标签:complete img 不同 特性 ret out 记录 generic ado
前言
本文主要介绍 MapReduce 的原理及开发,讲解如何利用 Combine、Partitioner、WritableComparator等组件对数据进行排序筛选聚合分组的功能。
由于文章是针对开发人员所编写的,在阅读本文前,文章假设读者已经对Hadoop的工作原理、安装过程有一定的了解,因此对Hadoop的安装就不多作说明。请确保源代码运行在Hadoop 2.x以上版本,并以伪分布形式安装以方便进行调试(单机版会对 Partitioner 功能进行限制)。
文章主要利用例子介绍如何利用 MapReduce 模仿 SQL 关系数据库进行SELECT、WHERE、GROUP、JOIN 等操作,并对 GroupingComparator、SortComparator 等功能进行说明。
希望本篇文章能对各位的学习研究有所帮助,当中有所错漏的地方敬请点评。
目录
五、WritableComparatable 自定义键值说明
一、MapReduce 工作原理简介
对Hadoop有兴趣的朋友相信对Hadoop的主要工作原理已经有一定的认识,在讲解MapReduce的程序开发前,本文先针对Mapper、Reducer、Partitioner、Combiner、Suhffle、Sort的工作原理作简单的介绍,以帮助各位更好地了解后面的内容。
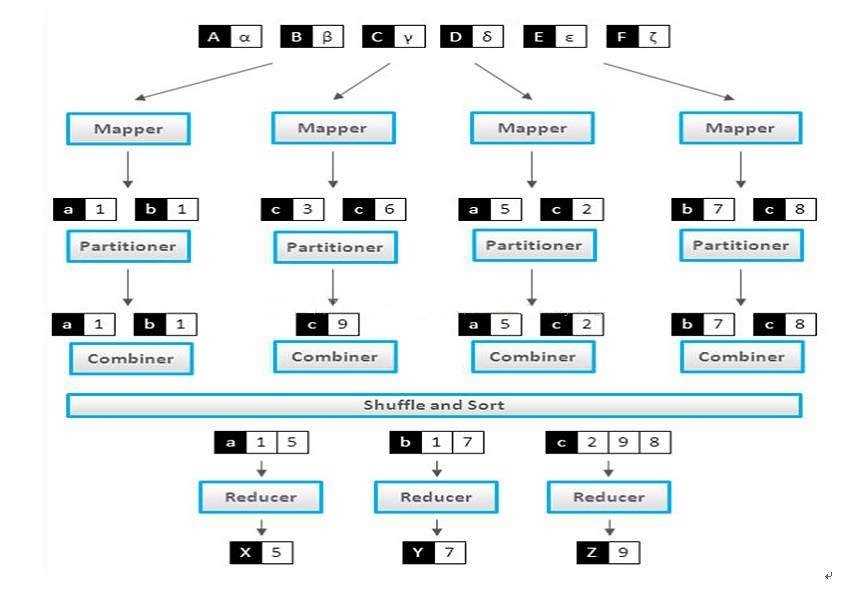
图 1.1
1.1 Mapper 阶段
当系统对数据进行分片后,每个输入分片会分配到一个Mapper任务来处理,默认情况下系统会以HDFS的一个块大小64M作为分片大小,当然也可以通过配置文件设置块的大小。随后Mapper节点输出的数据将保存到一个缓冲区中(缓冲区的大小默认为512M,可通过mapreduce.task.io.sort.mb属性进行修改),缓冲区越大排序效率越高。当该缓冲区快要溢出时(缓冲区默认大小为80%,可通过mapreduce.map.sort.spill.percent属性进行修改),系统会启动一个后台线程,将数据传输到会到本地的一个文件当中。
1.2 Partitioner 阶段
在Mapper完成 KEY/VALUE 格式的数据操作后,Partitioner 将会被调用,由于真实环境中 Hadoop 可能会包含几十个甚至上百个Reducer ,Partitioner 的主要作用就是根据自定义方式确定数据将被传输到哪一个Reducer进行处理。
1.3 Combiner 阶段
如果系统定义了Combiner,在经过 Partitioner 排序处理后将会进行 Combiner处理。我们可以把 Combiner 看作为一个小型的 Reducer ,由于数据从 Mapper 通过网络传送到 Reducer ,资源开销很大,Combiner 目的就是在数据传送到Reducer前作出初步聚集处理,减少服务器的压力。如果数据量太大,还可以把 mapred.compress.map.out 设置为 true,就可以将数据进行压缩。(关于数据压缩的内容已经超越本文的讨论范围,以后会有独立的篇章针对数据压缩进行专题讨论,敬请期待)
1.4 Shuffle 阶段
在 Shuffle 阶段,每个 Reducer 会启动 5 个线程(可通过 mapreduce.reduce.shuffle.parallelcopies 进行设置)通过HTTP协议获取Mapper传送过来的数据。每次数据发送到 Reducer 前,都会根据键先进行排序。开发人员也可通过自定义的 SortComparator ,GroupComparator 根据数据的其他特性进行二次排序,下面章节将会详细举例介绍。对数据进行混洗、排序完成后,将传送到对应的Reducer进行处理。
1.5 Reducer 阶段
当Mapper实例完成数据超过设定值后(可通过mapreduce.job.reduce.slowstart.completedmaps 进行设置), Reducer 就会开始执行。Reducer 会接收到不同 Mapper 任务传来已经过排序的数据,并通过Iterable 接口进行处理。在 Partitioner 阶段,系统已定义哪些数据将由个 Reducer 进行管理。当 Reducer 检测到 KEY 时发生变化时,系统就会按照已定的规则生成一个新的 Reducer 对数据进行处理。
如果 Reducer 端接受的数据量较小,数据则可直接存储在内存缓冲区中,方便后面的数据输出(缓冲区大小可通过mapred.job.shuffle.input.buffer.percent 进行设置)
如果数据量超过了该缓冲区大小的一定比例(可以通过 mapred.job.shuffle.merge.percent 进行设置),数据将会被合并后写到磁盘中。
二、MapReduce 开发实例
上一章节讲解了 MapReduce 的主要流程,下面将以几个简单的例子模仿 SQL 关系数据库向大家介绍一下 MapReduce 的开发过程。
HDFS常用命令 (此处只介绍几个常用命令,详细内容可在网上查找)
2.1 使用 SELECT 获取数据
应用场景:假设在 hdfs 文件夹 / input / 20180509 路径的 *.dat 类型文件中存放在着大量不同型号的 iPhone 手机当天在不同地区的销售记录,系统想对这些记录进行统计,计算出不同型号手机的销售总数。
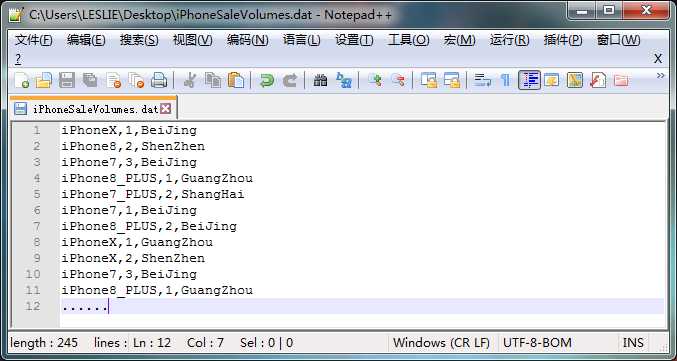
计算时,在Mapper中获取每一行的信息,并把iPhone名称作为Key插入,把数据作为Value插入到Context当中。
当Reducer接收到相同Key数据后,再作统一处理。
注意 : 当前例子当中 Mapper 的输入 Key 为 LongWritable 长类型
在此过程中要注意几点: 例子中 SaleManager 继承了 org.apache.hadoop.conf.Configured 类并实现了 org.apache.hadoop.util.Tool 接口的 public static int run(Configuration conf,Tool tool, String[] args) 方法,MapReduce的相关操作都在run里面实现。由于 Configured 已经实现了 getConf() 与setConfig() 方法,创建Job时相关的配置信息就可通过getConf()方法读入。
系统可以通过以下方法注册Mapper及Reducer处理类
Job.setMapperClass(MyMapper.class);
Job.setReducerClass(MyReducer.class);
在整个运算过程当中,数据会经过筛选与计算,所以Mapper的读入信息K1,V1与Reducer的输出信息K3,V3不一定是同一格式。
org.apache.hadoop.mapreduce.Mapper<K1,V1,K2,V2>
org.apache.hadoop.mapreduce.Reducer<K2,V2,K3,V3>
当Mapper的输出的键值类型与Reduces输出的键值类型相同时,系统可以通过下面方法设置转出数据的格式
Job.setOutputKeyClass(K);
Job.setOutputValueClass(V);
当Mapper的输出的键值类型与Reduces输出的键值类型不相同时,系统则需要通过下面方法设置Mapper转出格式
Job.setMapOutputKeyClass(K);
Job.setMapOutputValueClass(V);
