标签:ase from collect targe load 分享图片 div 代码 dataset
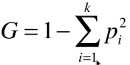
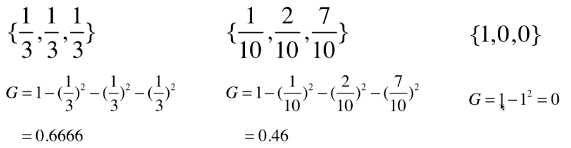
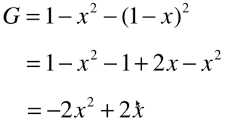
from sklearn.tree import DecisionTreeClassifier dt_clf = DecisionTreeClassifier(max_depth=2, criterion=‘gini‘) dt_clf.fit(X, y)
criterion=‘entropy‘:使用 “信息熵” 方式划分节点数据集;
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets iris = datasets.load_iris() X = iris.data y = iris.target
from collections import Counter from math import log def split(X, y, d, value): index_a = (X[:, d] <= value) index_b = (X[:, d] > value) return X[index_a], X[index_b], y[index_a], y[index_b] def gini(y): counter = Counter(y) res = 1.0 for num in counter.values(): p = num / len(y) res += -p**2 return res def try_split(X, y): best_g = float(‘inf‘) best_d, best_v = -1, -1 for d in range(X.shape[1]): sorted_index = np.argsort(X[:,d]) for i in range(1, len(X)): if X[sorted_index[i-1], d] != X[sorted_index[i], d]: v = (X[sorted_index[i-1], d] + X[sorted_index[i], d]) / 2 x_l, x_r, y_l, y_r = split(X, y, d, v) g = gini(y_l) + gini(y_r) if g < best_g: best_g, best_d, best_v = g, d, v return best_g, best_d, best_v
best_g, best_d, best_v = try_split(X, y) X1_l, X1_r, y1_l, y1_r = split(X, y, best_d, best_v) gini(y1_l) # 数据集 X1_l 的基尼系数:0.0 gini(y1_r) # 数据集 X1_r 的基尼系数:0.5
# 判断:数据集 X1_l 的基尼系数等于 0,不需要再进行划分,;数据集 X1_r 需要再次进行划分;
best_g2, best_d2, best_v2 = try_split(X1_r, y1_r) X2_l, X2_r, y2_l, y2_r = split(X1_r, y1_r, best_d2, best_v2) gini(y2_l) # 数据集 X2_l 的基尼系数:0.1680384087791495 gini(y2_r) # 数据集 X2_l 的基尼系数:0.04253308128544431
# 判断:数据集 X2_l 和 X2_r 的基尼系数不为 0,都需要再次进行划分;
标签:ase from collect targe load 分享图片 div 代码 dataset
原文地址:https://www.cnblogs.com/volcao/p/9478314.html