标签:好的 tps tom inf nbsp 信息 类别 似然函数 特征
最大似然估计(Maximum likelihood estimation, 简称MLE)和最大后验概率估计(Maximum aposteriori estimation, 简称MAP)是很常用的两种参数估计方法。
1、最大似然估计(MLE)
在已知试验结果(即是样本)的情况下,用来估计满足这些样本分布的参数,把可能性最大的那个参数作为真实的参数估计。
也就是说,最大似然估计,就是利用已知的样本结果,反推最有可能(最大概率)导致这样结果的参数值(模型已知,参数未知)。
(1)基本思想
当从模型总体随机抽取n组样本观测值后,最合理的参数估计量应该使得从模型中抽取该n组样本观测值的概率最大,而不是像最小二乘估计法旨在得到使得模型能最好地拟合样本数据的参数估计量。
例如,我们知道这个分布是正态分布,但是不知道均值和方差;或者是二项分布,但是不知道均值。 最大似然估计(MLE,Maximum Likelihood Estimation)就可以用来估计模型的参数。MLE的目标是找出一组参数,使得模型产生出观测数据的概率最大。
(2)模型推导
假设样本集D={x1 、x2 、…、xn},假设样本之间都是相对独立的,注意这个假设很重要!于是便有:
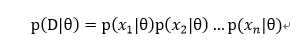
所以假设似然函数为:
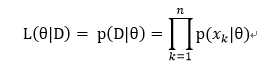
接下来我们求参的准则便是如名字一样最大化似然函数:
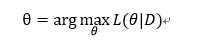
如果求得的θ 是参数空间中能使似然函数最大的取值,则θ是最可能的参数取值,即最大的似然估计值。
似然函数取对数:就是防止先验概率为0,那么上面的L(θ|D)整个式子便都成0 了,那肯定是不行的啊,不能因为一个数据误差影响了整个数据的使用。同时那么多先验概率相乘,可能出现下溢出。所以引入拉普拉斯修正,也就是取对数ln,想必大家在数学中都用过这种方法的。
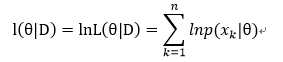
所以最大化的目标便是:
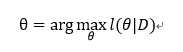
之后对参数求偏导,偏导数为0,求解最优值。
求最大似然函数估计值的一般步骤:
(1) 写出似然函数
(2) 对似然函数取对数,并整理
(3) 求导数
(4) 解似然方程
(3)推导举例
我们拿这枚硬币抛了10次,得到的数据(x0)是:反正正正正反正正正反。我们想求的正面概率θθ是模型参数,而抛硬币模型我们可以假设是 二项分布。那么,出现实验结果x0(即反正正正正反正正正反)的似然函数是多少呢?

对似然函数求对数,得到对数似然函数后对参数θ求导,令导数为0,求解θ的值。此处求得θ=0.7。
(4)最大似然估计的特点:
1.比其他估计方法更加简单;
2.收敛性:无偏或者渐近无偏,当样本数目增加时,收敛性质会更好;
3.如果假设的类条件概率模型正确,则通常能获得较好的结果。但如果假设模型出现偏差,将导致非常差的估计结果。
2、贝叶斯估计
贝叶斯统计的重点:参数未知且不确定,因此作为随机变量,参数本身也是一个分布,同时,根据已有的信息可以得到参数θ的先验概率,根据先验概率来推断θ的后验概率。
不同于ML估计,不再把参数θ看成一个未知的确定变量,而是看成未知的随机变量,通过对第i类样本Di的观察,使概率密度分布P(Di|θ)转化为后验概率P(θ|Di),再求贝叶斯估计。
贝叶斯估计是在MAP上做进一步拓展,此时不直接估计参数的值,而是允许参数服从一定概率分布。极大似然估计和极大后验概率估计,都求出了参数theta的值,而贝叶斯推断则不是,贝叶斯推断扩展了极大后验概率估计MAP(一个是等于,一个是约等于)方法,它根据参数的先验分布P(theta)和一系列观察X,求出参数theta的后验分布P(theta|X),然后求出theta的期望值,作为其最终值。另外还定义了参数的一个方差量,来评估参数估计的准确程度或者置信度。
贝叶斯估计:从参数的先验知识和样本出发。期望后延信息在真实的θ值处有一个尖峰。
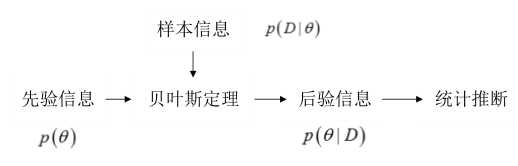
贝叶斯公式:
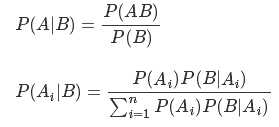
根据特征条件独立性假设:其中X 是多个特征的矩阵,Y 是类别标签
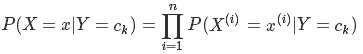
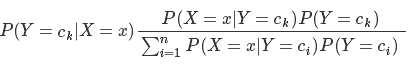
我们可以计算出任一样本x属于类别的概率,选择其中概率最大者便可作为其分类的类标。
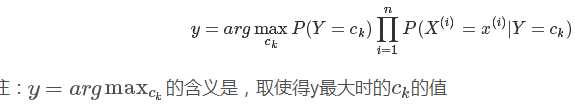
基本步骤:

3、似然函数和概率函数
概率研究的问题是,已知一个模型和参数,怎么去预测这个模型产生的结果的特性(例如均值,方差,协方差等等)。统计是,有一堆数据,要利用这堆数据去预测模型和参数。
概率是已知模型和参数,推数据。统计是已知数据,推模型和参数。
在统计里面,似然函数和概率函数却是两个不同的概念(其实也很相近就是了)。
对于这个函数:P(x|θ)。输入有两个:x表示某一个具体的数据;θ表示模型的参数。
如果θ是已知确定的,x是变量,这个函数叫做概率函数(probability function),它描述对于不同的样本点x,其出现概率是多少。
如果x是已知确定的,θ是变量,这个函数叫做似然函数(likelihood function), 它描述对于不同的模型参数,出现x这个样本点的概率是多少。
4、最大后验概率估计(MAP)
最大似然估计是求参数θ, 使似然函数P(x0|θ)最大。
最大后验概率估计则是想求θ使P(x0|θ)P(θ)最大。求得的θ不单单让似然函数大,θ自己出现的先验概率也得大。
最大后验概率估计是最大似然和贝叶斯估计的结合,

其实如果MAP的后验概率中P(θ) = 1,就是最大似然概率。也就是说最大似然概率默认未知参数 θ 取值都是等可能性的,而最大后验概率在参数估计时考虑了参数的先验概率。
4、对比总结
参考:https://blog.csdn.net/u011508640/article/details/72815981
机器学习(二十五)— 极大似然估计、贝叶斯估计、最大后验概率估计区别
标签:好的 tps tom inf nbsp 信息 类别 似然函数 特征
原文地址:https://www.cnblogs.com/eilearn/p/9433911.html