标签:中文 python 1.3 信息 如何 包含 注意 相减 inf
标量就是一个数,它不同于线性代数中的其他大部分研究对象(通常是多个数的数组)。标量一般用斜体的小写字母表示,当介绍标量时,我们会明确它是哪种类型的数,如 s ∈\(\mathbb{R}\)表示一条线的斜率。
向量是由一列数组成的一维数组,向量中的数是有序排列的,向量中的每个值被称为一个元素,可以通过索引来确定向量中的每个元素(就像使用数组下标访问数组中的元素一样)。若向量中有n个元素,则该向量被称为n维向量。向量一般使用粗体的小写字母表示,如 x。当指明一个向量时,我们也会指出其中的元素类型,如果要明确表示向量中的元素时,我们会将其元素排列为一个纵列,并用方括号包围,如下:
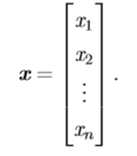
-来表示集合的补集,如x-1表示向量 x 中除x1外的剩余元素构成的向量,x-s表示向量 x 中除x1、x3、x6外的剩余元素构成的向量。
矩阵为二维数组,其中每一个元素被两个索引(行索引和列索引)所指定。矩阵通常由粗体的大写名称表示,如 A。假如矩阵A有m行n列,则可以表示为 A∈\(\mathbb{R}\)mxn。矩阵中的元素通常以 不加粗的斜体表示,如Ai,j表示矩阵 A 的第i行第j列的元素,i和j从1开始。也可以使用切片的方式来访问A中的元素,如\(A_{i,:}\)表示A的第i行的所有元素,\(A_{,:j}\)表示A的第j列的所有元素。
张量为超过两维的数组,比如有三维的张量除了行和列外还有另一维。由Google开发的机器学习框架TensorFlow中的Tensor就是张量的意思。
矩阵的左上角到右下角的连线叫做主对角线,将矩阵主对角线两侧的元素互换称为矩阵的转置(其实就是行列互换)。矩阵A的转置记为\(A^T\),有\((A^T)_{i,j}\) = \(A_{j,i}\) 。
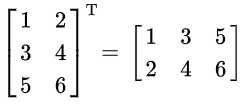
如果两个矩阵形状相同(行列数相同),则两个矩阵可以相加。矩阵相加即将两个矩阵对应位置上的元素分别相加,得到一个新的矩阵。如C=A+B,有\(C_{i,j}\)=\(A_{i,j}\)+\(B_{i,j}\) 。
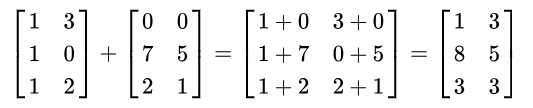
当标量与矩阵相加或相乘时,相当于矩阵中的每个元素与该标量相加或相乘。
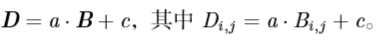
我们允许矩阵和向量相加。当一个矩阵和向量相加时,相当于该向量与矩阵的每一行相加,并产生一个新的矩阵。
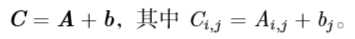
两个矩阵A和B的矩阵乘积 (matrix product)是第三个矩阵C,记为 C=AB。并不是任意两个矩阵都能相乘,在前面的例子中,只有当第一个矩阵A的列数等于第二个矩阵B的行数时才能相乘,相乘后的矩阵C的行数等于A的行数,列数等于B的列数,也就是
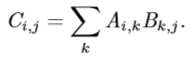
dot(A, B),来对两个矩阵A,B进行乘法。
import numpy as np
A = np.array([[1,2], [3, 4]])
B = np.array([[5,6], [7, 8]])
C = np.dot(A, B)
print A
print '-'*10
print B
print '-'*10
print C输出:
[[1 2]
[3 4]]
----------
[[5 6]
[7 8]]
----------
[[19 22]
[43 50]]矩阵乘积满足分配率:\(A(B + C) = AB + AC\),也满足结合律:\((AB)C = A(BC)\),但不总满足交换律:\(AB ≠ BA\)。两个矩阵乘积的转置满足如下性质:\((AB)^T = B^TA^T\) 。
如果是矩阵对应元素相乘,则这种乘积被称为元素对应乘积或者Hadamard 乘积,记为A\(\bigodot\)B 。
对应元素乘积在numpy中可以使用multiply(A, B),或者*。
A = np.array([[1,2], [3, 4]])
B = np.array([[5,6], [7, 8]])
print A
print '-'*10
print B
print '-'*10
print np.multiply(A, B)
