标签:hone callable 风格 through || final port ret 1.5
Python 自1.5版本起增加了re 模块,它提供 Perl 风格的正则表达式模式。
re 模块使 Python 语言拥有全部的正则表达式功能。
re模块源码
# --------------------------------------------------------------------
# public interface
def match(pattern, string, flags=0):
"""Try to apply the pattern at the start of the string, returning
a match object, or None if no match was found."""
return _compile(pattern, flags).match(string)
def fullmatch(pattern, string, flags=0):
"""Try to apply the pattern to all of the string, returning
a match object, or None if no match was found."""
return _compile(pattern, flags).fullmatch(string)
def search(pattern, string, flags=0):
"""Scan through string looking for a match to the pattern, returning
a match object, or None if no match was found."""
return _compile(pattern, flags).search(string)
def sub(pattern, repl, string, count=0, flags=0):
"""Return the string obtained by replacing the leftmost
non-overlapping occurrences of the pattern in string by the
replacement repl. repl can be either a string or a callable;
if a string, backslash escapes in it are processed. If it is
a callable, it‘s passed the match object and must return
a replacement string to be used."""
return _compile(pattern, flags).sub(repl, string, count)
def subn(pattern, repl, string, count=0, flags=0):
"""Return a 2-tuple containing (new_string, number).
new_string is the string obtained by replacing the leftmost
non-overlapping occurrences of the pattern in the source
string by the replacement repl. number is the number of
substitutions that were made. repl can be either a string or a
callable; if a string, backslash escapes in it are processed.
If it is a callable, it‘s passed the match object and must
return a replacement string to be used."""
return _compile(pattern, flags).subn(repl, string, count)
def split(pattern, string, maxsplit=0, flags=0):
"""Split the source string by the occurrences of the pattern,
returning a list containing the resulting substrings. If
capturing parentheses are used in pattern, then the text of all
groups in the pattern are also returned as part of the resulting
list. If maxsplit is nonzero, at most maxsplit splits occur,
and the remainder of the string is returned as the final element
of the list."""
return _compile(pattern, flags).split(string, maxsplit)
def findall(pattern, string, flags=0):
"""Return a list of all non-overlapping matches in the string.
If one or more capturing groups are present in the pattern, return
a list of groups; this will be a list of tuples if the pattern
has more than one group.
Empty matches are included in the result."""
return _compile(pattern, flags).findall(string)
