标签:入门 因此 dnn 计算机 时间序列 chinese 网络 mod 过拟合
以下是最近在学习人工智能时整理的一点心得,没有很深的东西,觉得可以简单的了解一下机器学习与神经网络是什么
所谓机器学习,就是在大量数据的运行下,使得计算机可以进行归纳,预测
机器学习分为三类:监督学习,无监督学习,强化学习
抛开强化学习不讲,这里的监督学习与无监督学习的根本区别在于:有无数据的标记(即y值)
我们将输入的数据称之为数据的特征,一组特征为一个样本,需要求得的结果为标签
例:
1. 有一组数据,格式为(身高,体重,BMI)
这里使用监督学习的效果为: 输入若干样本的特征值(身高,体重)与对应的标签(BMI),让计算机得出一个可以得出 Y=AX+b 这样的函数(称之为模型),然后对后续的样本值,根据模型计算得出标记
2.一组数据,格式为(身高,体重) 即无y值
无监督学习: 根据身高,体重将他们聚类,如高瘦的一组,低矮的一组
监督学习分为:分类,回归
分类,就是指y为离散数据, 如通过 特征(尺寸,logo)判别 标签(手机品牌)
回归则是指y为连续数据,如上述通过 特征(身高,体重)判别 标签(bmi)
以上面的身高,体重 BMI为例
(但是由于三维图不方便绘画,且认为BMI与身高相关,由二维开始理解原理)
如图1-1所示,我们可以看出来有一条虚线可以拟合出身高与BMI的关系,但是如何根据样本数据求得该直线
下面说一下机器学习的步骤:
W指权重,b指偏差值,y1为预测的输出值,y为真实值 y1 = wx+b
我们在开始y1=0时,位于a1点,由图1-2可以得出,始终沿着斜率下降的方向,我们总会走到最低点附近,此时的w与b满足loss函数最小,则y1=wx+b为我们所求模型
具体请看公式1
根据斜率逐渐趋近于0来使得loss损失函数最小的方式称之为梯度下降(Gradient Descent)
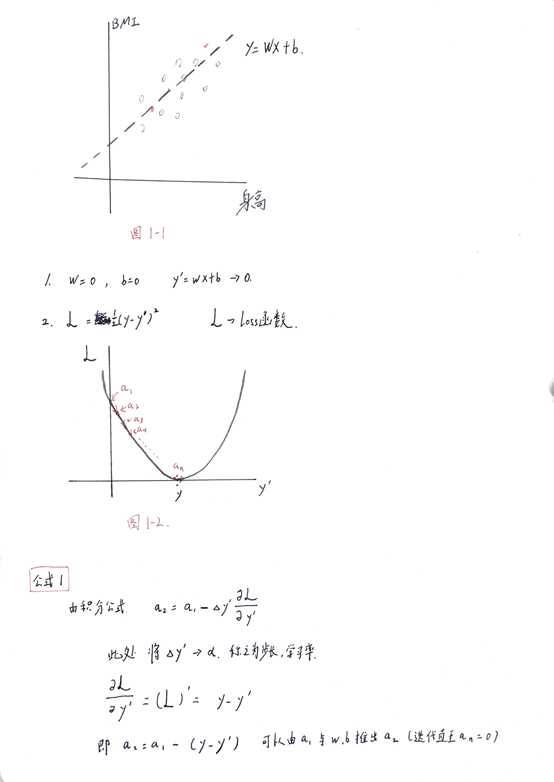
3.对于y1,y1=wx+b, 因此上面的损失函数对y1求导可以解析为L对w,b求导
又根据链式法则(图中公式),可以求出此处L对w与b的导数,然后根据求得结果重新定义w,b作为y1的模型
