标签:后台 encoding ref 辅助 aci 存在 mongodb python爬虫 int
假设有四台电脑:Windows 10、Mac OS X、Ubuntu 16.04、CentOS 7.2,任意一台电脑都可以作为 Master端 或 Slaver端,比如:
Master端(核心服务器) :使用 Windows 10,搭建一个Redis数据库,不负责爬取,只负责url指纹判重、Request的分配,以及数据的存储
Slaver端(爬虫程序执行端) :使用 Mac OS X 、Ubuntu 16.04、CentOS 7.2,负责执行爬虫程序,运行过程中提交新的Request给Master
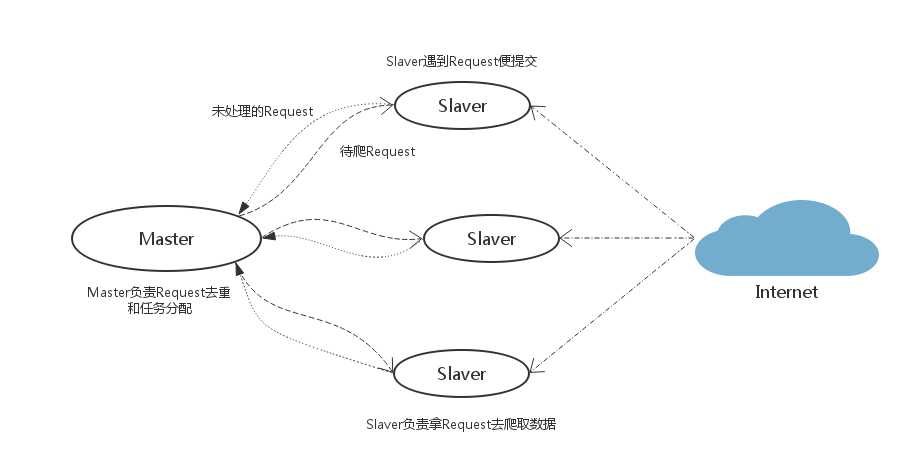
首先Slaver端从Master端拿任务(Request、url)进行数据抓取,Slaver抓取数据的同时,产生新任务的Request便提交给 Master 处理;
Master端只有一个Redis数据库,负责将未处理的Request去重和任务分配,将处理后的Request加入待爬队列,并且存储爬取的数据。
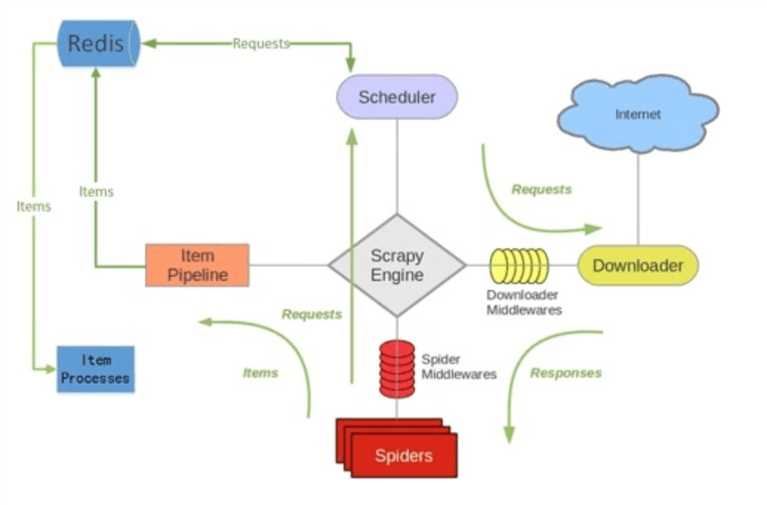
Scrapy-Redis默认使用的就是这种策略,我们实现起来很简单,因为任务调度等工作Scrapy-Redis都已经帮我们做好了,我们只需要继承RedisSpider、指定redis_key就行了。
缺点是,Scrapy-Redis调度的任务是Request对象,里面信息量比较大(不仅包含url,还有callback函数、headers等信息),可能导致的结果就是会降低爬虫速度、而且会占用Redis大量的存储空间,所以如果要保证效率,那么就需要一定硬件水平。
安装Redis:http://redis.io/download
安装完成后,拷贝一份Redis安装目录下的redis.conf到任意目录,建议保存到:/etc/redis/redis.conf(Windows系统可以无需变动)
打开你的redis.conf配置文件,示例:
非Windows系统: sudo vi /etc/redis/redis.conf
Windows系统:C:\Intel\Redis\conf\redis.conf
Master端redis.conf里注释bind 127.0.0.1,Slave端才能远程连接到Master端的Redis数据库。

2.daemonize yno表示Redis默认不作为守护进程运行,即在运行redis-server /etc/redis/redis.conf时,将显示Redis启动提示画面;
daemonize yes则默认后台运行,不必重新启动新的终端窗口执行其他命令,看个人喜好和实际需要。
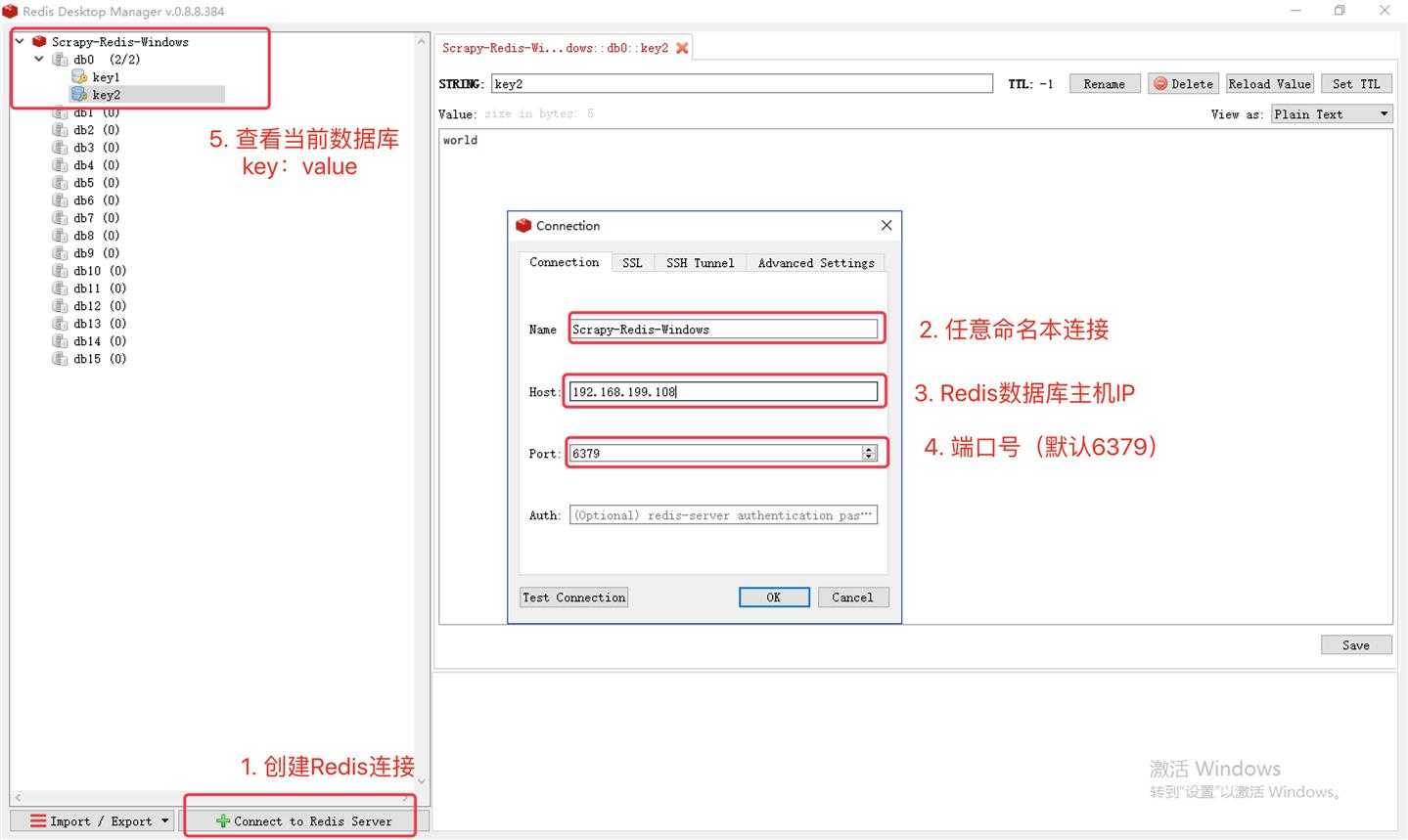
测试中,Master端Windows 10 的IP地址为:192.168.199.108
Master端按指定配置文件启动 redis-server,示例:
非Windows系统:sudo redis-server /etc/redis/redis/conf
Windows系统:命令提示符(管理员)模式下执行 redis-server C:\Intel\Redis\conf\redis.conf读取默认配置即可。
Master端启动本地redis-cli:
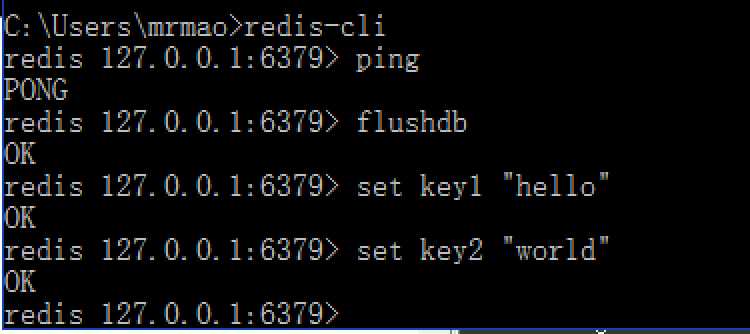
3.slave端启动redis-cli -h 192.168.199.108,-h 参数表示连接到指定主机的redis数据库
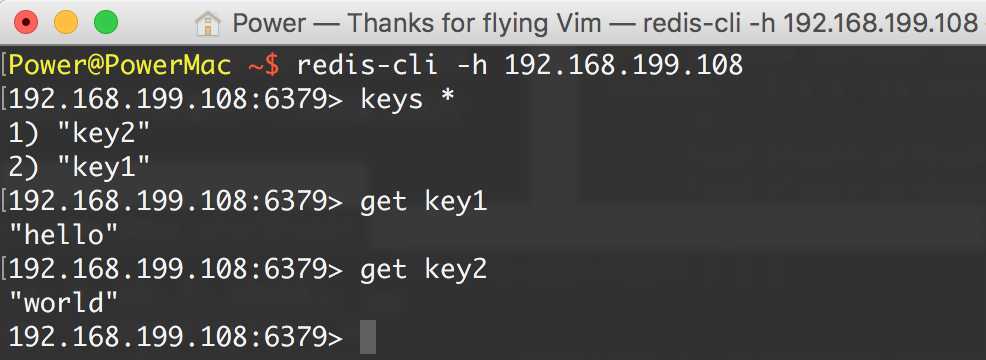
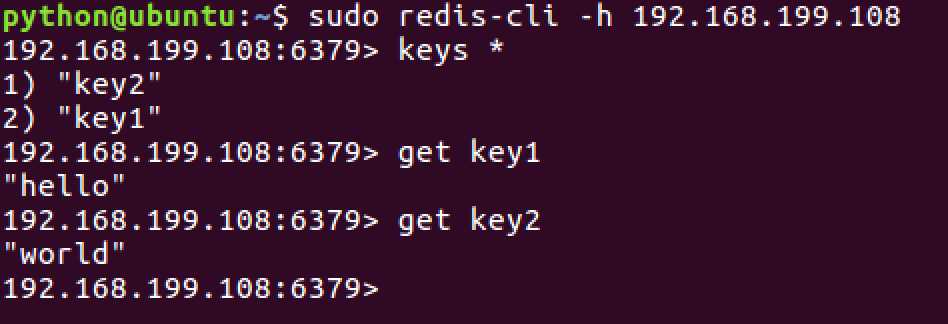
redis-server,Master端启动即可。只要 Slave 端读取到了 Master 端的 Redis 数据库,则表示能够连接成功,可以实施分布式。这里推荐 Redis Desktop Manager,支持 Windows、Mac OS X、Linux 等平台:
下载地址:https://redisdesktop.com/download
先从github上拿到scrapy-redis的示例,然后将里面的example-project目录移到指定的地址:
# clone github scrapy-redis源码文件 git clone https://github.com/rolando/scrapy-redis.git # 直接拿官方的项目范例,改名为自己的项目用(针对懒癌患者) mv scrapy-redis/example-project ~/scrapyredis-project
我们clone到的 scrapy-redis 源码中有自带一个example-project项目,这个项目包含3个spider,分别是dmoz, myspider_redis,mycrawler_redis。
这个爬虫继承的是CrawlSpider,它是用来说明Redis的持续性,当我们第一次运行dmoz爬虫,然后Ctrl + C停掉之后,再运行dmoz爬虫,之前的爬取记录是保留在Redis里的。
分析起来,其实这就是一个 scrapy-redis 版 CrawlSpider 类,需要设置Rule规则,以及callback不能写parse()方法。
scrapy crawl dmozfrom scrapy.linkextractors import LinkExtractor from scrapy.spiders import CrawlSpider, Rule class DmozSpider(CrawlSpider): """Follow categories and extract links.""" name = ‘dmoz‘ allowed_domains = [‘dmoz.org‘] start_urls = [‘http://www.dmoz.org/‘] rules = [ Rule(LinkExtractor( restrict_css=(‘.top-cat‘, ‘.sub-cat‘, ‘.cat-item‘) ), callback=‘parse_directory‘, follow=True), ] def parse_directory(self, response): for div in response.css(‘.title-and-desc‘): yield { ‘name‘: div.css(‘.site-title::text‘).extract_first(), ‘description‘: div.css(‘.site-descr::text‘).extract_first().strip(), ‘link‘: div.css(‘a::attr(href)‘).extract_first(), }
这个爬虫继承了RedisSpider, 它能够支持分布式的抓取,采用的是basic spider,需要写parse函数。
其次就是不再有start_urls了,取而代之的是redis_key,scrapy-redis将key从Redis里pop出来,成为请求的url地址。
from scrapy_redis.spiders import RedisSpider class MySpider(RedisSpider): """Spider that reads urls from redis queue (myspider:start_urls).""" name = ‘myspider_redis‘ # 注意redis-key的格式: redis_key = ‘myspider:start_urls‘ # 可选:等效于allowd_domains(),__init__方法按规定格式写,使用时只需要修改super()里的类名参数即可 def __init__(self, *args, **kwargs): # Dynamically define the allowed domains list. domain = kwargs.pop(‘domain‘, ‘‘) self.allowed_domains = filter(None, domain.split(‘,‘)) # 修改这里的类名为当前类名 super(MySpider, self).__init__(*args, **kwargs) def parse(self, response): return { ‘name‘: response.css(‘title::text‘).extract_first(), ‘url‘: response.url, }
RedisSpider类 不需要写allowd_domains和start_urls:
