标签:信息 line ssis weather 空格 series \n div color
目录
一.预处理
二.缺失值的处理
三.格式的转换
四.异常值的处理
像下面这样,我们就完成了两个列的重命名,而其余的列名保持不变
data = data.rename(columns = {‘holiday‘:‘holid‘,‘weather‘:‘weath‘})
有的时候数据的index是0,1,2……这样的数字,我们需要修改为日期格式,date必须是数据里一个series,如下代码可以添加
data=data.set_index(‘date‘)
data.columns=map(lambda x: x.replace(‘-‘,‘‘),data.columns)
data.descirbe()
查看缺失值:
data.info()
汇总缺失值:
data.isnull().sum()
缺失值处理方法:
1.直接删除----适合缺失值数量较小,并且是随机出现的,删除它们对整体数据影响不大的情况
2.使用均值、中位数或中位数代替----优点:不会减少样本信息,处理简单。缺点:当缺失数据不是随机数据时会产生偏差.对于正常分布的数据可以使用均值代替,如果数据是倾斜的,使用中位数可能更好。
3.插补法

#过滤缺失值 data[data.notnull()] #删除缺失行 data.dropna(how=‘all‘) #删除缺失列 data.dropna(how=‘all‘,axis=1)
缺失值的简单填充:
#用 0填充
data.fillna(0)
#也可以传入均值、众数、中位数
data.fillna(data.mean())
#顺序填充,次此方法填充的缺失值 是非缺失值的最后一个的重复
data.fillna(method=‘ffill‘)
以上只是简单的处理,实际运用中应该是根据数据的需要选择合适的方法。
#create data data= pd.DataFrame({‘k1‘: [‘one‘] * 3 + [‘two‘]+[‘three‘]*3, ‘k2‘: [1, 1, 2, 3, 3, 4, 4]}) data k1 k2 0 one 1 1 one 1 2 one 2 3 two 3 4 three 3 5 three 4 6 three 4 #DataFrame的duplicated方法返回一个布尔型Series,表示各行是否是重复行 data.duplicated() 0 False 1 True 2 False 3 False 4 False 5 False 6 True dtype: bool #drop_duplicates方法用于返回一个移除了重复行的DataFrame data.drop_duplicates() k1 k2 0 one 1 2 one 2 3 two 3 4 three 3 5 three 4 ?#按某一列过滤重复值 data.drop_duplicates([‘k1‘])
时间格式的转化比较复杂,比较简单的一个就是利用pd.to_datetime
#转化index格式 data.index=pd.to_datetime(data.index)
with open(‘abc.txt‘) as f:
ix=0
while 1:
line = file.readline().strip()
if not line:
break
i+=1
line1 = line.replace(‘\r‘,‘‘)
f1 = open(‘newfile.txt‘,‘a‘)
f1.write(line1 + ‘\n‘)
f1.close()
f.close()
异常值是指样本中的个别值,也称为离群点,其数值明显偏离其余的观测值。
1)3σ原则
3σ探测方法的思想其实就是来源于切比雪夫不等式。一般是把超过三个离散值的数据称之为异常值。
一般所有数据中,至少有3/4(或75%)的数据位于平均数2个标准差范围内。
所有数据中,至少有8/9(或88.9%)的数据位于平均数3个标准差范围内。
所有数据中,至少有24/25(或96%)的数据位于平均数5个标准差范围内。
2)箱型图
把数据按照从小到大排序,其中25%为上四分位用FL表示,75%处为下四分位用FU表示。
计算展布为: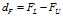
上截断点为: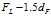
下截断点为: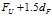
小于下截断点或大于上截断点的值,则被称为异常值
3)散点图

简单直观。
还有许多其他的方法,基于密度,基于距离,基于模型等等。
标签:信息 line ssis weather 空格 series \n div color
原文地址:https://www.cnblogs.com/jin-liang/p/9465705.html