标签:群集 访问权限 服务 方法 enable role origin tor increase
#安装之前需安装java环境,并配置JAVA_HOME环境变量
#直接下载Elasticsearch-5.5.2稳定版的.tar.gz包
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-5.5.2.tar.gz
#下载完成后,发布SHA签名
sha1sum elasticsearch-5.5.2.tar.gz
#解压Elasticsearch程序包
tar -xzf elasticsearch-5.5.2.tar.gz
#进入elasticsearch-5.5.2,该目录为$ES_HOME
cd elasticsearch-5.5.2/
#启动elasticsearch服务之前,需先配置es用户组和es用户(由于es安全因素)
1 groupadd es #增加es组
2 useradd es –g es –p pwd #增加es用户并附加到es组
3 chown -R es:es elasticsearch-5.5.2 #分配es的目录访问权限
4 chown –R es:es java/ #java也需要分配给es用户访问权限
5 su –es #切换es用户
#启动elasticsearch服务前,内存分配以本机内存大小适当分配
#或者直接起动时,配置内存大小,确保Xmx和Xms的大小是相同的,其目的是为了能够在java垃圾回收机制清理完堆区后不需要重新分隔计算堆区的大小而浪费资源,可以减轻伸缩堆大小带来的压力。
1 vi config/jvm.options 2 -Xms512m 3 -Xms512m
#启动elasticsearch服务
./bin/elasticsearch #启动ES
nohup ./bin/elasticsearch # 后台启动ES
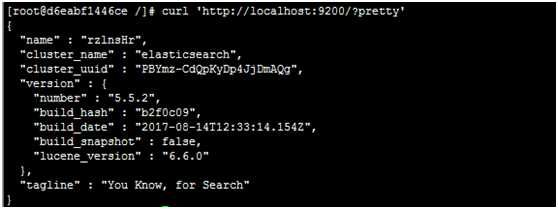
#测试elasticsearch是否启动成功
curl ‘http://localhost:9200/?pretty‘
#如需远程主机需访问该elasticsearch服务,需配置对外出口ip
#目前内网测试环境,暂时配置全部ip都可访问,生产环境当设置API调用服务器ip
vi elasticsearch.yml
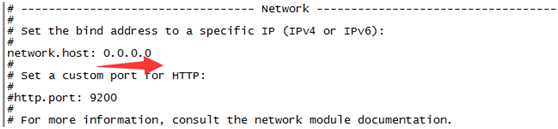
# 启动配置服务可能会出现的几个错误
1. max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536]
#切换到root用户修改 vim /etc/security/limits.conf #在最后面追加 es hard nofile 65536 es soft nofile 65536
#修改后重新登录es账号,使用命令查看上面设置是否成功,结果为65536则成功
ulimit -Hn
2.max number of threads [1024] for user [elasticsearch] is too low, increase to at least [2048]
vi /etc/security/limits.d/90-nproc.conf

3. max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
#切换到root用户 vim /etc/sysct1.conf #在最后追加 vm.max_map_count=262144 #使用 sysctl -p 查看修改结果 sysctl -p
