标签:style blog http io strong 数据 sp 2014 问题
05day1 没什么可说,一道模拟水题,两道裸的模板题。05day2 是几天以来最难的一次。
?
圆排列
动态规划
【问题描述】
有 N 个人顺时针围在一圆桌上开会,他们对身高很敏感。 因此决定想使得任意相邻的两人的身高差距最大值最小。 如果答案不唯一,输出字典序最小的排列,指的是身高的排列。
【输入】
输入有多组测试数据。第一行的整数 ng 就表示有 ng 组测试数据(1<=ng<=5)。
每组测试数据格式如下:
第一行: 一个整数 N,3 <= N <= 50
第二行,有个 N 整数, 第 i 个整数表示第 i 个人的身高 hi, 1<=hi<=1000。 按顺指针给出 N个人的身高, 空格分开。
【解题过程】
一开始很自以为是地觉得是贪心。我的错误的贪心策略如下:将身高排序(以下讨论都基于排序的基础上),记为 a[1]..a[n],然后将 a[2] 排在 a[1] 左边,a[3] 排在 a[1] 右边,然后a[4] 排在 a[2] 左边,a[5] 排在 a[3] 右边……这样围成一个圈直到两边在 a[n] 处相遇。
这种方法只能过 2 个点。
然后考虑动态规划。
首先a[1] 和 a[n] 肯定不会排在一起,然后我们可以用相邻交换法证明从 a[1] 到 a[n] 的序列单调增,从 a[n] 到 a[1] 的序列单调减,即最终形态应该是这样:
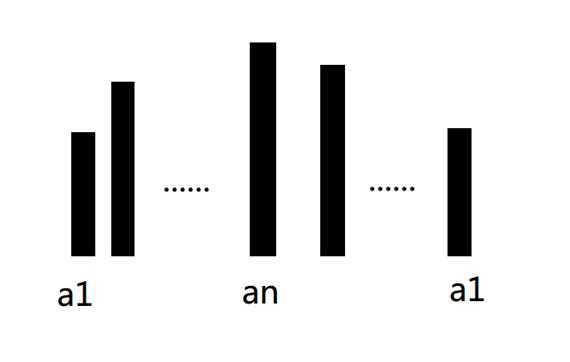
(简单说明:如果在 a[1] 到 a[n] 的序列中出现了 a[x] > a[x+1],那么交换 a[x] 与 a[x+1] 的位置之后显然得到的是更优而字典序更小的方案,所以从 a[1] 到 a[n] 必然是递增的。)
那么问题就转化为在一个有序的排列中找到两条分别从 a[1] 到 a[n] 的递增的路和从 a[n] 到 a[1] 的递减的路并且要求两条路中途不能有一样的点而路径上相邻点之间的最大身高差最小。
这样看来就是很明显的双线程 DP 了,看做是从 a[1] 出发找两条独立的递增路径,终点为 a[n]。
那么我们就用 f(i, j) 表示一条路走到了点 i,另一条路走到了点 j 时最小的最大身高差(由于 f(i, j)=f(j, i),所以我们规定 i>j),有
当 j=i-1 时,f(i, j) = min{ max{ f(i-1, k), a[i]-a[k]} },1<k<i-1
当 j<i-1 时,f(i, j) = max{ f(i-1, j), a[i]-a[i-1] }
为了处理方便,我们可以令 a[0]=a[1],a[n+1]=a[n],那么有 f(1, 0) = 0,f(2, 1) = a[2]-a[1]
最终结果为 f(n+1, n)
这道题的另一个难点是如何输出方案。为了满足字典序最小,显然我们应该在前半段中尽量取小的编号,但是这样可能会导致后半段无法满足最大差值的约束。那么我们可以反过来考虑后半段,在满足最大差值约束的条件下,尽量往后取大的编号,这样就能保证前半段取到最小的且使得整个解合法的编号。
初次提交 8 分(2/25)。
?
彩色
线段树/离散化
【问题描述】
在直角坐标系上,有 N 个边平行于坐标轴的矩形。你的任务是把其中的 K 个矩形染色,使按次序放下后,可以看见的有色面积最大。可看见的意思就是这一部分没有被后面的矩形覆盖。
你的答案是返回 K 个整数,表示你染色的是哪 K 个矩形。如果有多种答案,输出字典序最小的。
【输入】
第一行两个整数:N,K。
后面有 N 行,每行 4 个整数: x1,y1,x2,y2,分别表示先后各个矩形的左下角坐标和右上角坐标。
【输出】
输出一行,即 K 个整数,表示你染色的矩形序号。
【数据规模】
1<=N<=50; 1<=K<=N。
每个坐标值为[-10000,10000]之间的整数。
【解题过程】
这道题一开始有个细节理解错了:这些矩形是按顺序放下的,也就是说一个矩形只可能被它后面的矩形覆盖而不会被它之前的矩形覆盖。
思路还是比较明确的,计算出每个矩形被覆盖后剩余的面积,取前 k 个大即可。
关键在于求覆盖后的剩余面积。我自己用的是扫描线+线段树,对于每个矩形,把其他矩形与其相交的部分计算出来,然后和普通的扫描线一样做即可。更好的方法是上浮法和离散化,详见国家集训队论文《剖析线段树与矩形切割》。
初次提交 40 分。如上所述理解有误,而且计算相交部分的代码写错了。
?
联络
缩点/连通分量
【问题描述】
神牛 LXX 昨天刚刚满 18 岁,他现在是个成熟的有为男青年。他有 N 个 MM,分别从 1 到 N 标号。
这些 MM 有些是互相认识的。现在,LXX 为了处理和 MM 们复杂的关系,想把他们划分成尽量多的集合,要求任意两个属于不同集合的 MM 都必须互相认识。这样方便交流。现在 LXX 想知道最多可以分成多少个集合,每个集合的人数是多少。
【输入】
输入第一行是两个数 N 和 M。
接下来 M 行,每行两个数,表示这两个 MM 是互相认识的。
【输出】
第一行一个数 S,表示最多有多少个集合。
第二行 S 个数,从小到大,表示每个集合的人数。
【数据规模】
对于 40%的数据,1≤N≤1000,1≤M≤500000;
对于 100%的数据,1≤N≤100000,1≤M≤2000000。
【标程算法】
(好吧其实根本没做这题,看了题解才去做的。)
为了让集合最多,我们尽量把不认识的人分在一组,认识的人分在不同组。如果我们将认识的人用边相连,然后对这个图取反得到它的补图,那么我们只要统计出补图中连通分量的个数即是答案。
但是如果直接用遍历的方式去找连通分量,无论从空间还是时间上都是不可能的。
那么这里我们可以用一种折中的办法:「缩点」。这并不是真正意义上的缩点,而只是将某个点及与其直接相连的点看作同一个点。为了使效果达到最好,我们当然应该选择补图中度最大、即原图中度最小的点。
我们可以分析一下这种做法的可行性:
对于这种方法,最坏情况就是原图中每个点的度相等。
对于极限数据,当 N=10^6,M=2*10^7 时,每个点的度为 2*M/N=40,那么在补图中每个点的度为 10^6-4000=99960,「缩点」之后图中就仅剩 40 个不同的点。
对于特殊数据,当 N=2000,M=2*10^7 时,补图中每个点的度都为 0,无法缩点。此时补图中共 2000 个点,时间和空间上都能承受。
完全可行。
具体做法如下:
标签:style blog http io strong 数据 sp 2014 问题
原文地址:http://www.cnblogs.com/lsdsjy/p/4007063.html