1 public class Phone { 2 public String type; 3 public Integer count; 4 public String area; 5 6 public Phone(String line){ 7 String[] data=line.split(","); 8 this.type=data[0].toString(); 9 this.count=Integer.valueOf(data[1].toString()); 10 this.area=data[2].toString(); 11 } 12 13 public String getType(){ 14 return this.type; 15 } 16 17 public Integer getCount(){ 18 return this.count; 19 } 20 21 public String getArea(){ 22 return this.area; 23 } 24 } 25 26 public class SaleManager extends Configured implements Tool{ 27 public static class MyMapper extends Mapper<LongWritable,Text,Text,IntWritable>{ 28 public void map(LongWritable key,Text value,Context context) 29 throws IOException,InterruptedException{ 30 String data=value.toString(); 31 Phone iPhone=new Phone(data); 32 //以iPhone型号作为Key,数量为作Value传入 33 context.write(new Text(iPhone.getType()), new IntWritable(iPhone.getCount())); 34 } 35 } 36 37 public static class MyReducer extends Reducer<Text,IntWritable,Text,IntWritable>{ 38 public void reduce(Text key,Iterable<IntWritable> values,Context context) 39 throws IOException,InterruptedException{ 40 int sum=0; 41 //对同一型号的iPhone数量进行统计 42 for(IntWritable val : values){ 43 sum+=val.get(); 44 } 45 context.write(key, new IntWritable(sum)); 46 } 47 } 48 49 public int run(String[] arg0) throws Exception { 50 // TODO 自动生成的方法存根 51 // TODO Auto-generated method stub 52 Job job=Job.getInstance(getConf()); 53 job.setJarByClass(SaleManager.class); 54 //注册Key/Value类型为Text 55 job.setOutputKeyClass(Text.class); 56 job.setOutputValueClass(IntWritable.class); 57 //注册Mapper及Reducer处理类 58 job.setMapperClass(MyMapper.class); 59 job.setReducerClass(MyReducer.class); 60 //输入输出数据格式化类型为TextInputFormat 61 job.setInputFormatClass(TextInputFormat.class); 62 job.setOutputFormatClass(TextOutputFormat.class); 63 //默认情况下Reducer数量为1个(可忽略) 64 job.setNumReduceTasks(1); 65 //获取命令参数 66 String[] args=new GenericOptionsParser(getConf(),arg0).getRemainingArgs(); 67 //设置读入文件路径 68 FileInputFormat.setInputPaths(job,new Path(args[0])); 69 //设置转出文件路径 70 FileOutputFormat.setOutputPath(job,new Path(args[1])); 71 boolean status=job.waitForCompletion(true); 72 if(status) 73 return 0; 74 else 75 return 1; 76 } 77 78 public static void main(String[] args) throws Exception{ 79 Configuration conf=new Configuration(); 80 ToolRunner.run(new SaleManager(), args); 81 } 82 }
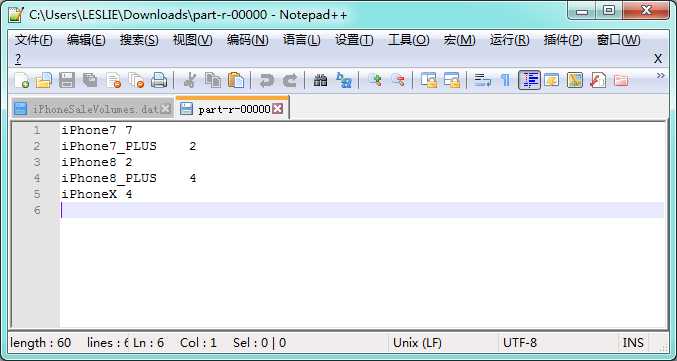
计算结果
2.2 使用 WHERE 对数据进行筛选
在计算过程中,并非所有的数据都适用于Reduce的计算,由于海量数据是通过网络传输的,所消耗的 I/O 资源巨大,所以可以尝试在Mapper过程中提前对数据进行筛选。以上面的数据为例,当前系统只需要计算输入参数地区的销售数据。此时只需要修改一下Mapper类,重写setup方法,通过Configuration类的 public String[] Configuration.getStrings(参数名,默认值) 方法获取命令输入的参数,再对数据进行筛选。
1 public static class MyMapper extends Mapper<LongWritable,Text,Text,IntWritable>{ 2 private String area; 3 4 @Override 5 public void setup(Context context){ 6 this.area=context.getConfiguration().getStrings("area", "BeiJing")[0]; 7 } 8 9 public void map(LongWritable key,Text value,Context context) 10 throws IOException,InterruptedException{ 11 String data=value.toString(); 12 Phone iPhone=new Phone(data); 13 if(this.area.equals(iPhone.area)) 14 context.write(new Text(iPhone.getType()), new IntWritable(iPhone.getCount())); 15 } 16 }
执行命令 hadoop jar 【Jar名称】 【Main类全名称】-D 【参数名=参数值】 【InputPath】 【OutputPath】
例如:hadoop jar hadoopTest-0.2.jar sun.hadoopTest.SaleManager -D area=BeiJing /tmp/input/050901 /tmp/output/050901
此时系统将选择 area 等于BeiJing 的数据进行统计
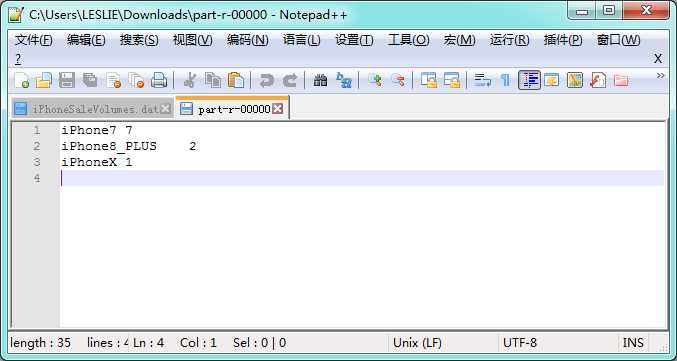
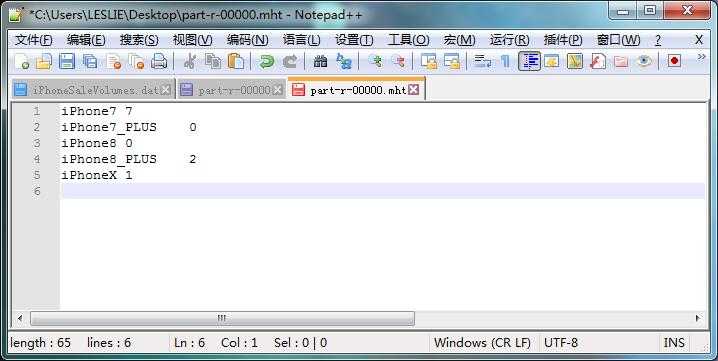
计算结果
三、利用 Partitioner 控制键值分配
3.1 深入分析 Partitioner
Partitioner 类在 org.apache.hadoop.mapreduce.Partitioner 中,通过 Job.setPartitionerClass(Class<? extends Partitioner> cls) 方法可绑定自定义的 Partitioner。若用户没有实现自定义Partitioner 时,系统将自动绑定 Hadoop 的默认类 org.apache.hadoop.mapreduce.lib.partiton.HashPartitioner 。Partitioner 包含一个主要方法是 int getPartition(K key,V value,int numReduceTasks) ,功能是控制将哪些键分配到哪个 Reducer。此方法的返回值是 Reducer 的索引值,若系统定义了4个Reducer,其返回值为0~3。numReduceTasks 侧是当前系统的 Reducer 数量,此数量可通过Job.setNumReduceTasks(int tasks) 进行设置,在伪分布环境下,其默认值为1。