print '-'*10
print A*B输出:
[[1 2]
[3 4]]
----------
[[5 6]
[7 8]]
----------
[[ 5 12]
[21 32]]
----------
[[ 5 12]
[21 32]]两个向量的点积(又称內积)即两个向量对应位置元素的乘积之和,点积得到的为一个标量,可以使用numpy中的dot(x,y)或者vdot(x,y)来计算两个向量的点积。
x = np.array([1, 2, 3])
y = np.array([4, 5, 6])
print np.dot(x, y)
print np.vdot(x, y)输出:
32
32两个相同维数的向量 x 和 y 的点积(dot product)可看作是矩阵乘积 \(x^?y\)。我 们可以把矩阵乘积 C = AB 中计算 \(C_{i,j}\) 的步骤看作是 A 的第 i 行和 B 的第 j 列之间的点积。
由于向量点积就是对应元素乘积之和,所以点积满足交换律,也就是\(x^Ty=y^Tx\) 。
以下方程组:
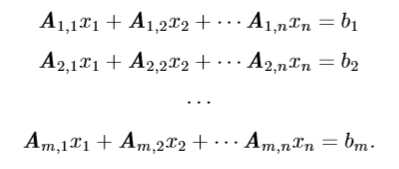
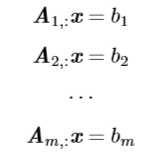
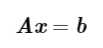
单位矩阵类似于常数四则运算中的数1,任何矩阵和单位矩阵相乘都等于该矩阵。我们将n维向量不变的单位矩阵记为\(I_n\),则对 \(?x∈\mathbb{R}^n,有I_nx=xI_n=x\)。
在形式上,\(I_n\)为一个n行n列的方针(行列数相同的矩阵),也就是\(I∈\mathbb{R}^{n×n}\),其主对角线上元素全为1,其余位置元素全为0。\(I_3\)表示为如下形式:

逆矩阵则类似于倒数,求矩阵的逆矩阵相当于求一个数的倒数。矩阵\(A\)的逆矩阵记为\(A^{-1}\),有\(AA^{-1}=A^{-1}A=I_n\)。我们可以使用逆矩阵来求解上一节中的线性方程组\(Ax=b\),步骤如下:
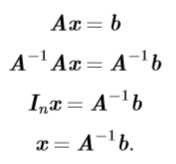
继续考虑求线性方程组\(Ax=b\)解的问题,为了分析该方程有多少个解,我们可以把A的列向量看作从原点(origin)(元素都是零的向量)出发的不同方向,确定有多少种方法可以到达向量 b。在这个观点 下,向量x中的每个元素表示我们应该沿着这些方向走多远,即\(x_i\)表示我们需要沿着第i个向量的方向走多远(考虑只有一个未知量x的线型方程组,这样A、x、b都变成了一维向量,更容易理解“方向”,“沿着方向走多远”等词汇):
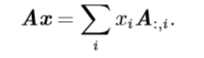
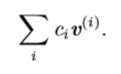
一组向量的生成子空间(span)是原始向量线性组合后所能抵达的点的集合。 继续考虑求线性方程组\(Ax=b\)解的问题,确定\(Ax = b\)是否有解相当于确定向量b是否在A列向量的生成子空间中。这个特殊的生成子空间被称为A的列空间(column space)或者A的值域range)。
为了使方程\(Ax = b\)对于任意向量\(b∈\mathbb{R}^{m}\)都存在解,我们要求A的列空间构成整个\(\mathbb{R}^{m}\)。如果\(\mathbb{R}^{m}\)中的某个点不在A的列空间中,那么该点对应的b会使得该方程没有解。矩阵A 的列空间是整个\(\mathbb{R}^{m}\)的要求,意味着A至少有 m 列,即 n ≥ m。否则,A 列空间的维数会小于 m。例如,假设 A 是一个 3×2 的矩阵。目标 b 是 3 维的,但是 x 只有 2 维。所以无论如何修改 x 的值,也只能描绘出 \(\mathbb{R}^{3}\) 空间中的二维平面。当且仅当向量 b 在该二维平面中时,该方程有解。
不等式 n ≥ m 仅是方程对每一点都有解的必要条件。这不是一个充分条件,因为有些列向量可能是冗余的。假设有一个\(\mathbb{R}^{2×2}\)中的矩阵,它的两个列向量是相同的。那么它的列空间和它的一个列向量作为矩阵的列空间是一样的。换言之,虽然该矩阵有2列,但是它的列空间仍然只是一条线,不能涵盖整个\(\mathbb{R}^{2}\)空间。
正式地说,这种冗余被称为线性相关。
