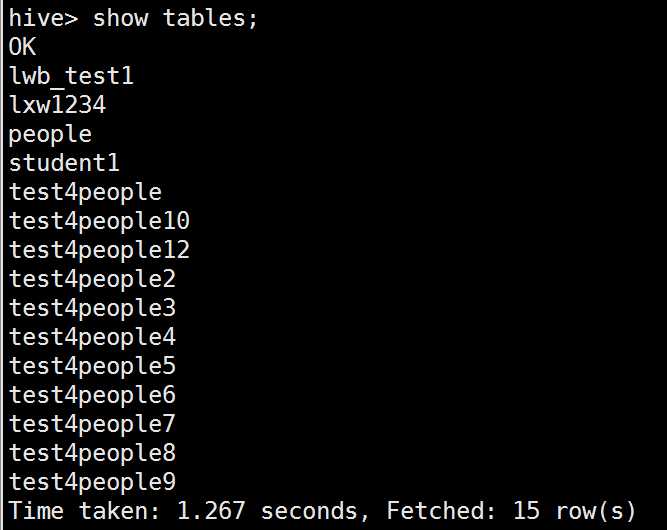
创建外部表:
hive> CREATE EXTERNAL TABLE IF NOT EXISTS student2 (sno INT,sname STRING,age INT,sex STRING)
> ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘\t‘
> STORED AS TEXTFILE LOCATION ‘/user/external‘;