注意:
在单机环境下,系统只会使用一个 Reducer,这将导致 Partitioner 缺乏意义,这也是在本文引言中强调要使用伪分布环境进行调试的原因 。
通过反编译查看 HashPartitioner ,可见系统是通过(key.hashCode() & Interger.MAX_VALUE )%numReduceTasks 方法,根据 KEY 的 HashCode 对 Reducer 数量求余方式,确定数据分配到哪一个 Reducer 进行处理的。但如果想根据用户自定义的逻辑把数据分配到对应 Reducer,单依靠 HashPartitioner 是无法实现的,此时侧需要自定义 Partitioner 。
1 public class HashPartitioner<K, V> extends Partitioner<K, V> { 2 3 public int getPartition(K key, V value, int numReduceTasks) { 4 return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks; 5 } 6 }
3.2 自定义 Partitioner
在例子当中,假设系统需要把北、上、广、深4个不同的地区的iPhone销售情况分别交付给不同 Reducer 进行统计处理。我们可以自定义一个 MyPartitioner, 通过 Job.setPartitionerClass( MyPartitioner.class ) 进行绑定。通过 Job.setNumReduceTasks(4) 设置4个Reducer 。以手机类型作为KEY,把销售数据与地区作为VALUE。在 int getPartition(K key,V value,int numReduceTasks) 方法中,根据 VALUE 值的不同返回不同的索引值。
1 public class Phone { 2 public String type; 3 public Integer count; 4 public String area; 5 6 public Phone(String line){ 7 String[] data=line.split(","); 8 this.type=data[0].toString(); 9 this.count=Integer.valueOf(data[1].toString()); 10 this.area=data[2].toString(); 11 } 12 13 public String getType(){ 14 return this.type; 15 } 16 17 public Integer getCount(){ 18 return this.count; 19 } 20 21 public String getArea(){ 22 return this.area; 23 } 24 } 25 26 public class MyPatitional extends Partitioner<Text,Text> { 27 28 @Override 29 public int getPartition(Text arg0, Text arg1, int arg2) { 30 // TODO 自动生成的方法存根 31 String area=arg1.toString().split(",")[0]; 32 // 根据不同的地区返回不同的索引值 33 if(area.contentEquals("BeiJing")) 34 return 0; 35 if(area.contentEquals("GuangZhou")) 36 return 1; 37 if(area.contentEquals("ShenZhen")) 38 return 2; 39 if(area.contentEquals("ShangHai")) 40 return 3; 41 return 0; 42 } 43 } 44 45 public class SaleManager extends Configured implements Tool{ 46 public static class MyMapper extends Mapper<LongWritable,Text,Text,Text>{ 47 48 public void map(LongWritable key,Text value,Context context) 49 throws IOException,InterruptedException{ 50 String data=value.toString(); 51 Phone iPhone=new Phone(data); 52 context.write(new Text(iPhone.getType()), new Text(iPhone.getArea()+","+iPhone.getCount().toString())); 53 } 54 } 55 56 public static class MyReducer extends Reducer<Text,Text,Text,IntWritable>{ 57 58 public void reduce(Text key,Iterable<Text> values,Context context) 59 throws IOException,InterruptedException{ 60 int sum=0; 61 //对同一型号的iPhone数量进行统计 62 for(Text value : values){ 63 String count=value.toString().split(",")[1]; 64 sum+=Integer.valueOf(count).intValue(); 65 } 66 context.write(key, new IntWritable(sum)); 67 } 68 } 69 70 public int run(String[] arg0) throws Exception { 71 // TODO 自动生成的方法存根 72 // TODO Auto-generated method stub 73 Job job=Job.getInstance(getConf()); 74 job.setJarByClass(SaleManager.class); 75 //注册Key/Value类型为Text 76 job.setOutputKeyClass(Text.class); 77 job.setOutputValueClass(IntWritable.class); 78 //若Map的转出Key/Value不相同是需要分别注册 79 job.setMapOutputKeyClass(Text.class); 80 job.setMapOutputValueClass(Text.class); 81 //注册Mapper及Reducer处理类 82 job.setMapperClass(MyMapper.class); 83 job.setReducerClass(MyReducer.class); 84 //输入输出数据格式化类型为TextInputFormat 85 job.setInputFormatClass(TextInputFormat.class); 86 job.setOutputFormatClass(TextOutputFormat.class); 87 //设置Reduce数量为4个,伪分布式情况下不设置时默认为1 88 job.setNumReduceTasks(4); 89 //注册自定义Partitional类 90 job.setPartitionerClass(MyPatitional.class); 91 //获取命令参数 92 String[] args=new GenericOptionsParser(getConf(),arg0).getRemainingArgs(); 93 //设置读入文件路径 94 FileInputFormat.setInputPaths(job,new Path(args[0])); 95 //设置转出文件路径 96 FileOutputFormat.setOutputPath(job,new Path(args[1])); 97 boolean status=job.waitForCompletion(true); 98 if(status) 99 return 0; 100 else 101 return 1; 102 } 103 104 public static void main(String[] args) throws Exception{ 105 Configuration conf=new Configuration(); 106 ToolRunner.run(new SaleManager(), args); 107 } 108 }