def finditer(pattern, string, flags=0):
"""Return an iterator over all non-overlapping matches in the
string. For each match, the iterator returns a match object.
Empty matches are included in the result."""
return _compile(pattern, flags).finditer(string)
def compile(pattern, flags=0):
"Compile a regular expression pattern, returning a pattern object."
return _compile(pattern, flags)
def purge():
"Clear the regular expression caches"
_cache.clear()
_compile_repl.cache_clear()
def template(pattern, flags=0):
"Compile a template pattern, returning a pattern object"
return _compile(pattern, flags|T)
re模块各函数参数的含义
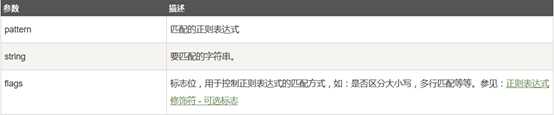
正则表达式修饰符 - 可选标志(flags)
正则表达式可以包含一些可选标志修饰符来控制匹配的模式。修饰符被指定为一个可选的标志。多个标志可以通过按位 OR(|) 它们来指定。如 re.I | re.M 被设置成 I 和 M 标志:
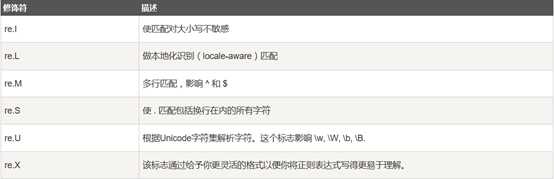
re模块中各种方法
只匹配一个,成功返回Match object, 失败返回None(匹配开头)
完全匹配string,只有pattern和string完全一样才算匹配上,失败返回None
只匹配一个,成功返回Match object, 失败返回None
查找所有匹配成功字符串,并返回list
查找所有匹配字符串, 并返回iterator
按照能够匹配的子串将字符串分割后返回列表,maxsplit表示最大分割次数,默认为0
用于替换字符串中的匹配项
repl : 替换的字符串,也可为一个函数
count : 模式匹配后替换的最大次数,默认 0 表示替换所有的匹配
用于编译正则表达式,生成一个正则表达式( Pattern )对象,供 match() 和 search() 这两个函数使用
与大多数编程语言相同,正则表达式里使用"\"作为转义字符,这就可能造成反斜杠困扰。假如你需要匹配文本中的字符"\",那么使用编程语言表示的正则表达式里将需要4个反斜杠"\\\\":前两个和后两个分别用于在编程语言里转义成反斜杠,转换成两个反斜杠后再在正则表达式里转义成一个反斜杠。Python里的原生字符串很好地解决了这个问题,这个例子中的正则表达式可以使用r"\\"表示。同样,匹配一个数字的"\\d"可以写成r"\d"。有了原生字符串,你再也不用担心是不是漏写了反斜杠,写出来的表达式也更直观。

# =================================匹配模式=================================
#一对一的匹配
# ‘hello‘.replace(old,new)
# ‘hello‘.find(‘pattern‘)
#正则匹配
import re
#\w与\W
print(re.findall(‘\w‘,‘hello egon 123‘)) #[‘h‘, ‘e‘, ‘l‘, ‘l‘, ‘o‘, ‘e‘, ‘g‘, ‘o‘, ‘n‘, ‘1‘, ‘2‘, ‘3‘]
print(re.findall(‘\W‘,‘hello egon 123‘)) #[‘ ‘, ‘ ‘]
#\s与\S
print(re.findall(‘\s‘,‘hello egon 123‘)) #[‘ ‘, ‘ ‘, ‘ ‘, ‘ ‘]
print(re.findall(‘\S‘,‘hello egon 123‘)) #[‘h‘, ‘e‘, ‘l‘, ‘l‘, ‘o‘, ‘e‘, ‘g‘, ‘o‘, ‘n‘, ‘1‘, ‘2‘, ‘3‘]
#\n \t都是空,都可以被\s匹配
print(re.findall(‘\s‘,‘hello \n egon \t 123‘)) #[‘ ‘, ‘\n‘, ‘ ‘, ‘ ‘, ‘\t‘, ‘ ‘]
#\n与\t
print(re.findall(‘\n‘, ‘hello egon \n123‘)) # [‘\n‘]
print(re.findall(r‘\n‘, ‘hello egon \n123‘)) # [‘\n‘]
print(re.findall(‘\t‘, ‘hello egon\t123‘)) # [‘\t‘]
print(re.findall(r‘\t‘, ‘hello egon\t123‘)) # [‘\t‘]
#\d与\D
print(re.findall(‘\d‘,‘hello egon 123‘)) #[‘1‘, ‘2‘, ‘3‘]
print(re.findall(‘\D‘,‘hello egon 123‘)) #[‘h‘, ‘e‘, ‘l‘, ‘l‘, ‘o‘, ‘ ‘, ‘e‘, ‘g‘, ‘o‘, ‘n‘, ‘ ‘]
#\A与\Z
print(re.findall(‘\Ahe‘,‘hello egon 123‘)) #[‘he‘],\A==>^
print(re.findall(‘123\Z‘,‘hello egon 123‘)) #[‘he‘],\Z==>$
#^与$
print(re.findall(‘^h‘,‘hello egon 123‘)) #[‘h‘]
print(re.findall(‘3$‘,‘hello egon 123‘)) #[‘3‘]
# 重复匹配:| . | * | ? | .* | .*? | + | {n,m} |
#.