查询
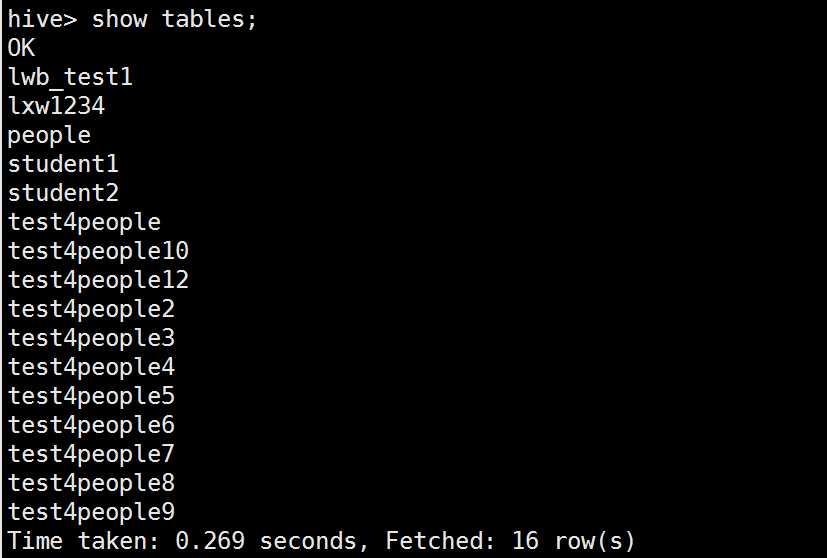

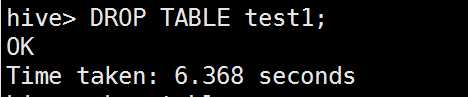
删除表test1表
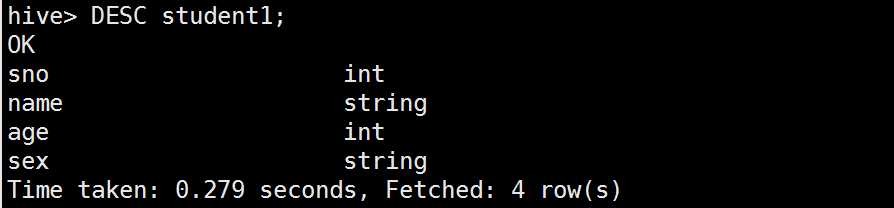
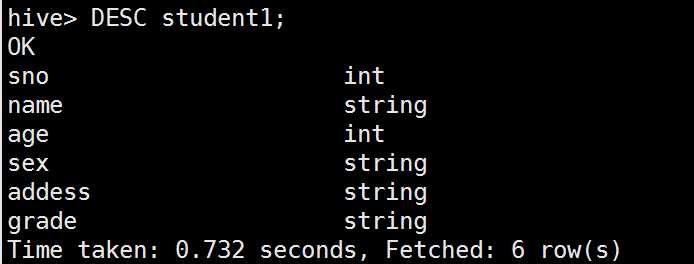
查看表结构
添加字段并查看表结构
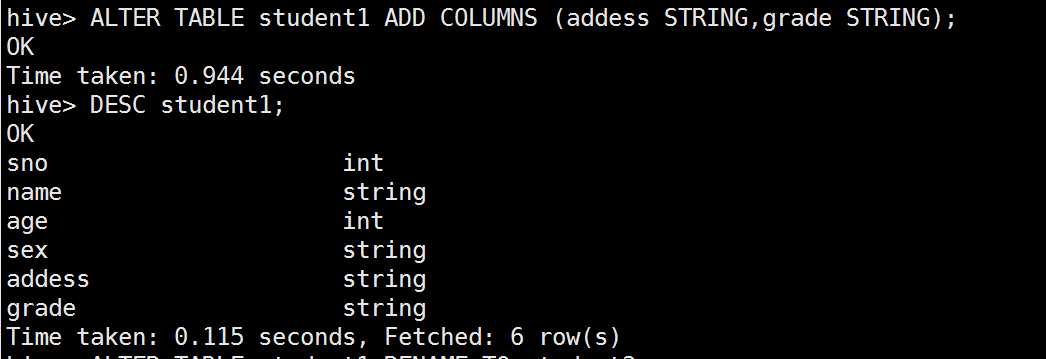
修改表名

查看修改
修改回原来的

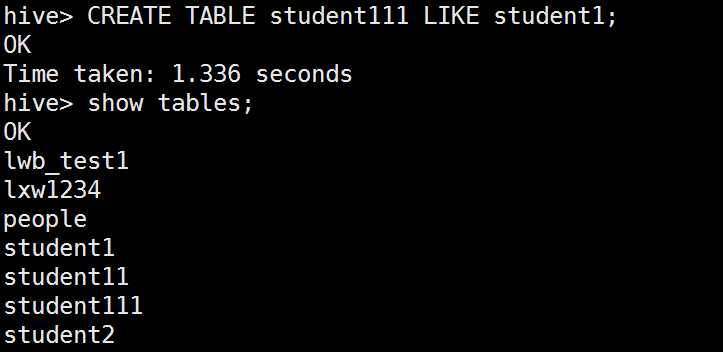
创建和已知表结构相同的表
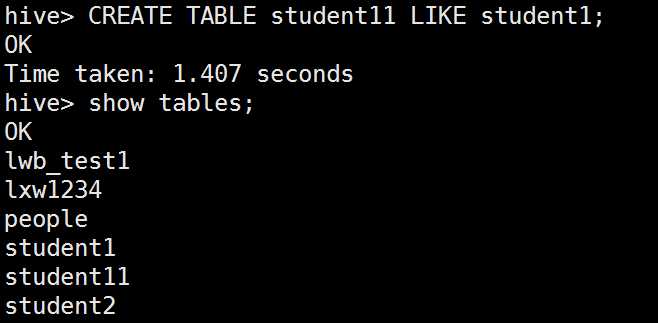
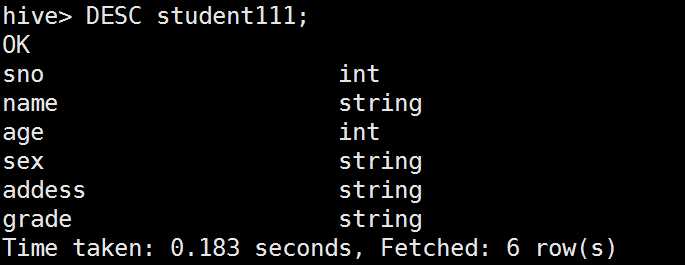
查看表结构
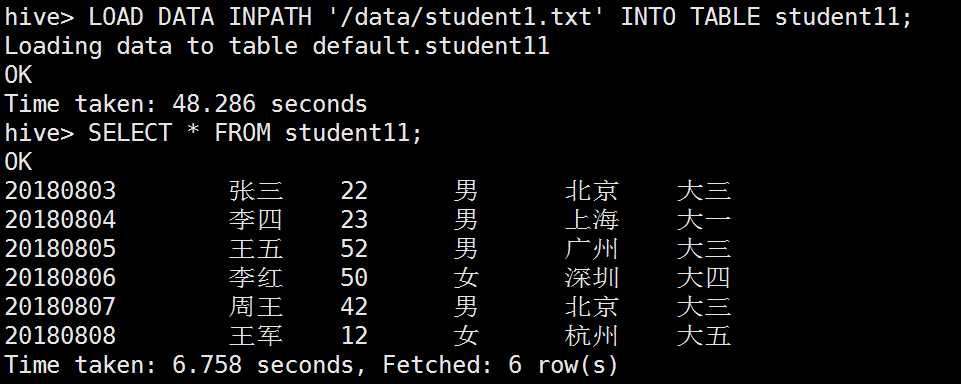
加载本地数据