计算结果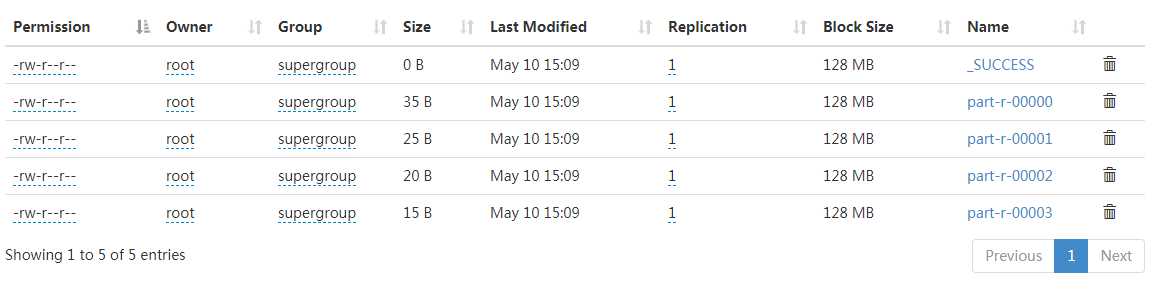
四、利用 Combiner 提高系统性能
在前面几节所描述的例子当中,我们都是把所有的数据完整发送到 Reducer 中再作统计。试想一下,在真实环境当中,iPhone 的销售记录数以千万计,如此巨大的数据需要在 Mapper/Reducer 当中进行传输,将会耗费多少的网络资源。这么多年来 iPhone 出品的机型不过十多个,系统能否先针对同类的机型在Mapper端作出初步的聚合计算,再把计算结果发送到 Reducer。如此一来,传到 Reducer 端的数据量将会大大减少,只要在适当的情形下使用将有利于系统的性能提升。
针对此类问题,Combiner 应运而生,我们可以把 Combiner 看作为一个小型的 Reducer ,它的目的就是在数据传送到Reducer前在Mapper中作出初步聚集处理,减少服务器之间的 I/O 数据传输压力。Combiner 也继承于Reducer,通过Job.setCombinerClass(Class<? extends Reducer> cls) 方法进行注册。
下面继续以第3节的例子作为参考,系统想要在同一个Reducer中计算所有地区不同型号手机的销售情况。我们可以把地区名作为KEY,把销售数量和手机类型转换成 MapWritable 作为 VALUE。当数据输入后,不是直接把数据传输到 Reducer ,而是通过Combiner 把Mapper中不同的型号手机的销售数量进行聚合计算,把5种型号手机的销售总数算好后传输给Reducer。在Reducer中再把来源于不同 Combiner 的数据进行求和,得出最后结果。
注意 :
MapWritable 是 系统自带的 Writable 集合类中的其中一个,它实现了 java.util.Map<Writable,Writable> 接口,以单字节充当类型数据的索引,常用于枚举集合的元素。
1 public class SaleManager extends Configured implements Tool{ 2 private static IntWritable TYPE=new IntWritable(0); 3 private static IntWritable VALUE=new IntWritable(1); 4 private static IntWritable IPHONE7=new IntWritable(2); 5 private static IntWritable IPHONE7_PLUS=new IntWritable(3); 6 private static IntWritable IPHONE8=new IntWritable(4); 7 private static IntWritable IPHONE8_PLUS=new IntWritable(5); 8 private static IntWritable IPHONEX=new IntWritable(6); 9 10 public static class MyMapper extends Mapper<LongWritable,Text,Text,MapWritable>{ 11 12 public void map(LongWritable key,Text value,Context context) 13 throws IOException,InterruptedException{ 14 String data=value.toString(); 15 Phone iPhone=new Phone(data); 16 context.write(new Text(iPhone.getArea()), getMapWritable(iPhone.getType(), iPhone.getCount())); 17 } 18 19 private MapWritable getMapWritable(String type,Integer count){ 20 Text _type=new Text(type); 21 Text _count=new Text(count.toString()); 22 MapWritable mapWritable=new MapWritable(); 23 mapWritable.put(TYPE,_type); 24 mapWritable.put(VALUE,_count); 25 return mapWritable; 26 } 27 } 28 29 public static class MyCombiner extends Reducer<Text,MapWritable,Text,MapWritable> { 30 public void reduce(Text key,Iterable<MapWritable> values,Context context) 31 throws IOException, InterruptedException{ 32 int iPhone7=0; 33 int iPhone7_PLUS=0; 34 int iPhone8=0; 35 int iPhone8_PLUS=0; 36 int iPhoneX=0; 37 //对同一个Mapper所处理的不同型号的手机数据进行初步统计 38 for(MapWritable value:values){ 39 String type=value.get(TYPE).toString(); 40 Integer count=Integer.valueOf(value.get(VALUE).toString()); 41 if(type.contentEquals("iPhone7")) 42 iPhone7+=count; 43 if(type.contentEquals("iPhone7_PLUS")) 44 iPhone7_PLUS+=count; 45 if(type.contentEquals("iPhone8")) 46 iPhone8+=count; 47 if(type.contentEquals("iPhone8_PLUS")) 48 iPhone8_PLUS+=count; 49 if(type.contentEquals("iPhoneX")) 50 iPhoneX+=count; 51 } 52 MapWritable mapWritable=new MapWritable(); 53 mapWritable.put(IPHONE7, new IntWritable(iPhone7)); 54 mapWritable.put(IPHONE7_PLUS, new IntWritable(iPhone7_PLUS)); 55 mapWritable.put(IPHONE8, new IntWritable(iPhone8)); 56 mapWritable.put(IPHONE8_PLUS, new