scrapy-redis将从在构造方法__init__()里动态定义爬虫爬取域范围,也可以选择直接写allowd_domains。
必须指定redis_key,即启动爬虫的命令,参考格式:redis_key = ‘myspider:start_urls‘
根据指定的格式,start_urls将在 Master端的 redis-cli 里 lpush 到 Redis数据库里,RedisSpider 将在数据库里获取start_urls。
通过runspider方法执行爬虫的py文件(也可以分次执行多条),爬虫(们)将处于等待准备状态:
scrapy runspider myspider_redis.py在Master端的redis-cli输入push指令,参考格式:
$redis > lpush myspider:start_urls http://www.dmoz.org/Slaver端爬虫获取到请求,开始爬取。
这个RedisCrawlSpider类爬虫继承了RedisCrawlSpider,能够支持分布式的抓取。因为采用的是crawlSpider,所以需要遵守Rule规则,以及callback不能写parse()方法。
同样也不再有start_urls了,取而代之的是redis_key,scrapy-redis将key从Redis里pop出来,成为请求的url地址。
from scrapy.spiders import Rule from scrapy.linkextractors import LinkExtractor from scrapy_redis.spiders import RedisCrawlSpider class MyCrawler(RedisCrawlSpider): """Spider that reads urls from redis queue (myspider:start_urls).""" name = ‘mycrawler_redis‘ redis_key = ‘mycrawler:start_urls‘ rules = ( # follow all links Rule(LinkExtractor(), callback=‘parse_page‘, follow=True), ) # __init__方法必须按规定写,使用时只需要修改super()里的类名参数即可 def __init__(self, *args, **kwargs): # Dynamically define the allowed domains list. domain = kwargs.pop(‘domain‘, ‘‘) self.allowed_domains = filter(None, domain.split(‘,‘)) # 修改这里的类名为当前类名 super(MyCrawler, self).__init__(*args, **kwargs) def parse_page(self, response): return { ‘name‘: response.css(‘title::text‘).extract_first(), ‘url‘: response.url, }
同样的,RedisCrawlSpider类不需要写allowd_domains和start_urls:
scrapy-redis将从在构造方法__init__()里动态定义爬虫爬取域范围,也可以选择直接写allowd_domains。
必须指定redis_key,即启动爬虫的命令,参考格式:redis_key = ‘myspider:start_urls‘
根据指定的格式,start_urls将在 Master端的 redis-cli 里 lpush 到 Redis数据库里,RedisSpider 将在数据库里获取start_urls。
通过runspider方法执行爬虫的py文件(也可以分次执行多条),爬虫(们)将处于等待准备状态:
scrapy runspider mycrawler_redis.py在Master端的redis-cli输入push指令,参考格式:
$redis > lpush mycrawler:start_urls http://www.dmoz.org/爬虫获取url,开始执行。
如果只是用到Redis的去重和保存功能,就选第一种;
如果要写分布式,则根据情况,选择第二种、第三种;
通常情况下,会选择用第三种方式编写深度聚焦爬虫。
# clone github scrapy-redis源码文件 git clone https://github.com/rolando/scrapy-redis.git # 直接拿官方的项目范例,改名为自己的项目用(针对懒癌患者) mv scrapy-redis/example-project ~/scrapy-youyuan
下面列举了修改后的配置文件中与scrapy-redis有关的部分,middleware、proxy等内容在此就省略了。
# -*- coding: utf-8 -*- # 指定使用scrapy-redis的调度器 SCHEDULER = "scrapy_redis.scheduler.Scheduler" # 指定使用scrapy-redis的去重 DUPEFILTER_CLASS = ‘scrapy_redis.dupefilters.RFPDupeFilter‘ # 指定排序爬取地址时使用的队列, # 默认的 按优先级排序(Scrapy默认),由sorted set实现的一种非FIFO、LIFO方式。 SCHEDULER_QUEUE_CLASS = ‘scrapy_redis.queue.SpiderPriorityQueue‘ # 可选的 按先进先出排序(FIFO) # SCHEDULER_QUEUE_CLASS = ‘scrapy_redis.queue.SpiderQueue‘ # 可选的 按后进先出排序(LIFO) # SCHEDULER_QUEUE_CLASS = ‘scrapy_redis.queue.SpiderStack‘ # 在redis中保持scrapy-redis用到的各个队列,从而允许暂停和暂停后恢复,也就是不清理redis queues SCHEDULER_PERSIST = True # 只在使用SpiderQueue或者SpiderStack是有效的参数,指定爬虫关闭的最大间隔时间 # SCHEDULER_IDLE_BEFORE_CLOSE = 10 # 通过配置RedisPipeline将item写入key为 spider.name : items 的redis的list中,供后面的分布式处理item # 这个已经由 scrapy-redis 实现,不需要我们写代码 ITEM_PIPELINES = { ‘example.pipelines.ExamplePipeline‘: 300, ‘scrapy_redis.pipelines.RedisPipeline‘: 400 } # 指定redis数据库的连接参数 # REDIS_PASS是我自己加上的redis连接密码(默认不做) REDIS_HOST = ‘127.0.0.1‘ REDIS_PORT = 6379 #REDIS_PASS = ‘redisP@ssw0rd‘ # LOG等级 LOG_LEVEL = ‘DEBUG‘ #默认情况下,RFPDupeFilter只记录第一个重复请求。将DUPEFILTER_DEBUG设置为True会记录所有重复的请求。 DUPEFILTER_DEBUG =True # 覆盖默认请求头,可以自己编写Downloader Middlewares设置代理和UserAgent DEFAULT_REQUEST_HEADERS = { ‘Accept‘: ‘text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8‘, ‘Accept-Language‘: ‘zh-CN,zh;q=0.8‘, ‘Connection‘: ‘keep-alive‘, ‘Accept-Encoding‘: ‘gzip, deflate, sdch‘ }
# -*- coding: utf-8 -*- from datetime import datetime class ExamplePipeline(object): def process_item(self, item, spider): #utcnow() 是获取UTC时间 item["crawled"] = datetime.utcnow() # 爬虫名 item["spider"] = spider.name return item
增加我们最后要保存的youyuanItem项,这里只写出来一个非常简单的版本