对于一个向量组\(a_1, a_2,...,a_n\)来说,如果存在不全为0的数\(k_1,k_2,...,k_n\),使得\[k_1a_1+k_2a_2+...+k_na_n=0\],那我们说这个向量组是线性相关的。一组向量线性相关,也就是说在该向量组中至少存在一个向量能用其他向量线性表示。否则则称该向量组线型无关。
如果某个向量是一组向量中某些向量的线性组合,那么我们将这个向量加入这组向量后不会增加这组向量的生成子空间。这意味着,如果一 个矩阵的列空间涵盖整个\(\mathbb{R}^{m}\),那么该矩阵必须包含至少一组m个线性无关的向量, 这是式\(Ax=b\)对于每一个向量 b 的取值都有解的充分必要条件。值得注意的是,这个条件是说该向量集恰好有m个线性无关的列向量,而不是至少m个。不存在一个m维向量的集合具有多于 m 个彼此线性不相关的列向量,但是一个有多于 m 个 列向量的矩阵有可能拥有不止一个大小为 m 的线性无关向量集。
要想使矩阵可逆,我们还需要保证式\(Ax=b\)对于每一个 b值至多有一个解。为 此,我们需要确保该矩阵至多有 m 个列向量。否则,该方程会有不止一个解。
综上所述,这意味着该矩阵必须是一个方阵(square),即 m = n,并且所有列 向量都是线性无关的。一个列向量线性相关的方阵被称为奇异的(singular)。
矩阵A的秩为A中线性无关的列向量的最大个数,记为R(A)。通过秩可以确定n元线性方程组\(Ax=b\)解的情况:
(i)无解的充分必要条件是R(A)<R(A,b);
(ii)有唯一解的充分必要条件是R(A)=R(A,b)=0;
(iii)有无限多解的的充分必要条件是R(A)=R(A,b)<n;
通过numpy可以方便的求解矩阵的秩,从而判断解的情况:
A = np.array([[1,-2,3,-1],
[3,-1,5,-3],
[2,1,2,-2]])
b = np.array([1,2,3]).reshape(3,1)
#将A,b水平拼接
print np.hstack((A, b))
A_rank = np.linalg.matrix_rank(A)
print A_rank
Ab_rank = np.linalg.matrix_rank(np.hstack((A, b)))
print Ab_rank
print A_rank<Ab_rank输出:
[[ 1 -2 3 -1 1]
[ 3 -1 5 -3 2]
[ 2 1 2 -2 3]]
2
3
True根据(i),该方程组无解。
范数用来衡量向量的大小。形式上,\(L^p\)范数定义如下:
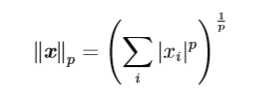

当p=2时,\(L^2\)范数被称为欧几里得范数,因为此时\(L^2=\sqrt(x_1^2+x_2^2+...+x_n^2)\),为空间上点x到原点的距离。平方\(L^2\)范数在数学和计算上都比\(L^2\)范数更方便,例如,平方\(L^2\)范数对x中每个元素的导数只取决于对应的元素,而\(L^2\)范数对每个元素的导数却和整个向量相关。但是在很多情况下,平方\(L^2\)范数也可能不受欢迎,因为它在原点附近增长得十分缓慢。
当机器学习问题中零和非零元素之间的差异非常重要时,通常会使用\(L^1\)范数。每当 x 中某个元素从 0 增加 ?,对应的\(L^1\)范数也会增加 ?。 有时候我们会统计向量中非零元素的个数来衡量向量的大小。有些作者将这种 函数称为 “\(L^0\)范数’’,但是这个术语在数学意义上是不对的。向量的非零元素的数目 不是范数,因为对向量缩放 α 倍不会改变该向量非零元素的数目。因此,\(L^1\)范数经常作为表示非零元素数目的替代函数。
\(L^∞\)范数也被成为最大范数,这个范数用来表示向量中具有最大幅值元素的绝对值:
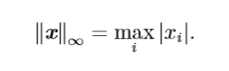
上面的范数都是用来衡量向量的大小,而Frobenius范数用来衡量矩阵的大小。矩阵A的Frobenius范数定义为
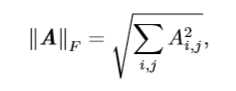
两个向量的点积(內积)的通常求法是将两个向量对应位置元素的乘积求和,除此之外也可以使用范数来求:
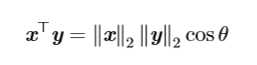