IntWritable(iPhone8_PLUS)); 57 mapWritable.put(IPHONEX, new IntWritable(iPhoneX)); 58 context.write(key,mapWritable); 59 } 60 } 61 62 public static class MyReducer extends Reducer<Text,MapWritable,Text,Text>{ 63 public void reduce(Text key,Iterable<MapWritable> values,Context context) 64 throws IOException,InterruptedException{ 65 int iPhone7=0; 66 int iPhone7_PLUS=0; 67 int iPhone8=0; 68 int iPhone8_PLUS=0; 69 int iPhoneX=0; 70 71 //对同一地区不同型的iPhone数量进行统计 72 for(MapWritable value : values){ 73 iPhone7+=Integer.parseInt(value.get(IPHONE7).toString()); 74 iPhone7_PLUS+=Integer.parseInt(value.get(IPHONE7_PLUS).toString()); 75 iPhone8+=Integer.parseInt(value.get(IPHONE8).toString()); 76 iPhone8_PLUS+=Integer.parseInt(value.get(IPHONE8_PLUS).toString()); 77 iPhoneX+=Integer.parseInt(value.get(IPHONEX).toString()); 78 } 79 80 StringBuffer data=new StringBuffer(); 81 data.append("iPhone7:"+iPhone7+" "); 82 data.append("iPhone7_PLUS:"+iPhone7_PLUS+" "); 83 data.append("iPhone8:"+iPhone8+" "); 84 data.append("iPhone8_PLUS:"+iPhone8_PLUS+" "); 85 data.append("iPhoneX:"+iPhoneX+" "); 86 context.write(key, new Text(data.toString())); 87 } 88 } 89 90 public int run(String[] arg0) throws Exception { 91 // TODO 自动生成的方法存根 92 // TODO Auto-generated method stub 93 Job job=Job.getInstance(getConf()); 94 job.setJarByClass(SaleManager.class); 95 //注册Key/Value类型为Text 96 job.setOutputKeyClass(Text.class); 97 job.setOutputValueClass(Text.class); 98 //若Map的转出Key/Value不相同是需要分别注册 99 job.setMapOutputKeyClass(Text.class); 100 job.setMapOutputValueClass(MapWritable.class); 101 //注册Mapper及Reducer处理类 102 job.setMapperClass(MyMapper.class); 103 job.setReducerClass(MyReducer.class); 104 //注册Combiner处理类 105 job.setCombinerClass(MyCombiner.class); 106 //输入输出数据格式化类型为TextInputFormat 107 job.setInputFormatClass(TextInputFormat.class); 108 job.setOutputFormatClass(TextOutputFormat.class); 109 //伪分布式情况下不设置时默认为1 110 job.setNumReduceTasks(1); 111 //获取命令参数 112 String[] args=new GenericOptionsParser(getConf(),arg0).getRemainingArgs(); 113 //设置读入文件路径 114 FileInputFormat.setInputPaths(job,new Path(args[0])); 115 //设置转出文件路径 116 FileOutputFormat.setOutputPath(job,new Path(args[1])); 117 boolean status=job.waitForCompletion(true); 118 if(status) 119 return 0; 120 else 121 return 1; 122 } 123 124 public static void main(String[] args) throws Exception{ 125 Configuration conf=new Configuration(); 126 ToolRunner.run(new SaleManager(), args); 127 } 128 }
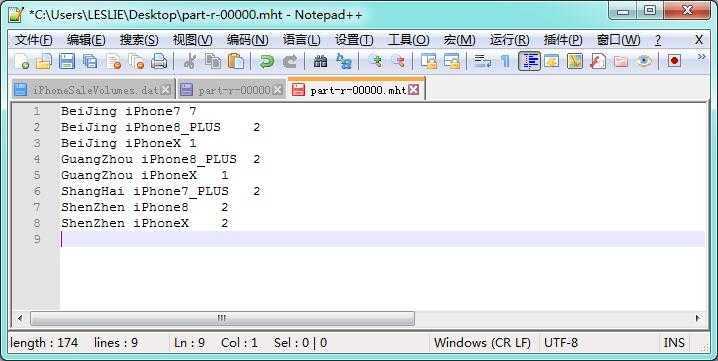
计算结果
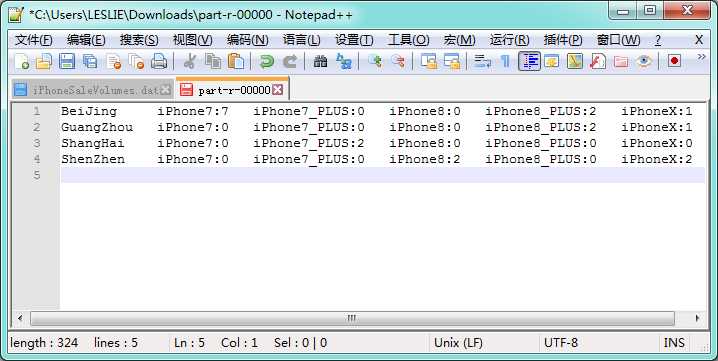
五、WritableComparable自定义键值说明
5.1 Writable、Comparable、WritableComparable 之间关系
在 Mapper 与 Reducer 中使用到的键类型、值类型都必须实现 Writable 接口,而键类型侧需要实现 WritableComparable,它们之间的关系如下图:
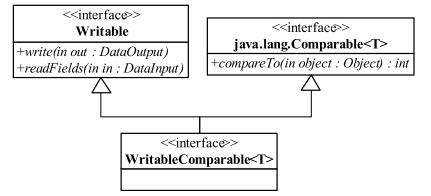
Writable 接口有两个方法
Comparable 接口中 int compareTo(object) 方法侧定义了排序的方式,如果返回值为0(判断为两个对象相等),侧被同一个 reduce 方法处理,一旦两个对象不相等,系统就会生成另一个 reduce 处理。
5.2 自定义值类型
以第三节的例子作为讨论,假设系统需要把北、上、广、深4个不同的地区的iPhone销售情况分别交付给4个不同 Reducer 节点进行统计处理。使用地区 area 作为Key,使用继承 Writable 接口的PhoneValue作为 Value 值类型,实现 write 方法与 readFields 方法,最后在 reduce 方法区分不同的型号进行计算。