# -*- coding: utf-8 -*- from scrapy.item import Item, Field class youyuanItem(Item): # 个人头像链接 header_url = Field() # 用户名 username = Field() # 内心独白 monologue = Field() # 相册图片链接 pic_urls = Field() # 年龄 age = Field() # 网站来源 youyuan source = Field() # 个人主页源url source_url = Field() # 获取UTC时间 crawled = Field() # 爬虫名 spider = Field()
在spiders目录下增加youyuan.py文件编写我们的爬虫,之后就可以运行爬虫了。 这里的提供一个简单的版本:
# -*- coding:utf-8 -*- from scrapy.linkextractors import LinkExtractor from scrapy.spiders import CrawlSpider, Rule # 使用redis去重 from scrapy.dupefilters import RFPDupeFilter from example.items import youyuanItem import re # class YouyuanSpider(CrawlSpider): name = ‘youyuan‘ allowed_domains = [‘youyuan.com‘] # 有缘网的列表页 start_urls = [‘http://www.youyuan.com/find/beijing/mm18-25/advance-0-0-0-0-0-0-0/p1/‘] # 搜索页面匹配规则,根据response提取链接 list_page_lx = LinkExtractor(allow=(r‘http://www.youyuan.com/find/.+‘)) # 北京、18~25岁、女性 的 搜索页面匹配规则,根据response提取链接 page_lx = LinkExtractor(allow =(r‘http://www.youyuan.com/find/beijing/mm18-25/advance-0-0-0-0-0-0-0/p\d+/‘)) # 个人主页 匹配规则,根据response提取链接 profile_page_lx = LinkExtractor(allow=(r‘http://www.youyuan.com/\d+-profile/‘)) rules = ( # 匹配find页面,跟进链接,跳板 Rule(list_page_lx, follow=True), # 匹配列表页成功,跟进链接,跳板 Rule(page_lx, follow=True), # 匹配个人主页的链接,形成request保存到redis中等待调度,一旦有响应则调用parse_profile_page()回调函数处理,不做继续跟进 Rule(profile_page_lx, callback=‘parse_profile_page‘, follow=False), ) # 处理个人主页信息,得到我们要的数据 def parse_profile_page(self, response): item = youyuanItem() item[‘header_url‘] = self.get_header_url(response) item[‘username‘] = self.get_username(response) item[‘monologue‘] = self.get_monologue(response) item[‘pic_urls‘] = self.get_pic_urls(response) item[‘age‘] = self.get_age(response) item[‘source‘] = ‘youyuan‘ item[‘source_url‘] = response.url #print "Processed profile %s" % response.url yield item # 提取头像地址 def get_header_url(self, response): header = response.xpath(‘//dl[@class=\‘personal_cen\‘]/dt/img/@src‘).extract() if len(header) > 0: header_url = header[0] else: header_url = "" return header_url.strip() # 提取用户名 def get_username(self, response): usernames = response.xpath("//dl[@class=\‘personal_cen\‘]/dd/div/strong/text()").extract() if len(usernames) > 0: username = usernames[0] else: username = "NULL" return username.strip() # 提取内心独白 def get_monologue(self, response): monologues = response.xpath("//ul[@class=\‘requre\‘]/li/p/text()").extract() if len(monologues) > 0: monologue = monologues[0] else: monologue = "NULL" return monologue.strip() # 提取相册图片地址 def get_pic_urls(self, response): pic_urls = [] data_url_full = response.xpath(‘//li[@class=\‘smallPhoto\‘]/@data_url_full‘).extract() if len(data_url_full) <= 1: pic_urls.append(""); else: for pic_url in data_url_full: pic_urls.append(pic_url) if len(pic_urls) <= 1: return "NULL" # 每个url用|分隔 return ‘|‘.join(pic_urls) # 提取年龄 def get_age(self, response): age_urls = response.xpath("//dl[@class=\‘personal_cen\‘]/dd/p[@class=\‘local\‘]/text()").extract() if len(age_urls) > 0: age = age_urls[0] else: age = "0" age_words = re.split(‘ ‘, age) if len(age_words) <= 2: return "0" age = age_words[2][:-1] # 从age字符串开始匹配数字,失败返回None if re.compile(r‘[0-9]‘).match(age): return age return "0"
redis-serverscrapy crawl youyuan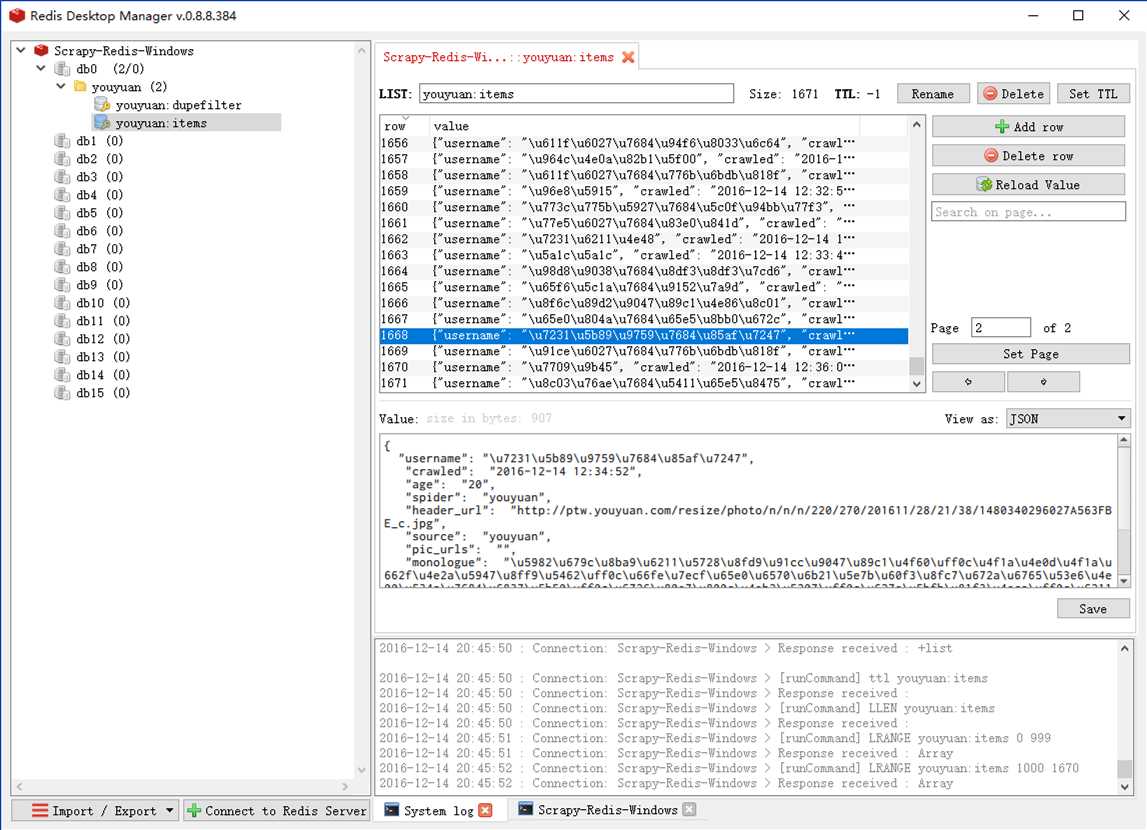
在spiders目录下增加youyuan.py文件编写我们的爬虫,使其具有分布式:
# -*- coding:utf-8 -*- from scrapy.linkextractors import LinkExtractor #from scrapy.spiders import CrawlSpider, Rule # 1. 导入RedisCrawlSpider类,不使用CrawlSpider from scrapy_redis.spiders import RedisCrawlSpider from scrapy.spiders import Rule from scrapy.dupefilters import RFPDupeFilter from example.items import youyuanItem import re # 2. 修改父类 RedisCrawlSpider # class YouyuanSpider(CrawlSpider): class YouyuanSpider(RedisCrawlSpider): name = ‘youyuan‘ # 3. 取消 allowed_domains() 和 start_urls ##### allowed_domains = [‘youyuan.com‘] ##### start_urls = [‘http://www.youyuan.com/find/beijing/mm18-25/advance-0-0-0-0-0-0-0/p1/‘] # 4. 