查看
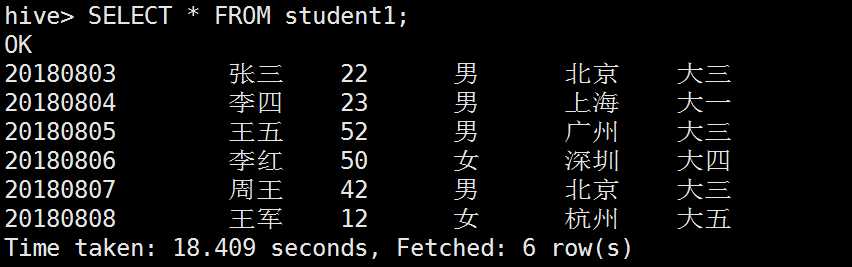
加载HDFS中的数据
单表插入
先创建表
查看表结构是否相同
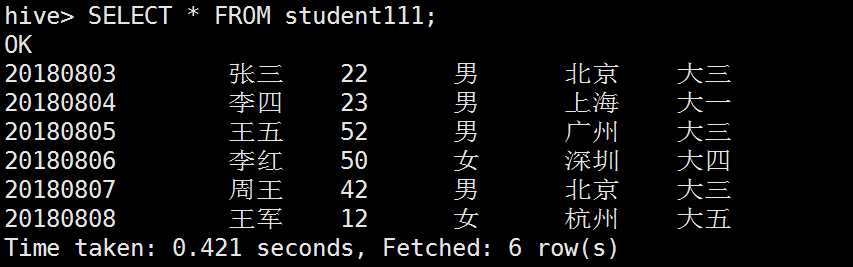
将student1中的数据插入student11
hive> INSERT OVERWRITE TABLE student111 SELECT * FROM student11;

查看
多表插入
创建表
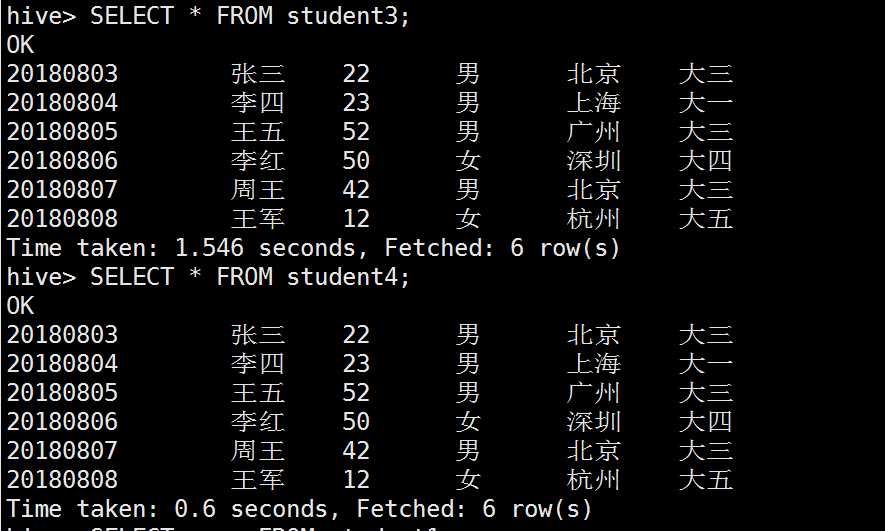
将student1中的数据同时插入student3和student4
hive> FROM student1 INSERT OVERWRITE TABLE student3 SELECT *
> INSERT OVERWRITE TABLE student4 SELECT *;