1 public class Phone { 2 public String type; 3 public Integer count; 4 public String area; 5 6 public Phone(String line){ 7 String[] data=line.split(","); 8 this.type=data[0].toString().trim(); 9 this.count=Integer.valueOf(data[1].toString().trim()); 10 this.area=data[2].toString().trim(); 11 } 12 13 public String getType(){ 14 return this.type; 15 } 16 17 public Integer getCount(){ 18 return this.count; 19 } 20 21 public String getArea(){ 22 return this.area; 23 } 24 } 25 26 public class PhoneValue implements Writable { 27 public Text type=new Text(); 28 public IntWritable count=new IntWritable(); 29 public Text area=new Text(); 30 31 public PhoneValue(){ 32 33 } 34 35 public PhoneValue(String type,Integer count,String area){ 36 this.type=new Text(type); 37 this.count=new IntWritable(count); 38 this.area=new Text(area); 39 } 40 41 public Text getType() { 42 return type; 43 } 44 45 public void setType(Text type) { 46 this.type = type; 47 } 48 49 public IntWritable getCount() { 50 return count; 51 } 52 53 public void setCount(IntWritable count) { 54 this.count = count; 55 } 56 57 public Text getArea() { 58 return area; 59 } 60 61 public void setArea(Text area) { 62 this.area = area; 63 } 64 65 @Override 66 public void readFields(DataInput arg0) throws IOException { 67 // TODO 自动生成的方法存根 68 this.type.readFields(arg0); 69 this.count.readFields(arg0); 70 this.area.readFields(arg0); 71 } 72 73 @Override 74 public void write(DataOutput arg0) throws IOException { 75 // TODO 自动生成的方法存根 76 this.type.write(arg0); 77 this.count.write(arg0); 78 this.area.write(arg0); 79 } 80 } 81 82 public class SaleManager extends Configured implements Tool{ 83 84 public static class MyMapper extends Mapper<LongWritable,Text,Text,PhoneValue>{ 85 86 public void map(LongWritable key,Text value,Context context) 87 throws IOException,InterruptedException{ 88 String data=value.toString(); 89 Phone iPhone=new Phone(data); 90 PhoneValue phoneValue=new PhoneValue(iPhone.getType(),iPhone.getCount(),iPhone.getArea()); 91 context.write(new Text(iPhone.getArea()), phoneValue); 92 } 93 } 94 95 public static class MyReducer extends Reducer<Text,PhoneValue,Text,Text>{ 96 Integer iPhone7=new Integer(0); 97 Integer iPhone7_PLUS=new Integer(0); 98 Integer iPhone8=new Integer(0); 99 Integer iPhone8_PLUS=new Integer(0); 100 Integer iPhoneX=new Integer(0); 101 102 public void reduce(Text key,Iterable<PhoneValue> values,Context context) 103 throws IOException,InterruptedException{ 104 //对不同类型iPhone数量进行统计 105 for(PhoneValue phone : values){ 106 int count=phone.getCount().get(); 107 108 if(phone.type.toString().equals("iPhone7")) 109 iPhone7+=count; 110 if(phone.type.toString().equals("iPhone7_PLUS")) 111 iPhone7_PLUS+=count; 112 if(phone.type.toString().equals("iPhone8")) 113 iPhone8+=count; 114 if(phone.type.toString().equals("iPhone8_PLUS")) 115 iPhone8_PLUS+=count; 116 if(phone.type.toString().equals("iPhoneX")) 117 iPhoneX+=count; 118 } 119 120 context.write(new Text("iPhone7"), new Text(iPhone7.toString())); 121 context.write(new Text("iPhone7_PLUS"), new Text(iPhone7_PLUS.toString())); 122 context.write(new Text("iPhone8"), new Text(iPhone8.toString())); 123 context.write(new Text("iPhone8_PLUS"), new Text(iPhone8_PLUS.toString())); 124 context.write(new Text("iPhoneX"), new Text(iPhoneX.toString())); 125 } 126 } 127 128 public int run(String[] arg0) throws Exception { 129 // TODO 自动生成的方法存根 130 // TODO Auto-generated method stub 131 Job job=Job.getInstance(getConf()); 132 job.setJarByClass(SaleManager.class); 133 //注册Key/Value类型为Text 134 job.setOutputKeyClass(Text.class); 135 job.setOutputValueClass(Text.class); 136 //若Map的转出Key/Value不相同是需要分别注册 137 job.setMapOutputKeyClass(Text.class); 138 job.setMapOutputValueClass(PhoneValue.class); 139 //注册Mapper及Reducer处理类 140 job.setMapperClass(MyMapper.class); 141 job.setReducerClass(MyReducer.class); 142 //输入输出数据格式化类型为TextInputFormat 143 job.setInputFormatClass(TextInputFormat.class); 144 job.setOutputFormatClass(TextOutputFormat.class); 145 //伪分布式情况下不设置时默认为1 146 job.setNumReduceTasks(4); 147 //获取命令参数 148 String[] args=new GenericOptionsParser(getConf(),arg0).getRemainingArgs(); 149 //设置读入文件路径 150 FileInputFormat.setInputPaths(job,new Path(args[0])); 151 //设置转出文件路径 152 FileOutputFormat.setOutputPath(job,new Path(args[1])); 153 boolean status=job.waitForCompletion(true); 154 if(status) 155 return 0; 156 else 157 return 1; 158 } 159 160 public static void main(String[] args) throws Exception{ 161 Configuration conf=new Configuration(); 162 ToolRunner.run(new SaleManager(), args); 163 } 164 }