增加redis-key redis_key = ‘youyuan:start_urls‘ list_page_lx = LinkExtractor(allow=(r‘http://www.youyuan.com/find/.+‘)) page_lx = LinkExtractor(allow =(r‘http://www.youyuan.com/find/beijing/mm18-25/advance-0-0-0-0-0-0-0/p\d+/‘)) profile_page_lx = LinkExtractor(allow=(r‘http://www.youyuan.com/\d+-profile/‘)) rules = ( Rule(list_page_lx, follow=True), Rule(page_lx, follow=True), Rule(profile_page_lx, callback=‘parse_profile_page‘, follow=False), ) # 5. 增加__init__()方法,动态获取allowed_domains() def __init__(self, *args, **kwargs): domain = kwargs.pop(‘domain‘, ‘‘) self.allowed_domains = filter(None, domain.split(‘,‘)) super(youyuanSpider, self).__init__(*args, **kwargs) # 处理个人主页信息,得到我们要的数据 def parse_profile_page(self, response): item = youyuanItem() item[‘header_url‘] = self.get_header_url(response) item[‘username‘] = self.get_username(response) item[‘monologue‘] = self.get_monologue(response) item[‘pic_urls‘] = self.get_pic_urls(response) item[‘age‘] = self.get_age(response) item[‘source‘] = ‘youyuan‘ item[‘source_url‘] = response.url yield item # 提取头像地址 def get_header_url(self, response): header = response.xpath(‘//dl[@class=\‘personal_cen\‘]/dt/img/@src‘).extract() if len(header) > 0: header_url = header[0] else: header_url = "" return header_url.strip() # 提取用户名 def get_username(self, response): usernames = response.xpath("//dl[@class=\‘personal_cen\‘]/dd/div/strong/text()").extract() if len(usernames) > 0: username = usernames[0] else: username = "NULL" return username.strip() # 提取内心独白 def get_monologue(self, response): monologues = response.xpath("//ul[@class=\‘requre\‘]/li/p/text()").extract() if len(monologues) > 0: monologue = monologues[0] else: monologue = "NULL" return monologue.strip() # 提取相册图片地址 def get_pic_urls(self, response): pic_urls = [] data_url_full = response.xpath(‘//li[@class=\‘smallPhoto\‘]/@data_url_full‘).extract() if len(data_url_full) <= 1: pic_urls.append(""); else: for pic_url in data_url_full: pic_urls.append(pic_url) if len(pic_urls) <= 1: return "NULL" return ‘|‘.join(pic_urls) # 提取年龄 def get_age(self, response): age_urls = response.xpath("//dl[@class=\‘personal_cen\‘]/dd/p[@class=\‘local\‘]/text()").extract() if len(age_urls) > 0: age = age_urls[0] else: age = "0" age_words = re.split(‘ ‘, age) if len(age_words) <= 2: return "0" age = age_words[2][:-1] if re.compile(r‘[0-9]‘).match(age): return age return "0"
redis-server
scrapy runspider youyuan.py
redis-cli> lpush youyuan:start_urls http://www.youyuan.com/find/beijing/mm18-25/advance-0-0-0-0-0-0-0/p1/
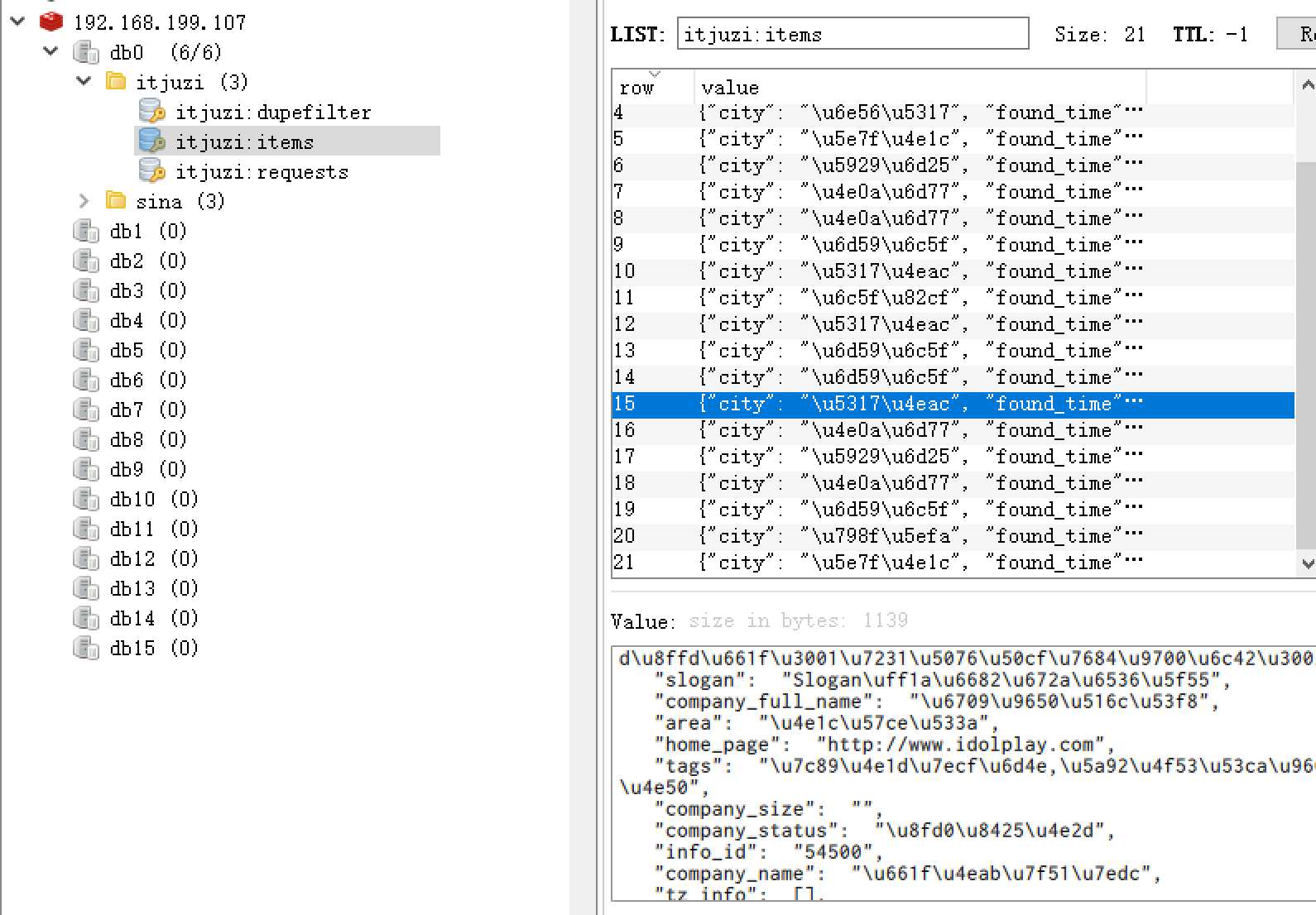
有缘网的数据爬回来了,但是放在Redis里没有处理。之前我们配置文件里面没有定制自己的ITEM_PIPELINES,而是使用了RedisPipeline,所以现在这些数据都被保存在redis的youyuan:items键中,所以我们需要另外做处理。
在scrapy-youyuan目录下可以看到一个process_items.py文件,这个文件就是scrapy-redis的example提供的从redis读取item进行处理的模版。
假设我们要把youyuan:items中保存的数据读出来写进MongoDB或者MySQL,那么我们可以自己写一个process_youyuan_profile.py文件,然后保持后台运行就可以不停地将爬回来的数据入库了。
启动MongoDB数据库:sudo mongod
执行下面程序:py2 process_youyuan_mongodb.py
# process_youyuan_mongodb.py # -*- coding: utf-8 -*- import json import redis import pymongo def main(): # 指定Redis数据库信息 rediscli = redis.StrictRedis(host=‘192.168.199.108‘, port=6379, db=0) # 指定MongoDB数据库信息 mongocli = pymongo.MongoClient(host=‘localhost‘, port=27017) # 创建数据库名 db = mongocli[‘youyuan‘] # 创建表名 sheet = db[‘beijing_18_25‘] while True: # FIFO模式为 blpop,LIFO模式为 brpop,获取键值 source, data = rediscli.blpop(["youyuan:items"]) item = json.loads(data) sheet.insert(item) try: print u"Processing: %(name)s <%(link)s>" % item except KeyError: print u"Error procesing: %r" % item if __name__ == ‘__main__‘:
main()
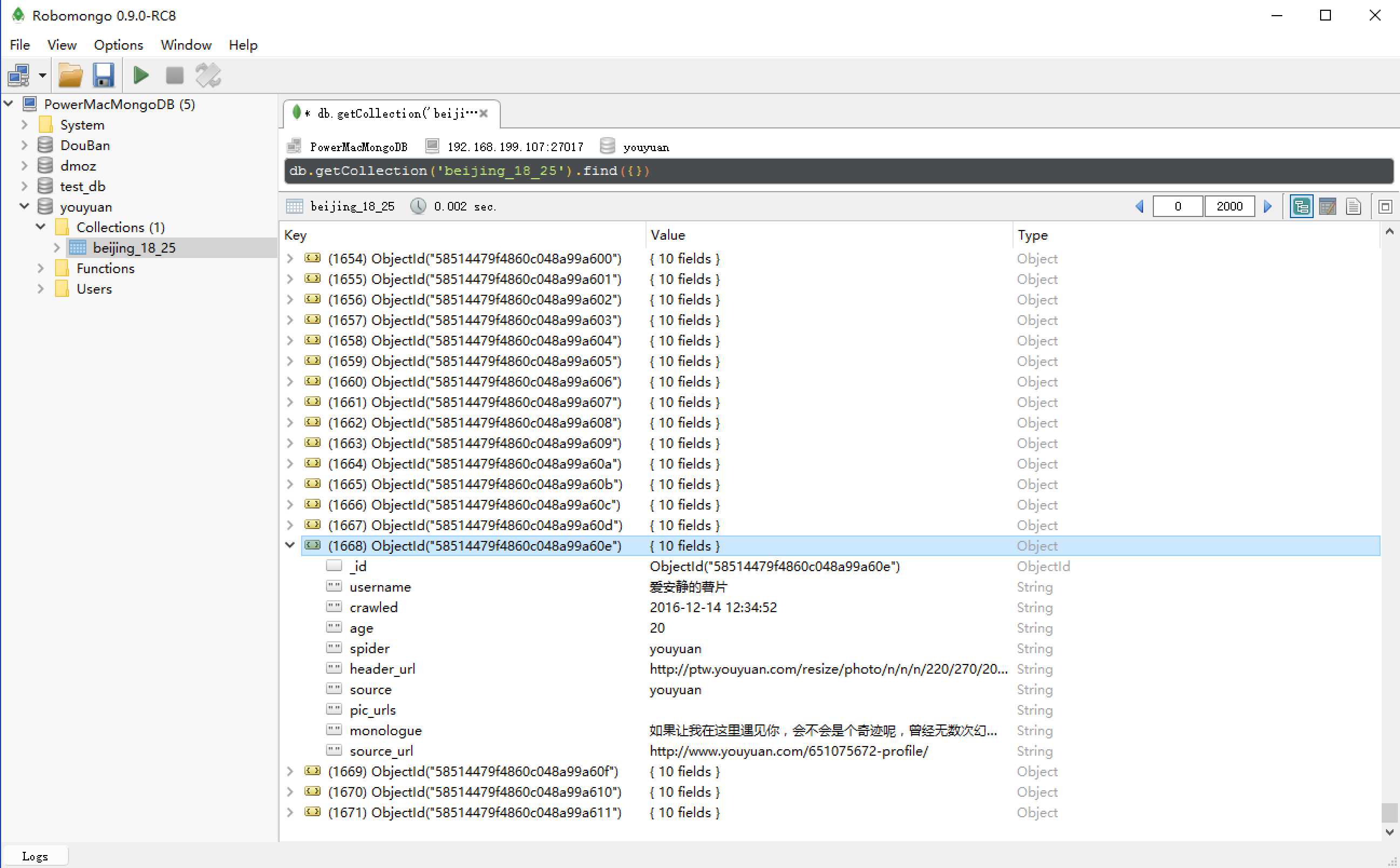
mysql.server start(更平台不一样)mysql -uroot -pyouyuan:create database youyuan;use youyuan创建表beijing_18_25以及所有字段的列名和数据类型。
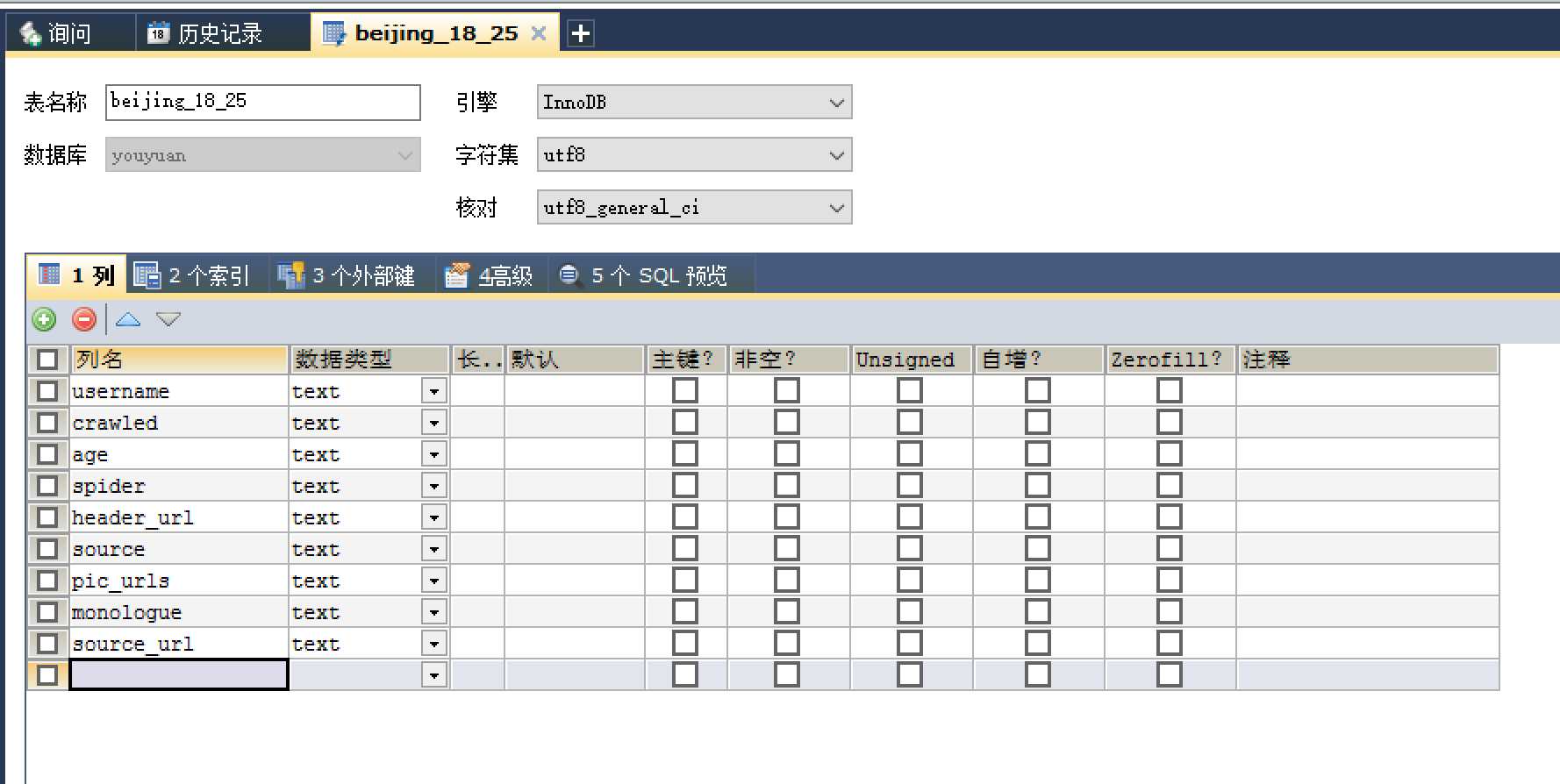
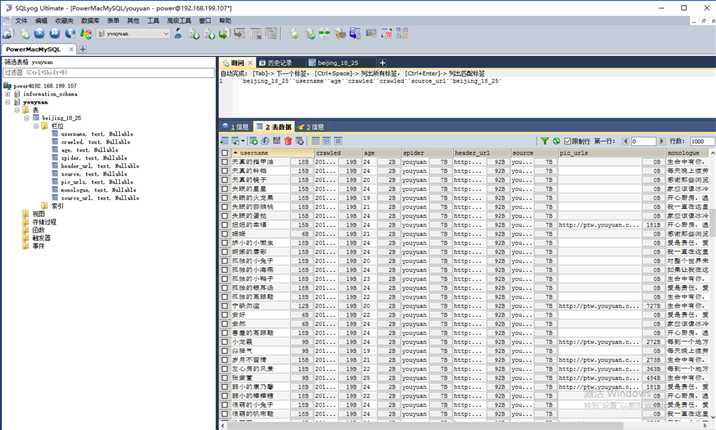