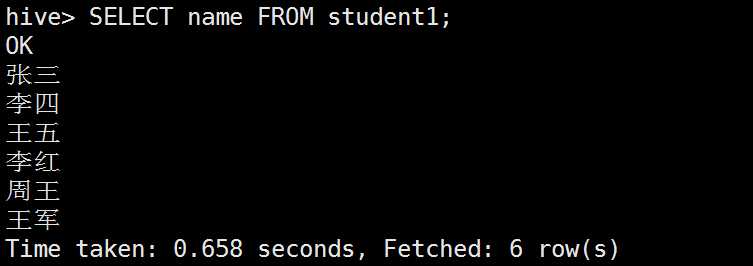
查询某个字段
where条件查询
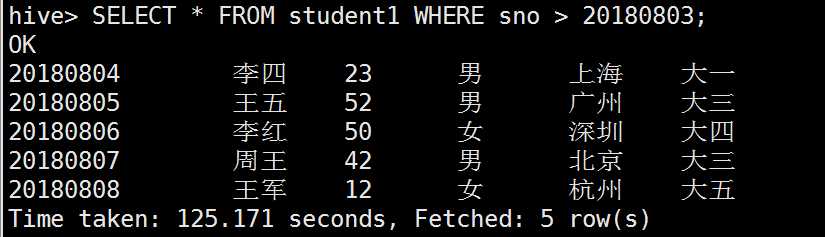
all和distinct的区别:
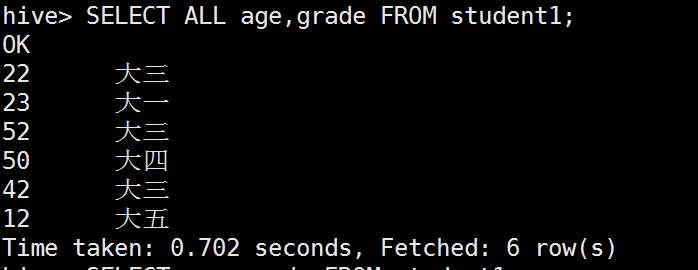
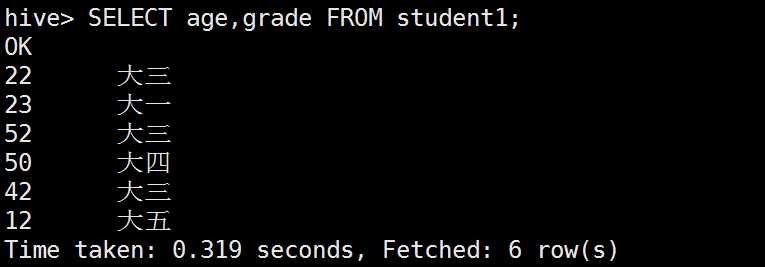
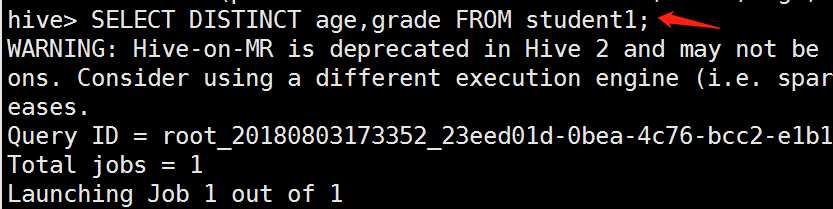
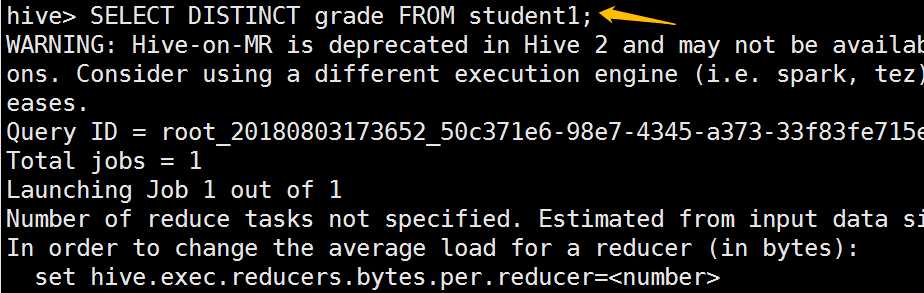
limit限制查询条数
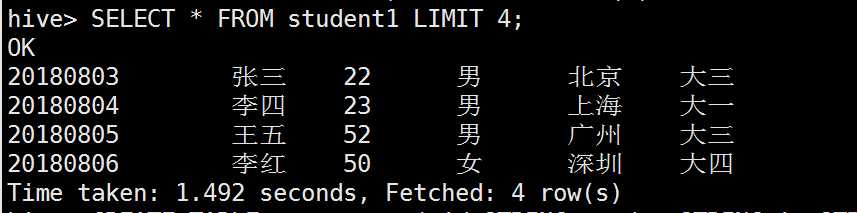
group by分组查询的使用:
创建表
导入数据