4. system call filters failed to install; check the logs and fix your configuration or disable system call filters at your own risk
vim ./conf/elasticsearch.yml
#在文档最后追加此配置
bootstrap.system_call_filter: false
#关闭elasticsearch服务
1 jps | grep Elasticsearch 2 kill -9 pid
#重新启动
1 ./bin/elasticsearch #启动服务 2 nohup ./bin/elasticsearch & #后台启动服务
#在Es的根目录(每个节点),运行 bin/elasticsearch-plugin进行安装。
bin/elasticsearch-plugin install x-pack
#如果你在Elasticsearch已禁用自动索引的创建,在elasticsearch.yml配置action.auto_create_index允许X-pack创造以下指标:
action.auto_create_index: .security,.monitoring*,.watches,.triggered_watches,.watcher-history*
运行Elasticsearch。
bin/elasticsearch
nohup ./bin/elasticsearch & #后台启动服务
#配置 Elasticsearch数据目录以及日志目录
1 mkdir /var/lib/elasticsearch 2 mkdir /var/log/elasticsearch 3 4 vi elasticsearch.yml 5 path.data: /var/lib/elasticsearch 6 path.logs: /var/log/elasticsearch
#配置数据目录以及日志目录用户权限
1 chown –R es:es /var/lib/elasticsearch 2 chown –R es:es /var/log/elasticsearch
#重新启动elasticsearch服务
bin/elasticsearch
nohup ./bin/elasticsearch & #后台启动服务
#安装kibana
1 wget https://artifacts.elastic.co/downloads/kibana/kibana-5.5.2-linux-x86_64.tar.gz 2 sha1sum kibana-5.5.2-linux-x86_64.tar.gz 3 tar -xzf kibana-5.5.2-linux-x86_64.tar.gz 4 cd kibana/
#配置Kibana,配置server.host地址,需远程连接,因此配置服务器IP即可。
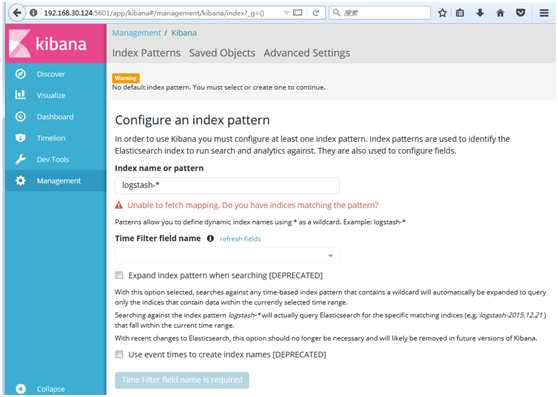
vi config/kibana.yml
#启动kibana,如下图所示,则kibana启动成功,一般使用默认配置进行启动。
./bin/kibana
nohup ./bin/kibana &

#在你的浏览器打开kibana: http://localhost:5601/app/kibana
#自动安装X-Pack
bin/kibana-plugin install x-pack
#手动安装X-Pack,下载文件过大,手动下载安装方式有限,如下图所示,安装成功。
1 wget https://artifacts.elastic.co/downloads/packs/x-pack/x-pack-5.5.2.zip 2 bin/kibana-plugin install file:///path/to/file/x-pack-5.5.2.zip