py2 process_youyuan_mysql.py#process_youyuan_mysql.py # -*- coding: utf-8 -*- import json import redis import MySQLdb def main(): # 指定redis数据库信息 rediscli = redis.StrictRedis(host=‘192.168.199.108‘, port = 6379, db = 0) # 指定mysql数据库 mysqlcli = MySQLdb.connect(host=‘127.0.0.1‘, user=‘power‘, passwd=‘xxxxxxx‘, db = ‘youyuan‘, port=3306, use_unicode=True) while True: # FIFO模式为 blpop,LIFO模式为 brpop,获取键值 source, data = rediscli.blpop(["youyuan:items"]) item = json.loads(data) try: # 使用cursor()方法获取操作游标 cur = mysqlcli.cursor() # 使用execute方法执行SQL INSERT语句 cur.execute("INSERT INTO beijing_18_25 (username, crawled, age, spider, header_url, source, pic_urls, monologue, source_url) VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s )", [item[‘username‘], item[‘crawled‘], item[‘age‘], item[‘spider‘], item[‘header_url‘], item[‘source‘], item[‘pic_urls‘], item[‘monologue‘], item[‘source_url‘]]) # 提交sql事务 mysqlcli.commit() #关闭本次操作 cur.close() print "inserted %s" % item[‘source_url‘] except MySQLdb.Error,e: print "Mysql Error %d: %s" % (e.args[0], e.args[1]) if __name__ == ‘__main__‘: main()
思考:如何将已有的Scrapy爬虫项目,改写成scrapy-redis分布式爬虫。
要求:将所有对应的大类的 标题和urls、小类的 标题和urls、子链接url、文章名以及文章内容,存入Redis数据库。
# -*- coding: utf-8 -*- import scrapy import sys reload(sys) sys.setdefaultencoding("utf-8") class SinaItem(scrapy.Item): # 大类的标题 和 url parentTitle = scrapy.Field() parentUrls = scrapy.Field() # 小类的标题 和 子url subTitle = scrapy.Field() subUrls = scrapy.Field() # 小类目录存储路径 subFilename = scrapy.Field() # 小类下的子链接 sonUrls = scrapy.Field() # 文章标题和内容 head = scrapy.Field() content = scrapy.Field()
# -*- coding: utf-8 -*- from scrapy import signals import sys reload(sys) sys.setdefaultencoding("utf-8") class SinaPipeline(object): def process_item(self, item, spider): sonUrls = item[‘sonUrls‘] # 文件名为子链接url中间部分,并将 / 替换为 _,保存为 .txt格式 filename = sonUrls[7:-6].replace(‘/‘,‘_‘) filename += ".txt" fp = open(item[‘subFilename‘]+‘/‘+filename, ‘w‘) fp.write(item[‘content‘]) fp.close() return item
# -*- coding: utf-8 -*- BOT_NAME = ‘Sina‘ SPIDER_MODULES = [‘Sina.spiders‘] NEWSPIDER_MODULE = ‘Sina.spiders‘ ITEM_PIPELINES = { ‘Sina.pipelines.SinaPipeline‘: 300, } LOG_LEVEL = ‘DEBUG‘
# -*- coding: utf-8 -*- from Sina.items import SinaItem import scrapy import os import sys reload(sys) sys.setdefaultencoding("utf-8") class SinaSpider(scrapy.Spider): name= "sina" allowed_domains= ["sina.com.cn"] start_urls= [ "http://news.sina.com.cn/guide/" ] def parse(self, response): items= [] # 所有大类的url 和 标题 parentUrls = response.xpath(‘//div[@id=\"tab01\"]/div/h3/a/@href‘).extract() parentTitle = response.xpath("//div[@id=\"tab01\"]/div/h3/a/text()").extract() # 所有小类的ur 和 标题 subUrls = response.xpath(‘//div[@id=\"tab01\"]/div/ul/li/a/@href‘).extract() subTitle = response.xpath(‘//div[@id=\"tab01\"]/div/ul/li/a/text()‘).extract() #爬取所有大类 for i in range(0, len(parentTitle)): # 指定大类目录的路径和目录名 parentFilename = "./Data/" + parentTitle[i] #如果目录不存在,则创建目录 if(not os.path.exists(parentFilename)): os.makedirs(parentFilename) # 爬取所有小类 for j in range(0, len(subUrls)): item = SinaItem() # 保存大类的title和urls item[‘parentTitle‘] = parentTitle[i] item[‘parentUrls‘] = parentUrls[i] # 检查小类的url是否以同类别大类url开头,如果是返回True (sports.sina.com.cn 和 sports.sina.com.cn/nba) if_belong = subUrls[j].startswith(item[‘parentUrls‘]) # 如果属于本大类,将存储目录放在本大类目录下 if(if_belong): subFilename =parentFilename + ‘/‘+ subTitle[j] # 如果目录不存在,则创建目录 if(not os.path.exists(subFilename)): os.makedirs(subFilename) # 存储 小类url、title和filename字段数据 item[‘subUrls‘] = subUrls[j] item[‘subTitle‘] =subTitle[j] item[‘subFilename‘] = subFilename items.append(item) #发送每个小类url的Request请求,得到Response连同包含meta数据 一同交给回调函数 second_parse 方法处理 for item in items: yield scrapy.Request( url = item[‘subUrls‘], meta={‘meta_1‘: item}, callback=self.second_parse) #对于返回的小类的url,再进行递归请求 def second_parse(self, response): # 提取每次Response的meta数据 meta_1= response.meta[‘meta_1‘] # 取出小类里所有子链接 