计算结果与第三节相同
5.3 自定义键类型
Hadoop 常用的类 IntWritable、LongWritable、Text、BooleanWritable 等都实现了WritableComparable 接口,当用户需要自定义键类型时,只需要实现WritableComparable接口即可。public boolean equals(Object o) 与 public int hashCode() 都是 Object 的方法,回顾本文的第三节可以看到 hashCode 会被系统默认的 Partitioner 即 HashPartitioner 类所使用。在使用系统默认的 HashPartitioner 类时,一旦 hashCode 相等,数据将返回到同一个Reducer 节点,因此应该按业务的需求重新定义键类型的 hashCode。同时 equals 方法应该按照 hashCode 逻辑统一修改,避免在使用 Hash 散列时出现逻辑错误。
以第三节的例子作为讨论,假设系统需要把北、上、广、深4个不同的地区的iPhone销售情况分别交付给不同 Reducer 节点进行统计处理,我们只需要定义 PhoneKey 作为键类型,当中包含地区号 area 和型号 type。在 hashCode 中以地区号 area 作为指标,在 compareTo 方法中我们以手机的类型 type 进行排序。系统就可在不同的 Reducer 节点中计算出同一地点不同类型手机的销售情况。
1 public class Phone { 2 public String type; 3 public Integer count; 4 public String area; 5 6 public Phone(String line){ 7 String[] data=line.split(","); 8 this.type=data[0].toString().trim(); 9 this.count=Integer.valueOf(data[1].toString().trim()); 10 this.area=data[2].toString().trim(); 11 } 12 13 public String getType(){ 14 return this.type; 15 } 16 17 public Integer getCount(){ 18 return this.count; 19 } 20 21 public String getArea(){ 22 return this.area; 23 } 24 } 25 26 public class PhoneKey implements WritableComparable<PhoneKey> { 27 public Text type=new Text(); 28 public Text area=new Text(); 29 30 public PhoneKey(){ 31 32 } 33 34 public PhoneKey(String type,String area){ 35 this.type=new Text(type); 36 this.area=new Text(area); 37 } 38 39 public Text getType() { 40 return type; 41 } 42 43 public void setType(Text type) { 44 this.type = type; 45 } 46 47 public Text getArea() { 48 return area; 49 } 50 51 public void setArea(Text area) { 52 this.area = area; 53 } 54 55 @Override 56 public void readFields(DataInput arg0) throws IOException { 57 // TODO 自动生成的方法存根 58 this.type.readFields(arg0); 59 this.area.readFields(arg0); 60 } 61 62 @Override 63 public void write(DataOutput arg0) throws IOException { 64 // TODO 自动生成的方法存根 65 this.type.write(arg0); 66 this.area.write(arg0); 67 } 68 69 @Override 70 public int compareTo(PhoneKey o) { 71 // TODO 自动生成的方法存根 72 return this.type.compareTo(o.type); 73 } 74 75 @Override 76 public boolean equals(Object o){ 77 if(!(o instanceof PhoneKey)){ 78 return false; 79 } 80 PhoneKey phone=(PhoneKey) o; 81 return this.area.equals(phone.area); 82 } 83 84 @Override 85 public int hashCode(){ 86 return this.area.hashCode(); 87 } 88 } 89 90 public class SaleManager extends Configured implements Tool{ 91 92 public static class MyMapper extends Mapper<LongWritable,Text,PhoneKey,IntWritable>{ 93 94 public void map(LongWritable key,Text value,Context context) 95 throws IOException,InterruptedException{ 96 String data=value.toString(); 97 Phone iPhone=new Phone(data); 98 PhoneKey phoneKey=new PhoneKey(iPhone.getType(),iPhone.getArea()); 99 context.write(phoneKey, new IntWritable(iPhone.count)); 100 } 101 } 102 103 public static class MyReducer extends Reducer<PhoneKey,IntWritable,Text,Text>{ 104 public void reduce(PhoneKey phoneKey,Iterable<IntWritable> values,Context context) 105 throws IOException,InterruptedException{ 106 String