#重新启动kibana
bin/kibana
#1. elasticsearch查询所有用户, elastic为root用户,默认密码为changeme
curl -XGET -u elastic ‘localhost:9200/_xpack/security/user?pretty‘
#2. elasticsearch查询所有角色
curl -XGET -u elastic ‘localhost:9200/_xpack/security/role‘
#3.修改用户密码
1 curl -XPUT -u elastic ‘localhost:9200/_xpack/security/user/elastic/_password‘ -d ‘{ 2 "password" : "elastic" 3 }‘
#4.修改kibana密码:修改之前需要在kibana.yml中配置elasticsearch的用户名和密码后才能需改密码,否则会报错。
(1):配置好elsticsearch用户名密码后,执行脚本,修改kibana用户密码
1 curl -XPUT -u elastic ‘localhost:9200/_xpack/security/user/kibana/_password‘ -d ‘{ 2 "password" : "kibana" 3 }‘
# Kibana 5最新版本的界面
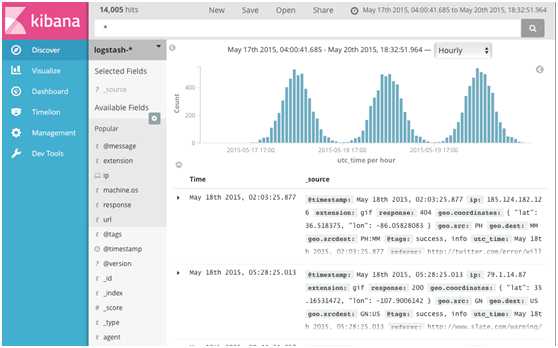
# 1.Discover#从发现页可以交互地探索ES的数据。可以访问与所选索引模式相匹配的每一个索引中的每一个文档。您可以提交搜索查询、筛选搜索结果和查看文档数据。还可以看到匹配搜索查询和获取字段值统计的文档的数量。如果一个时间字段被配置为所选择的索引模式,则文档的分布随着时间的推移显示在页面顶部的直方图中。
# 2.Visualize#可视化能使你创造你的Elasticsearch指标数据的可视化。然后你可以建立仪表板显示相关的可视化。Kibana的可视化是基于Elasticsearch查询。通过一系列的Elasticsearch聚合提取和处理您的数据,您可以创建图表显示你需要知道的关于趋势,峰值和骤降。您可以从搜索保存的搜索中创建可视化或从一个新的搜索查询开始。
#3.Dashboard#一个仪表板显示Kibana保存的一系列可视化。你可以根据需要安排和调整可视化,并保存仪表盘,可以被加载和共享。
# 4.Monitoring#该X-pack监控组件使您可以通过Kibana轻松地监控ElasticSearch。您可以实时查看集群的健康和性能,以及分析过去的集群、索引和节点度量。此外,您可以监视Kibana本身性能。当你安装X-pack在群集上,监控代理运行在每个节点上收集和指数指标从Elasticsearch。安装在X-pack在Kibana上,您可以查看通过一套专门的仪表板监控数据。
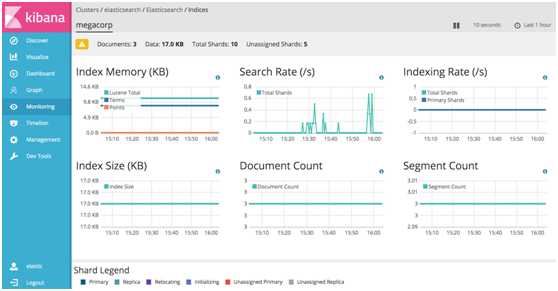
# 5.Graph# X-Pack图的能力使你发现一个Elasticsearch索引项是如何相关联的。你可以探索索引条款之间的连接,看看哪些连接是最有意义的。从欺诈检测到推荐引擎,对各种应用中这都是有用的,例如,图的探索可以帮助你发现网站上黑客的目标的漏洞,所以你可以硬化你的网站。或者,您可以为您的电子商务客户提供基于图表的个性化推荐。X-pack提供简单,但功能强大的图形开发API,和Kibana交互式图形可视化工具。使用X-pack图有工作与开销与现有Elasticsearch指标你不需要任何额外的数据存储的特征。
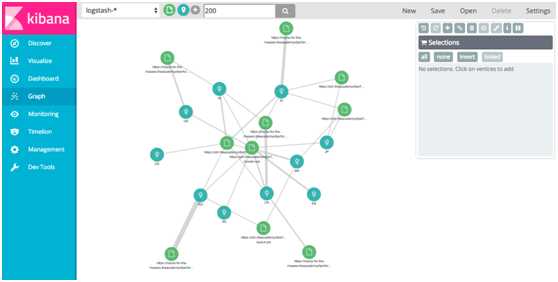