查看
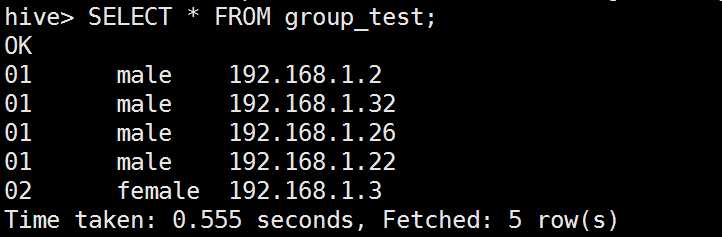
计算表的行数

创建去重后存放数据的表

将去重后的数据导入group_gender_sum表
hive> INSERT OVERWRITE TABLE group_gender_sum SELECT group_test.gender, COUNT (DISTINCT
group_test.uid) FROM group_test GROUP BY group_test.gender;

注意:聚合操作可以同时进行多个操作,但是不能有两个聚合操作有不同的distinct列。
下面给出测试:
先创建一个表:group_gender_agg

将group_test聚合后的数据插入到group_gender_agg
hive> INSERT OVERWRITE TABLE group_gender_agg SELECT group_test.gender,COUNT(DISTINCT gr
oup_test.uid),COUNT(*),sum(DISTINCT group_test.uid) > FROM group_test GROUP BY group_test.gender;

下面的查询就是错误的,不能包含多个distinct。不能通过同时操作两个不同的列。
hive> INSERT OVERWRITE TABLE group_gender_agg
> SELECT group_test.gender,COUNT(DISTINCT group_test.uid),COUNT(DISTINCT group_test.ip)
> FROM group_test > GROUP BY group_test.gender;

ORDER BY 排序查询
ORDER BY 会对输入做全局排序,这样就只有一个reduce,当输入数据规模较大时需要耗费较长的计算时间。(因为多个reduce是不能保证全局有序的)
使用 ORDER BY 查询的时候,为了优化查询速度,使用hive.mapred.mode属性。
hive.mapred.mode=nonstrict;(defult value/默认值)
hive.mapred.mode=strict;
这里与数据库中的ORDER BY的区别在于, hive.mapred.mode=strict模式下必须制定limit,否则报错。
hive> set hive.mapred.mode=strict;
hive> SELECT * FROM group_test ORDER BY uid limit 5;

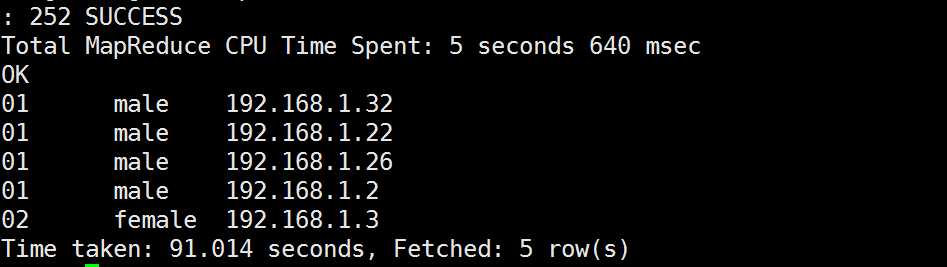
SORT BY 查询
SORT BY不会受到hive.mapred.mode的值是否为strict和nonstrict的影响。
SORT BY的数据只能保证在同一个reduce中的数据可以按照制定字段排序。
使用SORT BY可以指定执行的reduce的个数(set mapred.reduce.tasks=<number>).可以输出更多的数据。
对输出的数据再执行归并排序,即可以得到全部结果。
hive> set hive.mapred.mode=strict;
hive> SELECT * FROM group_test SORT BY uid;

