标签:停止 处理 提高 垃圾回收 range 时间复杂度 for val lap
杨辉三角
形如以下为杨辉三角
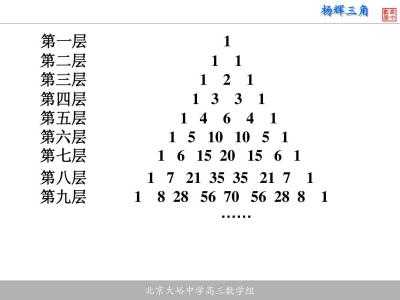
杨辉三角有很多性质,我们用以下两种简单的性质来用python实现。
1第n行的数字有n项。
2每个数等于它上方两数之和.

n=6 trangle = [[1]] for i in range(1,n): pre=trangle[i-1] cur=[1] trangle.append(cur) for j in range(i-1): cur.append(pre[j]+pre[j+1]) cur.append(1) print(trangle)
这是最简单的一种方法,关键在于控制边界方法就是不断的代入测试,只要前两遍也就是第三行和第四行可以实现,后边就应当能够实现,第一二行可以先特殊对待,在程序实现后,在回头扩宽边界。
除了以1为边界外,还可以在两侧补零
n=6 #######杨辉三角两侧补零 l=[[1]] for i in range(1,n): pre=[0]+l[i-1]+[0] cur=[] l.append(cur) for j in range(i+1): cur.append(pre[j]+pre[j+1]) print(l)
两侧补零在左侧补零会频繁调动列表移动,更好的办法是在右侧补零,最左边的索引为0的值为上一列的索引为-1和0的两项的和,也就是0+1刚好是1,需要注意的也是边界问题,如下
1 ##杨辉三角右侧补零 2 n=6 3 l=[[1]] 4 for i in range(1,n): 5 pre=l[i-1]+[0] 6 cur=[] 7 l.append(cur) 8 for j in range(i+1): 9 cur.append(pre[j-1]+pre[j]) 10 print(l)
杨辉三角是一个轴对称图形,可以在计算时只计算左侧的数值,在数据量变大时,可以提高效率。
这里使用先建立一个列表,n个1,n是要求到的行数。使用
n=6 l=[[1]] for i in range(1,n): p=l[i-1] c=[1]*(i+1) for j in range(0,i//2): value=p[j]+p[j+1] c[j+1]=value if i!=2j: c[-j-2]=value l.append(c) print(l)
使用两个列表相互循环
import copy n=6 l=[] for i in range(n): s=l.copy() for k in range(i//2): value=l[k]+l[k+1] s[k+1]=value if i != 2j: s[-k-1]=value s.append(1) l=copy.deepcopy(s) print(l)
使用一个列表实现
这里使用先建立一个列表,n个1,n是要求到的行数。使用list[:3],表示取出从0到3的元素,循环取出打印,最后列表只保留最后的一行数据
n=6 lst=[1]*n for i in range(n): e=i//2 tmp=1 offset=n-i for j in range(1,e+1): value=tmp+lst[j] tmp=lst[j] lst[j]=value if i != 2j: lst[-j-offset]=value print(lst[:i+1])
使用一个列表或的思想是生产中,对于能知道范围的数据,提前建立足够用的列表,在后期的使用中足够用,能用替换就少用append,能不遍历就不遍历。
使用一个列表减少了空间复杂度,但是时间复杂度并未减少,应当注意在列表值增大后,在每次列表更新后,原来的列表只是没有了引用计数,但并未消失,在内存中变成了内存垃圾。在技算量达到极高的量级时,每次产生的垃圾都会对内存造成冲击,如果此时,python的GC(垃圾处理)会停止其他一切内存活动,只进行垃圾处理,内存空间的整理,此时可能产生的问题是,内存没有足够的空间存放你的下一个列表,它会挪动你当前的列表,效率问题及大。
解决方案是优化算法,将庞大的列表分成一个个小的部分进行处理。
一旦数据量增大,要时刻注意效率问题。
在内存中,一旦内存使用率到达一定阈值,会触发python的自动的垃圾回收,在对垃圾回收没有足够的了解时,不要手动垃圾回收,会对系统造成性能影响。
标签:停止 处理 提高 垃圾回收 range 时间复杂度 for val lap
原文地址:https://www.cnblogs.com/rprp789/p/9449426.html