# 6.Timelion#Timelion是一个时间序列数据的可视化,可以结合在一个单一的可视化完全独立的数据源。它是由一个简单的表达式语言驱动的,你用来检索时间序列数据,进行计算,找出复杂的问题的答案,并可视化的结果。
这个功能由一系列的功能函数组成,同样的查询的结果,也可以通过Dashboard显示查看。
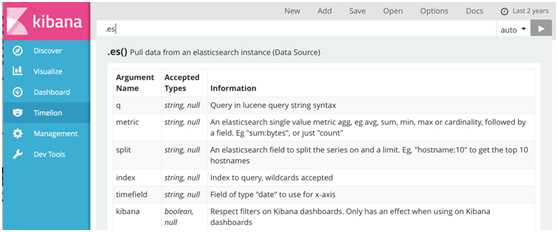
# 7.Management#管理中的应用是在你执行你的运行时配置kibana,包括初始设置和指标进行配置模式,高级设置,调整自己的行为和Kibana,各种“对象”,你可以查看保存在整个Kibana的内容如发现页,可视化和仪表板。
这部分是pluginable,除此之外,X-pack可以给Kibana增加额外的管理能力。
#你可以使用X-pack安全控制哪些用户可以访问Elasticsearch数据通过Kibana。当你安装X-pack,Kibana用户登录。他们需要有kibana_user作用以及获得的指标,他们将在Kibana的工作。如果用户加载Kibana仪表板,访问数据的一个索引,他们未被授权查看,他们得到一个错误,表明指数不存在。X-pack安全目前并不提供一种方法来控制哪些用户可以负荷的仪表板。
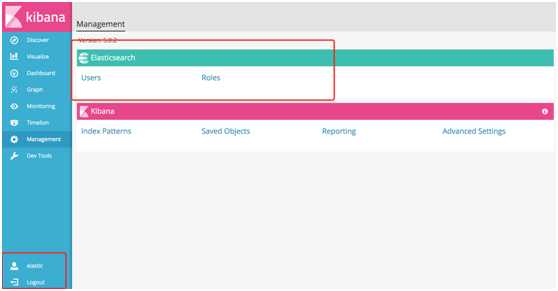
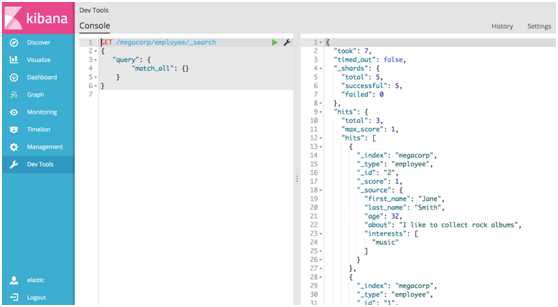
# 8.Dev Tools#原先的交互式控制台Sense,使用户方便的通过浏览器直接与Elasticsearch进行交互。从Kibana 5开始改名并直接内建在Kibana,就是Dev Tools选项
#1.下载中文分词包
wget https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v5.5.2/elasticsearch-analysis-ik-5.5.2.zip
#2解压并安装
1 mv elasticsearch-analysis-ik-5.5.2.zip /tools/elasticsearch-5.5.2/plugins/ 2 cd /tools/elasticsearch-5.5.2/plugins/ 3 unzip elasticsearch-analysis-ik-5.5.2.zip 4 ./bin/elasticsearch restart #重启elasticsearch服务
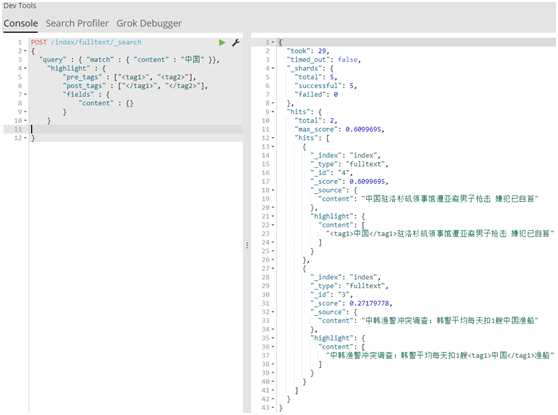
#3.测试中文分词
1 1.批量创建数据 2 curl -XPUT -u elastic http://localhost:9200/index 3 2.创建映射 4 curl -XPOST -u elastic http://localhost:9200/index2/fulltext/_mapping -d‘ 5 { 6 "properties": { 7 "content": { 8 "type": "text", 9 "analyzer": "ik_max_word", 10 "search_analyzer": "ik_max_word" 11 } 12 } 13 }‘ 14 3.