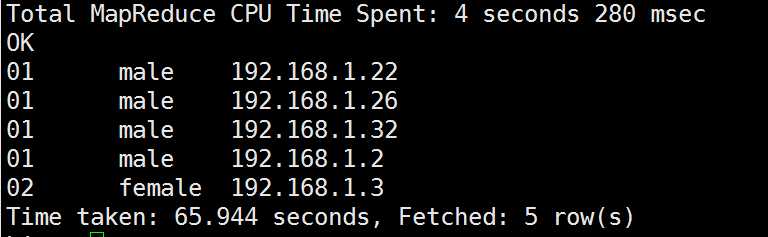
DISTRIBUTE BY排序查询
按照指定的对数据划分到不同的输出reduce文件中(控制map的输出在reducer是如何划分的)
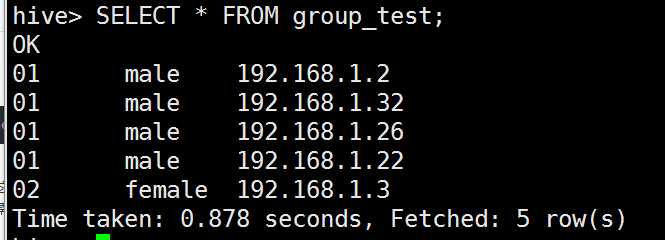

我们所有的uid相同的数据会被送到同一个reducer去处理,这就是因为指定了distribute by uid(这个肯定是全局有序的,因为相同的商户会放到同一个reducer去处理)。这里需要注意的是distribute by必须要写在sort by之前。
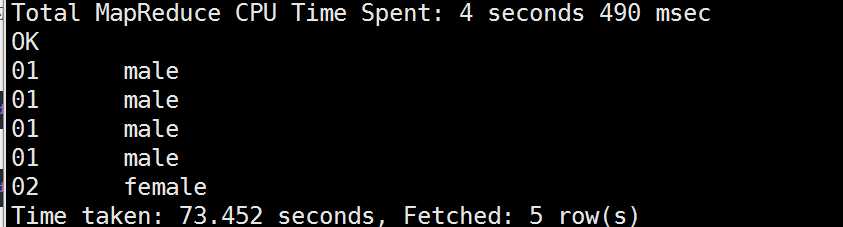
cluster by的功能就是distribute by和sort by相结合

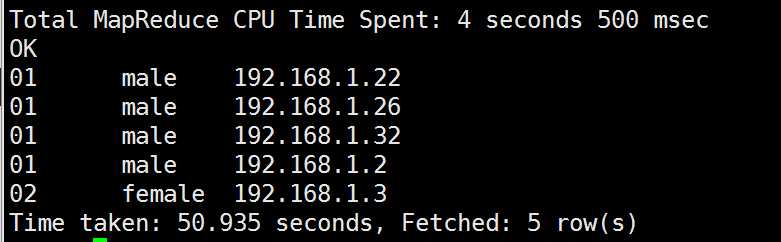

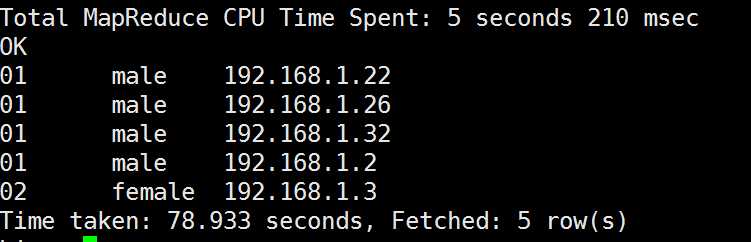
注意:注意被cluster by指定的列只能是降序,不能指定asc和desc。
标签:的区别 number test 数据库 info 外部表 name 字段 相同
原文地址:https://www.cnblogs.com/lyywj170403/p/9429345.html