sonUrls = response.xpath(‘//a/@href‘).extract() items= [] for i in range(0, len(sonUrls)): # 检查每个链接是否以大类url开头、以.shtml结尾,如果是返回True if_belong = sonUrls[i].endswith(‘.shtml‘) and sonUrls[i].startswith(meta_1[‘parentUrls‘]) # 如果属于本大类,获取字段值放在同一个item下便于传输 if(if_belong): item = SinaItem() item[‘parentTitle‘] =meta_1[‘parentTitle‘] item[‘parentUrls‘] =meta_1[‘parentUrls‘] item[‘subUrls‘] = meta_1[‘subUrls‘] item[‘subTitle‘] = meta_1[‘subTitle‘] item[‘subFilename‘] = meta_1[‘subFilename‘] item[‘sonUrls‘] = sonUrls[i] items.append(item) #发送每个小类下子链接url的Request请求,得到Response后连同包含meta数据 一同交给回调函数 detail_parse 方法处理 for item in items: yield scrapy.Request(url=item[‘sonUrls‘], meta={‘meta_2‘:item}, callback = self.detail_parse) # 数据解析方法,获取文章标题和内容 def detail_parse(self, response): item = response.meta[‘meta_2‘] content = "" head = response.xpath(‘//h1[@id=\"main_title\"]/text()‘) content_list = response.xpath(‘//div[@id=\"artibody\"]/p/text()‘).extract() # 将p标签里的文本内容合并到一起 for content_one in content_list: content += content_one item[‘head‘]= head item[‘content‘]= content yield item
scrapy crawl sina
注:items数据直接存储在Redis数据库中,这个功能已经由scrapy-redis自行实现。除非单独做额外处理(比如直接存入本地数据库等),否则不用编写pipelines.py代码。
# items.py # -*- coding: utf-8 -*- import scrapy import sys reload(sys) sys.setdefaultencoding("utf-8") class SinaItem(scrapy.Item): # 大类的标题 和 url parentTitle = scrapy.Field() parentUrls = scrapy.Field() # 小类的标题 和 子url subTitle = scrapy.Field() subUrls = scrapy.Field() # 小类目录存储路径 # subFilename = scrapy.Field() # 小类下的子链接 sonUrls = scrapy.Field() # 文章标题和内容 head = scrapy.Field() content = scrapy.Field()
# settings.py SPIDER_MODULES = [‘Sina.spiders‘] NEWSPIDER_MODULE = ‘Sina.spiders‘ USER_AGENT = ‘scrapy-redis (+https://github.com/rolando/scrapy-redis)‘ DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" SCHEDULER = "scrapy_redis.scheduler.Scheduler" SCHEDULER_PERSIST = True SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderPriorityQueue" #SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderQueue" #SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderStack" ITEM_PIPELINES = { # ‘Sina.pipelines.SinaPipeline‘: 300, ‘scrapy_redis.pipelines.RedisPipeline‘: 400, } LOG_LEVEL = ‘DEBUG‘ # Introduce an artifical delay to make use of parallelism. to speed up the # crawl. DOWNLOAD_DELAY = 1 REDIS_HOST = "192.168.13.26" REDIS_PORT = 6379
# sina.py # -*- coding: utf-8 -*- from Sina.items import SinaItem from scrapy_redis.spiders import RedisSpider #from scrapy.spiders import Spider import scrapy import sys reload(sys) sys.setdefaultencoding("utf-8") #class SinaSpider(Spider): class SinaSpider(RedisSpider): name= "sina" redis_key = "sinaspider:start_urls" #allowed_domains= ["sina.com.cn"] #start_urls= [ # "http://news.sina.com.cn/guide/" #]#起始urls列表 def __init__(self, *args, **kwargs): domain = kwargs.pop(‘domain‘, ‘‘) self.allowed_domains = filter(None, domain.split(‘,‘)) super(SinaSpider, self).__init__(*args, **kwargs) def parse(self, response): items= [] # 所有大类的url 和 标题 parentUrls = response.xpath(‘//div[@id=\"tab01\"]/div/h3/a/@href‘).extract() parentTitle = response.xpath("//div[@id=\"tab01\"]/div/h3/a/text()").extract() # 所有小类的ur 和 标题 subUrls = response.xpath(‘//div[@id=\"tab01\"]/div/ul/li/a/@href‘).extract() subTitle = response.xpath(‘//div[@id=\"tab01\"]/div/ul/li/a/text()‘).extract() #爬取所有大类 for i in range(0, len(parentTitle)): # 指定大类的路径和目录名 #parentFilename = "./Data/" + parentTitle[i] #如果目录不存在,则创建目录 #if(not os.path.exists(parentFilename)): # os.makedirs(parentFilename) # 爬取所有小类 for j in range(0, len(subUrls)): item = SinaItem() # 保存大类的title和urls item[‘parentTitle‘] = parentTitle[i] item[‘parentUrls‘] = parentUrls[i] # 检查小类的url是否以同类别大类url开头,如果是返回True (sports.sina.com.cn 和 sports.sina.com.cn/nba) if_belong = subUrls[j].startswith(item[‘parentUrls‘]) # 如果属于本大类,将存储目录放在本大类目录下 if(if_belong): #subFilename =parentFilename + ‘/‘+ subTitle[j] # 如果目录不存在,则创建目录 #if(not os.path.exists(subFilename)): # os.makedirs(subFilename) # 存储 小类url、title和filename字段数据 item[‘subUrls‘] = subUrls[j] item[‘subTitle‘] =subTitle[j] #item[‘subFilename‘] = subFilename items.append(item) #发送每个小类url的Request请求,得到Response连同包含meta数据 一同交给回调函数 second_parse 方法处理 for item in items: yield scrapy.Request( url = item[‘subUrls‘], meta={‘meta_1‘: item}, callback=self.second_parse) #对于返回的小类的url,再进行递归请求 def second_parse(self, response): # 提取每次Response的meta数据 meta_1= response.meta[‘meta_1‘] # 取出小类里所有子链接 sonUrls = response.xpath(‘//a/@href‘).extract() items= [] for i in range(0, len(sonUrls)): # 检查每个链接是否以大类url开头、以.shtml结尾,如果是返回True if_belong = sonUrls[i].endswith(‘.shtml‘) and sonUrls[i].startswith(meta_1[‘parentUrls‘]) # 如果属于本大类,获取字段值放在同一个item下便于传输 if(if_belong): item = SinaItem() item[‘parentTitle‘] =meta_1[‘parentTitle‘] item[‘parentUrls‘] =meta_1[‘parentUrls‘] item[‘subUrls‘] =meta_1[‘subUrls‘] item[‘subTitle‘] =meta_1[‘subTitle‘] #item[‘subFilename‘] = meta_1[‘subFilename‘] item[‘sonUrls‘] = sonUrls[i] items.append(item) #发送每个小类下子链接url的Request请求,得到Response后连同包含meta数据 一同交给回调函数 detail_parse 方法处理 for item in items: yield scrapy.Request(url=item[‘sonUrls‘], meta={‘meta_2‘:item}, callback = self.detail_parse) # 数据解析方法,获取文章标题和内容 def detail_parse(self, response): item = response.meta[‘meta_2‘] content = "" head = response.xpath(‘//h1[@id=\"main_title\"]/text()‘).extract() content_list = response.xpath(‘//div[@id=\"artibody\"]/p/text()‘).extract() # 将p标签里的文本内容合并到一起 for content_one in content_list: content += content_one item[‘head‘]= head[0] if len(head) > 0 else "NULL" item[‘content‘]= content yield item
slave端:
scrapy runspider sina.py
Master端:
redis-cli> lpush sinaspider:start_urls http://news.sina.com.cn/guide/
IT桔子是关注IT互联网行业的结构化的公司数据库和商业信息服务提供商,于2013年5月21日上线。
IT桔子致力于通过信息和数据的生产、聚合、挖掘、加工、处理,帮助目标用户和客户节约时间和金钱、提高效率,以辅助其各类商业行为,包括风险投资、收购、竞争情报、细分行业信息、国外公司产品信息数据服务等。
用于需自行对所发表或采集的内容负责,因所发表或采集的内容引发的一切纠纷、损失,由该内容的发表或采集者承担全部直接或间接(连带)法律责任,IT桔子不承担任何法律责任。
项目采集地址:http://www.itjuzi.com/company
要求:采集页面下所有创业公司的公司信息,包括以下但不限于:
# items.py # -*- coding: utf-8 -*- import scrapy class CompanyItem(scrapy.Item): # 公司id (url数字部分) info_id = scrapy.Field() # 公司名称 company_name = scrapy.Field() # 公司口号 slogan = scrapy.Field() # 分类 scope = scrapy.Field() # 子分类 sub_scope = scrapy.Field() # 所在城市 city = scrapy.Field() # 所在区域 area = scrapy.Field() # 公司主页 home_page = scrapy.Field() # 公司标签 tags = scrapy.Field() # 公司简介 company_intro = scrapy.Field() # 公司全称: company_full_name = scrapy.Field() # 成立时间: found_time = scrapy.Field() # 公司规模: company_size = scrapy.Field() # 运营状态 company_status = scrapy.Field() # 投资情况列表:包含获投时间、融资阶段、融资金额、投资公司 tz_info = scrapy.Field() # 团队信息列表:包含成员姓名、成员职称、成员介绍 tm_info = scrapy.Field() # 产品信息列表:包含产品名称、产品类型、产品介绍 pdt_info = scrapy.Field()
# items.py # -*- coding: utf-8 -*- import scrapy class CompanyItem(scrapy.Item): # 公司id (url数字部分) info_id = scrapy.Field() # 公司名称 company_name = scrapy.Field() # 公司口号 slogan = scrapy.Field() # 分类 scope = scrapy.Field() # 子分类 sub_scope = scrapy.Field() # 所在城市 city = scrapy.Field() # 所在区域 area = scrapy.Field() # 公司主页 home_page = scrapy.Field() # 公司标签 tags = scrapy.Field() # 公司简介 company_intro = scrapy.Field() # 公司全称: company_full_name = scrapy.Field() # 成立时间: found_time = scrapy.Field() # 公司规模: company_size = scrapy.Field() # 运营状态 company_status = scrapy.Field() # 投资情况列表:包含获投时间、融资阶段、融资金额、投资公司 tz_info = scrapy.Field() # 团队信息列表:包含成员姓名、成员职称、成员介绍 tm_info = scrapy.Field() # 产品信息列表:包含产品名称、产品类型、产品介绍 pdt_info = scrapy.Field()
# -*- coding: utf-8 -*-
BOT_NAME = ‘itjuzi‘
SPIDER_MODULES = [‘itjuzi.spiders‘]
NEWSPIDER_MODULE = ‘itjuzi.spiders‘
# Enables scheduling storing requests queue in redis.
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# Ensure all spiders share same duplicates filter through redis.