搜引文档 15 curl -XPOST -u elastic http://localhost:9200/index2/fulltext/1 -d‘ 16 {"content":"美国留给伊拉克的是个烂摊子吗"} 17 ‘ 18 19 curl -XPOST -u elastic http://localhost:9200/index/fulltext/2 -d‘ 20 {"content":"公安部:各地校车将享最高路权"} 21 ‘ 22 23 curl -XPOST -u elastic http://localhost:9200/index/fulltext/3 -d‘ 24 {"content":"中韩渔警冲突调查:韩警平均每天扣1艘中国渔船"} 25 ‘ 26 27 curl -XPOST -u elastic http://localhost:9200/index/fulltext/4 -d‘ 28 {"content":"中国驻洛杉矶领事馆遭亚裔男子枪击 嫌犯已自首"} 29 ‘ 30 4.查询,以高亮显示 31 curl -XPOST -u elastic http://localhost:9200/index2/fulltext/_search -d‘ 32 { 33 "query" : { "match" : { "content" : "美国" }}, 34 "highlight" : { 35 "pre_tags" : ["<tag1>", "<tag2>"], 36 "post_tags" : ["</tag1>", "</tag2>"], 37 "fields" : { 38 "content" : {} 39 } 40 } 41 } 42 ‘ 43 5.显示查询结果
#由于模拟生产环境,提升计算能力,跨主机集群配置为优选
#1.配置集群之前先配置每台节点主机hosts,下图以测试环境为例:
配置es-node1和es-node2两台主机名称,es-node1为本机主机,如若增加主机节点,可配置es-node3 …,elasticsearch可配置上千节点作为集群服务节点。
vi /etc/hosts 192.168.30.21 es-node1 192.168.30.22 es-node2 192.168.30.23 es-node3
#配置es-node1节点集群配置
1 vi config/elasticsearch.yml 2 cluster.name: wtoip-ipcc-cluster 3 node.name: es-node1 4 http.cors.enabled: true 5 http.cors.allow-origin: "*" 6 node.master: true 7 node.data: true 8 discovery.zen.ping.unicast.hosts: ["es-node1"]
#配置es-node2节点集群配置
1 vi config/elasticsearch.yml
2
3 cluster.name: wtoip-ipcc-cluster
4 node.name: es-node2
5 http.cors.enabled: true
6 http.cors.allow-origin: "*"
7 node.master: false
8 node.data: true
9 discovery.zen.ping.unicast.hosts: ["es-node1"] #指定主节点host名称
#2.节点配置完成后,分别在两台节点服务器中,重启服务即可。
#es-node1节点服务重启
./bin/elasticsearch
#es-node2节点服务重启
./bin/elasticsearch
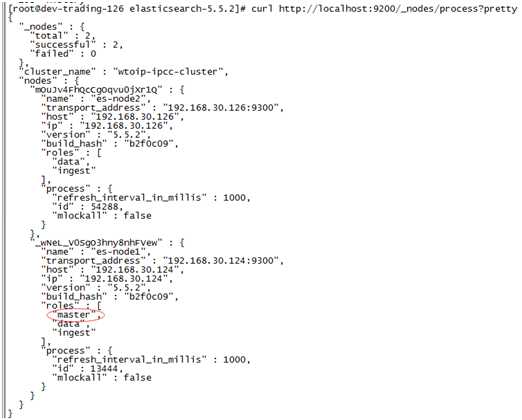
#3.集群节点服务测试,出现如下图所示,表示跨主机集群配置成功。
curl http://localhost:9200/_nodes/process?pretty
标签:群集 访问权限 服务 方法 enable role origin tor increase
原文地址:https://www.cnblogs.com/woodylau/p/9474848.html