print(re.findall(‘a.b‘, ‘a1b‘)) # [‘a1b‘]
print(re.findall(‘a.b‘, ‘a1b a*b a b aaab‘)) # [‘a1b‘, ‘a*b‘, ‘a b‘, ‘aab‘]
print(re.findall(‘a.b‘, ‘a\nb‘)) # []
print(re.findall(‘a.b‘, ‘a\nb‘, re.S)) # [‘a\nb‘]
print(re.findall(‘a.b‘, ‘a\nb‘, re.DOTALL)) # [‘a\nb‘]同上一条意思一样
print(re.findall(‘a..b‘, ‘a12b‘)) # [‘a12b‘]两个点可以匹配两个除换行外的任意字符
print(re.findall(‘a...b‘, ‘a123b‘)) # [‘a123b‘]几个点就能匹配几个除换行外的任意字符
#*
print(re.findall(‘ab*‘,‘bbbbbbb‘)) #[]
print(re.findall(‘ab*‘,‘a‘)) #[‘a‘]
print(re.findall(‘ab*‘,‘abbbb‘)) #[‘abbbb‘]
#?
print(re.findall(‘ab?‘,‘a‘)) #[‘a‘]
print(re.findall(‘ab?‘,‘abbb‘)) #[‘ab‘]
#匹配所有包含小数在内的数字
print(re.findall(‘\d+\.?\d*‘,"asdfasdf123as1.13dfa12adsf1asdf3")) #[‘123‘, ‘1.13‘, ‘12‘, ‘1‘, ‘3‘]
#.*默认为贪婪匹配
print(re.findall(‘a.*b‘,‘a1b22222222b‘)) #[‘a1b22222222b‘]
secret_code = ‘hadkfalifexxIxxfasdjifja134xxlovexx23345sdfxxyouxx8dfse‘
re.findall(‘xx.*xx‘, secret_code) # [‘xxIxxfasdjifja134xxlovexx23345sdfxxyouxx‘]
#.*?为非贪婪匹配:推荐使用
print(re.findall(‘a.*?b‘,‘a1b22222222b‘)) #[‘a1b‘]
re.findall(‘xx.*?xx‘, secret_code) # [‘xxIxx‘, ‘xxlovexx‘, ‘xxyouxx‘]
#+
print(re.findall(‘ab+‘,‘a‘)) #[]
print(re.findall(‘ab+‘,‘abbb‘)) #[‘abbb‘]
#{n,m}
print(re.findall(‘ab{2}‘,‘abbb‘)) #[‘abb‘]
print(re.findall(‘ab{2,4}‘,‘abbb‘)) #[‘abb‘]
print(re.findall(‘ab{1,}‘,‘abbb‘)) #‘ab{1,}‘ ===> ‘ab+‘
print(re.findall(‘ab{0,}‘,‘abbb‘)) #‘ab{0,}‘ ===> ‘ab*‘
#[]
print(re.findall(‘a[1*-]b‘,‘a1b a*b a-b‘)) #[]内的都为普通字符了,且如果-没有被转意的话,应该放到[]的开头或结尾
print(re.findall(‘a[^1*-]b‘,‘a1b a*b a-b a=b‘)) #[]内的^代表的意思是取反,所以结果为[‘a=b‘]
print(re.findall(‘a[0-9]b‘,‘a1b a*b a-b a=b‘)) #[]内的^代表的意思是取反,所以结果为[‘a=b‘]
print(re.findall(‘a[a-z]b‘,‘a1b a*b a-b a=b aeb‘)) #[]内的^代表的意思是取反,所以结果为[‘a=b‘]
print(re.findall(‘a[a-zA-Z]b‘,‘a1b a*b a-b a=b aeb aEb‘)) #[]内的^代表的意思是取反,所以结果为[‘a=b‘]
#\# print(re.findall(‘a\\c‘,‘a\c‘)) #对于正则来说a\\c确实可以匹配到a\c,但是在python解释器读取a\\c时,会发生转义,然后交给re去执行,所以抛出异常
print(re.findall(r‘a\\c‘,‘a\c‘)) #r代表告诉解释器使用rawstring,即原生字符串,把我们正则内的所有符号都当普通字符处理,不要转义
print(re.findall(‘a\\\\c‘,‘a\c‘)) #同上面的意思一样,和上面的结果一样都是[‘a\\c‘]
#():分组 findall和search的分组匹配结果不同,请注意
print(re.findall(‘ab+‘,‘ababab123‘)) #[‘ab‘, ‘ab‘, ‘ab‘]
print(re.findall(‘(ab)+123‘,‘ababab123‘)) #[‘ab‘],匹配到末尾的ab123中的ab
print(re.findall(‘(?:ab)+123‘,‘ababab123‘)) #findall的结果不是匹配的全部内容,而是组内的内容,?:可以让结果为匹配的全部内容