根据先定义的w,b求得y1,再根据y1反推w,b并重构造,称作反向传播
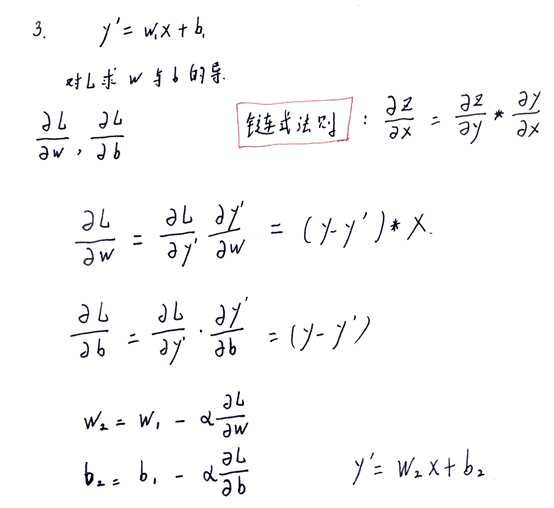
4. 接下来就很好理解了,我们将样本不断输入,使得w,b不断地重构造,最终会得出结果使得Loss函数位于最低点附近,此时的模型就符合我们的需求
对于多个特征值来说,y1=w0x0+w1x1+w2x2…+b 同理
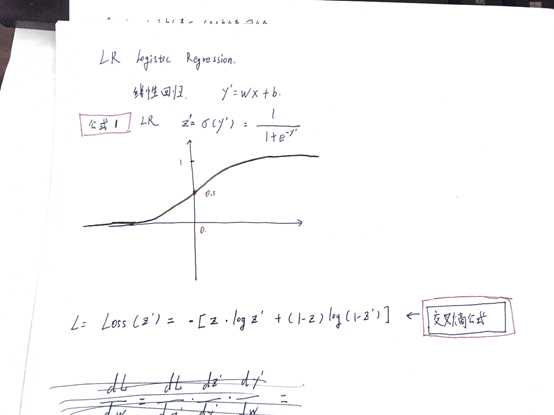
线性回归只可以拟合普通的线性函数,但是对于不满足线性条件无法做到,因此我们引入逻辑回归,构造非线性函数
逻辑回归公式,如图公式1(在线性回归基础上做了一个转换)
在逻辑回归中,损失函数与线性函数不同,使用交叉熵公式(但是原理一至)
同线性回归,对其进行梯度下降与反向传播,求出使得损失函数最小的w,b
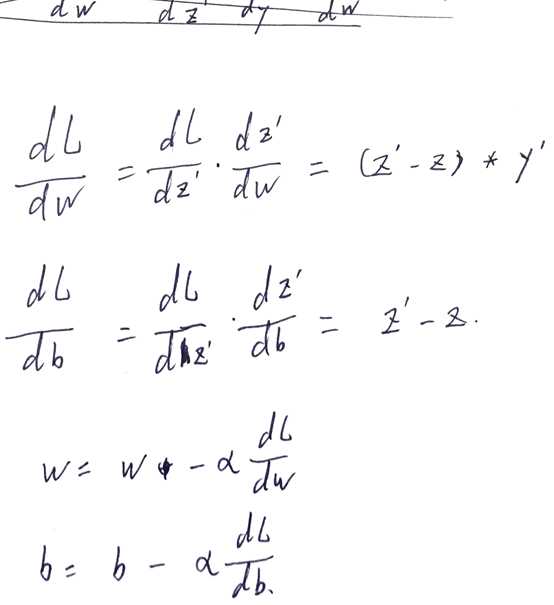
逻辑回归是非线性回归,他可以拟合出下面这种情况(这里不谈过拟合/欠拟合的概念)
之所以逻辑回归可以这样表示,这就需要了解泰勒公式
e^x = 1+x+x^2/2!+x^3/3!+…+…
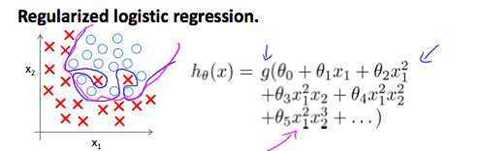
机器学习还有许多的内容,如:SVM,决策树,朴素贝叶斯…
首先需要知道几个知识:
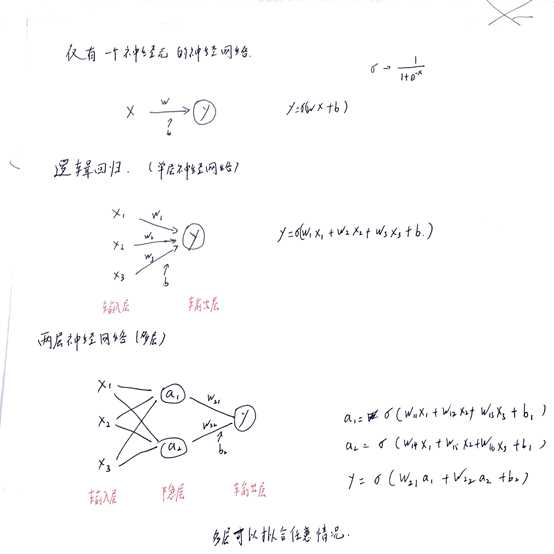
神经网络包含:输入层,隐层,输出层(对应输入样本特征,不可见的计算过程,输出的标签)
逻辑回归可以看做是最简单的神经网络
在计算神经网络层数时,往往不考虑输入层
逻辑回归LR与简单神经网络NN区别如图
神经网络的原理同逻辑回归 (梯度下降,反向传播)
理论证明:多层神经网络可以拟合任意函数
通过门,以及不断增加的神经元,可以得到所求函数的反函数的近似形状,然后再进行sigmod转型,得到目标函数
多层指 1~n层隐层 + 1层输出层
人工神经网络可以分为以下三种类型
DNN 深度神经网络
CNN 卷积神经网络
RNN 循环神经网络
其中,CNN常用来图像分析, RNN用于自然语言处理,时序预测