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
# REDIS_START_URLS_AS_SET = True
COOKIES_ENABLED = False
DOWNLOAD_DELAY = 1.5
# 支持随机下载延迟
RANDOMIZE_DOWNLOAD_DELAY = True
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
ITEM_PIPELINES = {
‘scrapy_redis.pipelines.RedisPipeline‘: 300
}
DOWNLOADER_MIDDLEWARES = {
# 该中间件将会收集失败的页面,并在爬虫完成后重新调度。(失败情况可能由于临时的问题,例如连接超时或者HTTP 500错误导致失败的页面)
‘scrapy.downloadermiddlewares.retry.RetryMiddleware‘: 80,
# 该中间件提供了对request设置HTTP代理的支持。您可以通过在 Request 对象中设置 proxy 元数据来开启代理。
‘scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware‘: 100,
‘itjuzi.middlewares.RotateUserAgentMiddleware‘: 200,
}
REDIS_HOST = "192.168.199.108"
REDIS_PORT = 6379
middlewares.py # -*- coding: utf-8 -*- from scrapy.contrib.downloadermiddleware.useragent import UserAgentMiddleware import random # User-Agetn 下载中间件 class RotateUserAgentMiddleware(UserAgentMiddleware): def __init__(self, user_agent=‘‘): self.user_agent = user_agent def process_request(self, request, spider): # 这句话用于随机选择user-agent ua = random.choice(self.user_agent_list) request.headers.setdefault(‘User-Agent‘, ua) user_agent_list = [ "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1", "Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6", "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6", "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1", "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5", "Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", "Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3", "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3", "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24", "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24", "Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US) AppleWebKit/531.21.8 (KHTML, like Gecko) Version/4.0.4 Safari/531.21.10", "Mozilla/5.0 (Windows; U; Windows NT 5.2; en-US) AppleWebKit/533.17.8 (KHTML, like Gecko) Version/5.0.1 Safari/533.17.8", "Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/533.19.4 (KHTML, like Gecko) Version/5.0.2 Safari/533.18.5", "Mozilla/5.0 (Windows; U; Windows NT 6.1; en-GB; rv:1.9.1.17) Gecko/20110123 (like Firefox/3.x) SeaMonkey/2.0.12", "Mozilla/5.0 (Windows NT 5.2; rv:10.0.1) Gecko/20100101 Firefox/10.0.1 SeaMonkey/2.7.1", "Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_5_8; en-US) AppleWebKit/532.8 (KHTML, like Gecko) Chrome/4.0.302.2 Safari/532.8", "Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_4; en-US) AppleWebKit/534.3 (KHTML, like Gecko) Chrome/6.0.464.0 Safari/534.3", "Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_5; en-US) AppleWebKit/534.13 (KHTML, like Gecko) Chrome/9.0.597.15 Safari/534.13", "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_2) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.835.186 Safari/535.1", "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_6_8) AppleWebKit/535.2 (KHTML, like Gecko) Chrome/15.0.874.54 Safari/535.2", "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_6_8) AppleWebKit/535.7 (KHTML, like Gecko) Chrome/16.0.912.36 Safari/535.7", "Mozilla/5.0 (Macintosh; U; Mac OS X Mach-O; en-US; rv:2.0a) Gecko/20040614 Firefox/3.0.0 ", "Mozilla/5.0 (Macintosh; U; PPC Mac OS X 10.5; en-US; rv:1.9.0.3) Gecko/2008092414 Firefox/3.0.3", "Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10.5; en-US; rv:1.9.1) Gecko/20090624 Firefox/3.5", "Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10.6; en-US; rv:1.9.2.14) Gecko/20110218 AlexaToolbar/alxf-2.0 Firefox/3.6.14", "Mozilla/5.0 (Macintosh; U; PPC Mac OS X 10.5; en-US; rv:1.9.2.15) Gecko/20110303 Firefox/3.6.15", "Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1" ]
# -*- coding: utf-8 -*- from bs4 import BeautifulSoup from scrapy.linkextractors import LinkExtractor from scrapy.spiders import CrawlSpider, Rule from scrapy_redis.spiders import RedisCrawlSpider from itjuzi.items import CompanyItem class ITjuziSpider(RedisCrawlSpider): name = ‘itjuzi‘ allowed_domains = [‘www.itjuzi.com‘] # start_urls = [‘http://www.itjuzi.com/company‘] redis_key = ‘itjuzispider:start_urls‘ rules = [ # 获取每一页的链接 Rule(link_extractor=LinkExtractor(allow=(‘/company\?page=\d+‘))), # 获取每一个公司的详情 Rule(link_extractor=LinkExtractor(allow=(‘/company/\d+‘)), callback=‘parse_item‘) ] def parse_item(self, response): soup = BeautifulSoup(response.body, ‘lxml‘) # 开头部分: //div[@class="infoheadrow-v2 ugc-block-item"] cpy1 = soup.find(‘div‘, class_=‘infoheadrow-v2‘) if cpy1: # 公司名称://span[@class="title"]/b/text()[1] company_name = cpy1.find(class_=‘title‘).b.contents[0].strip().replace(‘\t‘, ‘‘).replace(‘\n‘, ‘‘) # 口号: //div[@class="info-line"]/p slogan = cpy1.find(class_=‘info-line‘).p.get_text() # 分类:子分类//span[@class="scope c-gray-aset"]/a[1] scope_a = cpy1.find(class_=‘scope c-gray-aset‘).find_all(‘a‘) # 分类://span[@class="scope c-gray-aset"]/a[1] scope = scope_a[0].get_text().strip() if len(scope_a) > 0 else ‘‘ # 子分类:# //span[@class="scope c-gray-aset"]/a[2] sub_scope = scope_a[1].get_text().strip() if len(scope_a) > 1 else ‘‘ # 城市+区域://span[@class="loca c-gray-aset"]/a city_a = cpy1.find(class_=‘loca c-gray-aset‘).find_all(‘a‘) # 城市://span[@class="loca c-gray-aset"]/a[1] city = city_a[0].get_text().strip() if len(city_a) > 0 else ‘‘ # 区域://span[@class="loca c-gray-aset"]/a[2] area = city_a[1].get_text().strip() if len(city_a) > 1 else ‘‘ # 主页://a[@class="weblink marl10"]/@href home_page = cpy1.find(class_=‘weblink marl10‘)[‘href‘] # 标签://div[@class="tagset dbi c-gray-aset"]/a tags = cpy1.find(class_=‘tagset dbi c-gray-aset‘).get_text().strip().strip().replace(‘\n‘, ‘,‘) #基本信息://div[@class="block-inc-info on-edit-hide"] cpy2 = soup.find(‘div‘, class_=‘block-inc-info on-edit-hide‘) if cpy2: # 公司简介://div[@class="block-inc-info on-edit-hide"]//div[@class="des"] company_intro = cpy2.find(class_=‘des‘).get_text().strip() # 公司全称:成立时间:公司规模:运行状态://div[@class="des-more"] cpy2_content = cpy2.find(class_=‘des-more‘).contents # 公司全称://div[@class="des-more"]/div[1] company_full_name = cpy2_content[1].get_text().strip()[len(‘公司全称:‘):] if cpy2_content[1] else ‘‘ # 成立时间://div[@class="des-more"]/div[2]/span[1] found_time = cpy2_content[3].contents[1].get_text().strip()[len(‘成立时间:‘):] if cpy2_content[3] else ‘‘ # 公司规模://div[@class="des-more"]/div[2]/span[2] company_size = cpy2_content[3].contents[3].get_text().strip()[len(‘公司规模:‘):] if cpy2_content[3] else ‘‘ #运营状态://div[@class="des-more"]/div[3] company_status = cpy2_content[5].get_text().strip() if cpy2_content[5] else ‘‘ # 主体信息: main = soup.find(‘div‘, class_=‘main‘) # 投资情况://table[@class="list-round-v2 need2login"] # 投资情况,包含获投时间、融资阶段、融资金额、投资公司 tz = main.find(‘table‘, ‘list-round-v2‘) tz_list = [] if tz: all_tr = tz.find_all(‘tr‘) for tr in all_tr: tz_dict = {} all_td = tr.find_all(‘td‘) tz_dict[‘tz_time‘] = all_td[0].span.get_text().strip() tz_dict[‘tz_round‘] = all_td[1].get_text().strip() tz_dict[‘tz_finades‘] = all_td[2].get_text().strip() tz_dict[‘tz_capital‘] = all_td[3].get_text().strip().replace(‘\n‘, ‘,‘) tz_list.append(tz_dict) # 团队信息:成员姓名、成员职称、成员介绍 tm = main.find(‘ul‘, class_=‘list-prodcase limited-itemnum‘) tm_list = [] if tm: for li in tm.find_all(‘li‘): tm_dict = {} tm_dict[‘tm_m_name‘] = li.find(‘span‘, class_=‘c‘).get_text().strip() tm_dict[‘tm_m_title‘] = li.find(‘span‘, class_=‘c-gray‘).get_text().strip() tm_dict[‘tm_m_intro‘] = li.find(‘p‘, class_=‘mart10 person-des‘).get_text().strip() tm_list.append(tm_dict) # 产品信息:产品名称、产品类型、产品介绍 pdt = main.find(‘ul‘, class_=‘list-prod limited-itemnum‘) pdt_list = [] if pdt: for li in pdt.find_all(‘li‘): pdt_dict = {} pdt_dict[‘pdt_name‘] = li.find(‘h4‘).b.get_text().strip() pdt_dict[‘pdt_type‘] = li.find(‘span‘, class_=‘tag yellow‘).get_text().strip() pdt_dict[‘pdt_intro‘] = li.find(class_=‘on-edit-hide‘).p.get_text().strip() pdt_list.append(pdt_dict) item = CompanyItem() item[‘info_id‘] = response.url.split(‘/‘)[-1:][0] item[‘company_name‘] = company_name item[‘slogan‘] = slogan item[‘scope‘] = scope item[‘sub_scope‘] = sub_scope item[‘city‘] = city item[‘area‘] = area item[‘home_page‘] = home_page item[‘tags‘] = tags item[‘company_intro‘] = company_intro item[‘company_full_name‘] = company_full_name item[‘found_time‘] = found_time item[‘company_size‘] = company_size item[‘company_status‘] = company_status item[‘tz_info‘] = tz_list item[‘tm_info‘] = tm_list item[‘pdt_info‘] = pdt_list return item
# Automatically created by: scrapy startproject # # For more information about the [deploy] section see: # https://scrapyd.readthedocs.org/en/latest/deploy.html [settings] default = itjuzi.settings [deploy] #url = http://localhost:6800/ project = itjuzi
Slave端:
scrapy runspider juzi.py
Master端:
redis-cli > lpush itjuzispider:start_urls http://www.itjuzi.com/company
标签:后台 encoding ref 辅助 aci 存在 mongodb python爬虫 int
原文地址:https://www.cnblogs.com/alexzhang92/p/9410339.html