print(re.findall(‘href="(.*?)"‘,‘<a href="http://www.baidu.com">点击</a>‘))#[‘http://www.baidu.com‘]
print(re.findall(‘href="(?:.*?)"‘,‘<a href="http://www.baidu.com">点击</a>‘))#[‘href="http://www.baidu.com"‘]
print(re.search(‘(dsf){2}(\|\|=){1}‘,‘adsfdsf||=‘)) # _sre.SRE_Match object; span=(1, 10), match=‘dsfdsf||=‘>
print(re.findall(‘(dsf){2}(\|\|=){1}‘,‘adsfdsf||=‘)) # [(‘dsf‘, ‘||=‘)]
‘(?P<name>...)‘ 分组匹配 re.search("(?P<province>[0-9]{4})(?P<city>[0-9]{2})(?P<birthday>[0-9]{4})","371481199306143242").groupdict("city") 结果{‘province‘: ‘3714‘, ‘city‘: ‘81‘, ‘birthday‘: ‘1993‘}
#|
print(re.findall(‘compan(?:y|ies)‘,‘Too many companies have gone bankrupt, and the next one is my company‘))
re模块的各函数
re.match 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none。
匹配成功re.match方法返回一个匹配的对象,否则返回None。
我们可以使用group(num) 或 groups() 匹配对象函数来获取匹配表达式。
| 匹配对象方法 | 描述 |
|---|---|
| group(num=0) | 匹配的整个表达式的字符串,group() 可以一次输入多个组号,在这种情况下它将返回一个包含那些组所对应值的元组。 |
| groups() | 返回一个包含所有小组字符串的元组,从 1 到 所含的小组号。 |
实例
import re
line = "Cats are smarter than dogs"
matchObj = re.match(r‘(.*) are (.*?) .*‘, line, re.M | re.I)
if matchObj:
print("matchObj.group() : ", matchObj.group())
print("matchObj.group(1) : ", matchObj.group(1))
print("matchObj.group(2) : ", matchObj.group(2))
# print("matchObj.group(3) : ", matchObj.group(3)) # 只匹配了俩没有第三个
else:
print("No match!!")
以上实例执行结果如下:
matchObj.group() : Cats are smarter than dogs matchObj.group(1) : Cats matchObj.group(2) : smarter
re.search 扫描整个字符串并返回第一个成功的匹配。
re.match与re.search的区别
re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;而re.search匹配整个字符串,直到找到一个匹配。
import re
line = "Cats are smarter than dogs";
matchObj = re.match( r‘dogs‘, line, re.M|re.I)
if matchObj:
print ("match --> matchObj.group() : ", matchObj.group())
else:
print ("No match!!")
matchObj = re.search( r‘dogs‘, line, re.M|re.I)
if matchObj:
print ("search --> matchObj.group() : ", matchObj.group())
else:
print ("No match!!")
re.sub(pattern, repl, string, count=0) 用于替换字符串中的匹配项。
import re
phone = "2004-959-559 # 这是一个电话号码"
# 删除注释
num = re.sub(r‘#.*$‘, "", phone)
print ("电话号码 : ", num)
# 移除非数字的内容
num = re.sub(r‘\D‘, "", phone)
print ("电话号码 : ", num)
电话号码 : 2004-959-559
电话号码 : 2004959559
标签:hone callable 风格 through || final port ret 1.5
原文地址:https://www.cnblogs.com/wlx97e6/p/9389046.html