结合智能网管业务业务存在忙时,闲时的场景具体分析,进行RNN的lstm进行时间预测分析
两层(多层)神经网络可以近似的拟合任意函数
但是对于非一般性的函数,
如:时间序列预测,NLP自然语言处理,机器翻译
这些由前面多个值影响后者的函数 就需要使用到RNN(循环神经网络)
RNN神经网络与普通神经网络不同点在于: 每一次的输出,不仅受当前影响,也受前几个输入值影响
比如:
天气的变化: 可以由前几个时间段的值来进行评估
自然语言处理: 由前面的词出现的频率对其进行预测
语音识别: 根据前面的语音进行预测
具体如下图,在考虑y值时,不仅需要计算x4,还需要考虑到x1-3,进行加权求和
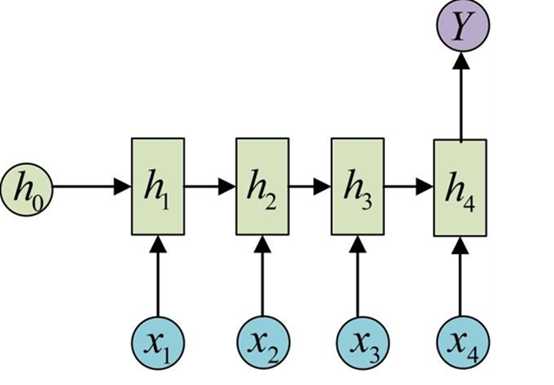
根据一定数量的输入样本,进行前馈传播计算出y值,然后根据反向传播重定义w,b 不断缩减误差,训练出模型
由多层神经网络可以拟合任意函数得出结论: 若阈值与前若干个阈值存在一定的联系,则在RNN网络下,一定可以求出模型,近似拟合该函数
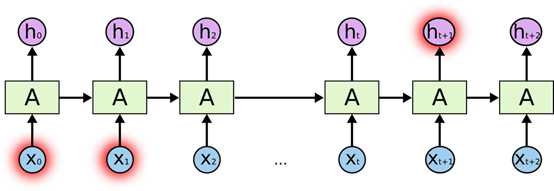
RNN不具备长期记忆能力, 如果间隔很长,会导致梯度爆炸,反向传播时会梯度消失,训练成本很大
x0,x1 很难影响到 ht+1 反向传播亦如此
现实意义就是很难由较多时间段前的数据影响到后者
(I’m from China,……..,I speak ___ ?Chinese)
因此采用RNN特殊类型的LSTM网络
LSTM网络的核心就是解决了RNN的梯度爆炸/消失问题,可以学习长期依赖信息
下图是LSTM隐层的实现过程:
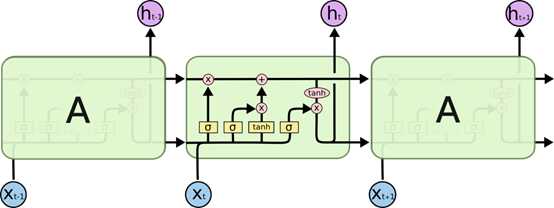
LSTM有三个门:
忘记门,输入门,输出门
忘记门
可以理解为当前值xt 对前面向量和ht-1 的影响,并对当前细胞状态Ct-1进行部分保留(如前面ht-1为I come from … ,当前xt为She,则将细胞状态Ct-1中遗忘掉I )
输入门
遗忘门负责将细胞状态中部分遗忘,添加则由输入门负责
输出门
经过计算后,得出输出的结果
所有RNN可以做的LSTM都可以做到,而且消除了梯度消失的问题.