对角矩阵只在主对角线上含有非零元素,其余位置元素全为零。当主对角线上的元素全为1时,该对角矩阵为单位矩阵。形式上,对矩阵D时对角矩阵,当且仅当对任意的\(i≠j\),\(D_{i,j}=0\)。我们用diag(v)来表示对角元素由向量v中的元素指定的对角矩阵。
对角矩阵之所以受到关注是因为它的乘法计算很高效。计算\(diag(v)x\),我们只需要将向量x中的每个元素\(x_i\)放大\(v_i\)倍,也就是\(diag(v)x=v\bigodot x\),\(\bigodot\)为上面提到的对应元素乘积。
计算对角矩阵的逆矩阵也很高效。对角矩阵的逆矩阵存在,当且仅当对角元素都是非零值。在这种情况下,有:
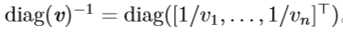
对称矩阵是转置和自己相等的矩阵,也就是:\[A = A^T\]
单位向量是具有单位范数的向量(单位向量到原点的距离为1),向量x是单位向量,则有:
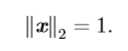
正交矩阵(orthogonal matrix)是指行向量和列向量是分别标准正交的方阵:
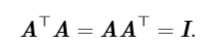
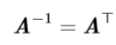
许多数学对象可以通过一定的方法将它们分解为多个部分或找到一些属性从而更好地理解这些数学对象。这些属性是通用的,而不是由我们选择表示它们的方式产生的。例如,整数可以分解为质因数。我们可以用十进制或二进制等不同方式表示整数12,但是12 = 2×2×3 永远是对的。从这个表示中我们可以获得一些有用的信 息,比如 12 不能被 5 整除,或者 12 的倍数可以被 3 整除。
同样地,矩阵也可以通过一些方法来分解。特征分解是使用最广的矩阵分解之一,通过特征分解可以将矩阵分解成一组特征向量和特征值。
设A是一个方阵,如果存在数λ和非零列向量 v,使得:\[Av=λv\]成立,则非零列向量v成为方阵A的特征值,标量λ称为特征向量v对应的特征值。从另一个角度理解,方阵A的特征向量是指与A相乘后相当于对该向量进行缩放的列向量。(类似的,左特征向量定义为\(v^TA=λv^T\),但我们更关注右特征向量)。
如果v是A的特征向量,则v缩放过后的向量λv(λ≠0,λ∈\(\mathbb{R}\))也是A的特征向量,且v和λv的特征值相同。通常我们只考虑单位特征向量v。
假设矩阵A有n个线型无关的特征向量\({v_1,v_2,...,v_n}\),对应n个特征值\({λ_1,λ_2,...,λ_n}\)。我们将特征向量组成一个矩阵V,使得每一列为一个特征向量,则\(V=[v_1,v_2,...,v_n]\),类似地,将特征值连接成一个列向量λ=\([λ_1,λ_2,...,λ_n]^T\),则矩阵A的特征分解可以记为:
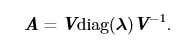
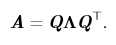
所有特征值都是正数的矩阵被称为正定(positive de?nite);所有特征值都是非负数的矩阵被称为半正定(positive semide?nite)。同样地,所有特征值都是负数的矩阵被称为负定(negative de?nite);所有特征值都是非正数的矩阵被称为半负定 (negative semide?nite)。
除了特征分解外,另一种分解矩阵的方法为奇异值分解(SVD)。通过奇异值分解,可以把矩阵分为奇异向量和奇异值。每 个实数矩阵都有一个奇异值分解,但不一定都有特征分解。例如,非方阵的矩阵没有特征分解,这时我们只能使用奇异值分解。
我们可以将矩阵A分为3个矩阵的乘积:
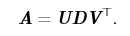
矩阵 A 的伪逆定义为:
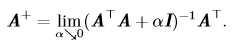
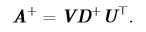
迹运算返回的是矩阵对角元素的和:
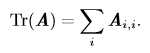
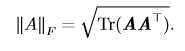
12.1、《深度学习》中文版;
12.2、同济大学《线性代数》第六版。
标签:中文 python 1.3 信息 如何 包含 注意 相减 inf
原文地址:https://www.cnblogs.com/sench/p/9461262.html