根据前20日的阈值来估计随后一天的阈值
1.引入数据,数据集按照时间排序,以[0:20][1:21]每20天的阈值 作为输入集, [21][22]…作为标签集 数据需要标准化
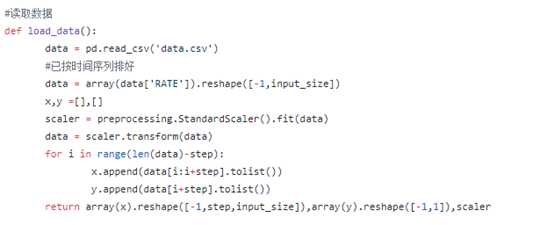
2. 搭建lstm神经网络,采用tensorflow框架,一层隐层,5个神经元

3.训练模型,训练数据为指定DN的前5/7个样本集,迭代10000次,以batch流输入,并保存模型
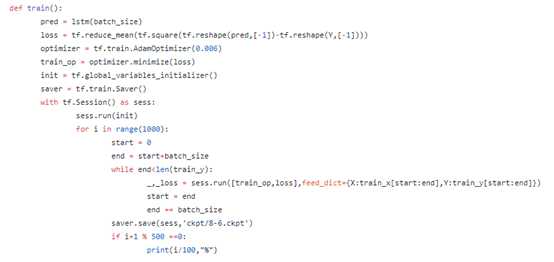
4.使用模型进行预测,
预测对象为指定DN的后2/7个样本集
第一组: 第一次输入层为20个时间段前的数据集合,接着将预测值插入输入层尾(即保持使用预测的值作为输入层)
第二组: 使用测试集进行预测

结果如图所示:
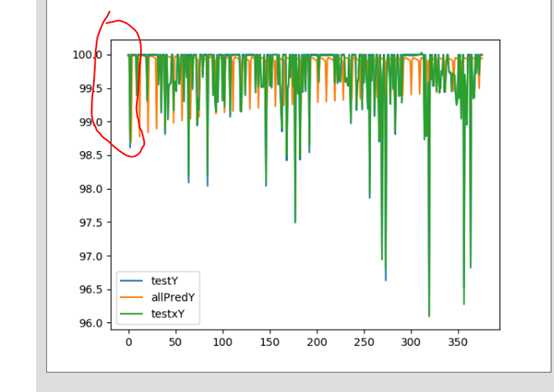
蓝色 训练集的阈值
黄色 全部基于预测的值不断迭代进行的分析
绿色 以测试集真实值X进行的预测
可以看出,在全部以预测的值为基础的前提下,开始的效果很好,但若是根据该值继续进行,越往后,偏差越大
如果以每日的准确阈值来对后几日进行预测,结果于真实值相差不多
神经网络,我个人理解 就是一个找出最佳拟合函数模型的实现方式,根据样本的持续输入,由误差函数反向传播,推倒出w,b,训练出合适的模型
神经网络的底层就是机器学习/线性回归,在其基础上不断增加层数,增加神经元,来进行更为复杂的映射函数求解
标签:入门 因此 dnn 计算机 时间序列 chinese 网络 mod 过拟合
原文地址:https://www.cnblogs.com/cyx-garen/p/9449549.html