type=phoneKey.getType().toString(); 107 Integer total=new Integer(0); 108 //对不同类型iPhone数量进行统计 109 for(IntWritable count : values){ 110 total+=count.get(); 111 } 112 context.write(new Text(type),new Text(total.toString())); 113 } 114 } 115 116 public int run(String[] arg0) throws Exception { 117 // TODO 自动生成的方法存根 118 // TODO Auto-generated method stub 119 Job job=Job.getInstance(getConf()); 120 job.setJarByClass(SaleManager.class); 121 //注册Key/Value类型为Text 122 job.setOutputKeyClass(Text.class); 123 job.setOutputValueClass(Text.class); 124 //若Map的转出Key/Value不相同是需要分别注册 125 job.setMapOutputKeyClass(PhoneKey.class); 126 job.setMapOutputValueClass(IntWritable.class); 127 //注册Mapper及Reducer处理类 128 job.setMapperClass(MyMapper.class); 129 job.setReducerClass(MyReducer.class); 130 //输入输出数据格式化类型为TextInputFormat 131 job.setInputFormatClass(TextInputFormat.class); 132 job.setOutputFormatClass(TextOutputFormat.class); 133 //伪分布式情况下不设置时默认为1 134 job.setNumReduceTasks(4); 135 //获取命令参数 136 String[] args=new GenericOptionsParser(getConf(),arg0).getRemainingArgs(); 137 //设置读入文件路径 138 FileInputFormat.setInputPaths(job,new Path(args[0])); 139 //设置转出文件路径 140 FileOutputFormat.setOutputPath(job,new Path(args[1])); 141 boolean status=job.waitForCompletion(true); 142 if(status) 143 return 0; 144 else 145 return 1; 146 } 147 148 public static void main(String[] args) throws Exception{ 149 Configuration conf=new Configuration(); 150 ToolRunner.run(new SaleManager(), args); 151 } 152 }
计算结果与第三节相同
在这个例子中只是为了让大家更好地了解自定义键类型的使用方法,而在真实环境中,自定义键类型,主要作为区分数据的标准。如果需要更好地平衡服务器资源,分配 Reducer 数据处理的负荷,还是要通过自定义的 Partitioner 进行管理。
六、实现数据排序与分组处理
6.1 RawComparator 接口介绍
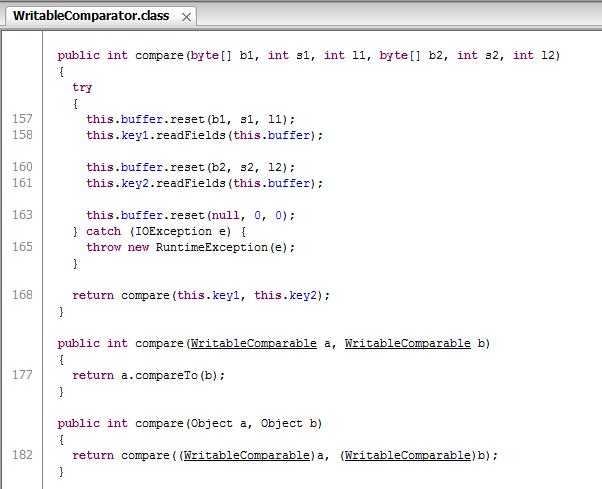
在实际的应用场景当中,很可能会用到第三方类库作为键类型,但我们无法直接对源代码进行修改。为此系统定义了 RawComparator 接口,假设第三方类已实现了 Writable 接口,用户可通过自定义类实现 RawComparator 接口,通过 job.setSortComparatorClass(rawComparator.class) 设置即可。RawComparator 继承了 java.util.Comparator 接口,并添加了 int compare(byte[] b1,int s1, int l1,byte[] b2 ,int s2, int l2) 方法。此方法最简单的实现方式是通过 Writable 实例中的 readField 重构对象,然后使用通用类的 compareTo 完成排序。
public interface RawComparator<T> extends Comparator<T> {
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2);
}
下面例子假设 PhoneWritable 是第三方类库中的值类型,我们无法直接修改,但系统需要把 PhoneWritable 用作 KEY 处理,按照不同地区不同型号进行排序计算出手机的销售情况。此时可建立 PhoneComparator 类并实现 RawComparator 接口,在主程序中通过 job.setSortComparatorClass(PhoneComparator.class) 设置此接口的实现类。
1 public class Phone { 2 public String type; 3 public Integer count; 4 public String area; 5 6 public Phone(String line){ 7 String[] data=line.split(","); 8 this.type=data[0].toString().trim(); 9 this.count=Integer.valueOf(data[1].toString().trim()); 10 this.area=data[2].toString().trim(); 11 } 12 13 public String getType(){ 14 return this.type; 15 } 16 17 public Integer getCount(){ 18 return this.count; 19 } 20 21 public String getArea(){ 22 return this.area; 23 } 24 } 25 26 public class PhoneWritable implements Writable { 27 public Text type=new Text(); 28 public IntWritable count=new IntWritable(); 29 public Text area=new Text(); 30 31 public PhoneWritable(){ 32 33 } 34 35 public PhoneWritable(String type,Integer count,String area){ 36 this.type=new Text(type); 37 this.count=new IntWritable(count); 38 this.area=new Text(area); 39 } 40 41 public Text getType() { 42 return type; 43 } 44 45 public void setType(Text type) { 46 this.type = type; 47 } 48 49 public IntWritable getCount() { 50 return count; 51 } 52 53 public void setCount(IntWritable count) { 54 this.count = count; 55 } 56 57 public Text getArea() { 58 return area; 59 } 60 61 public void setArea(Text area) { 62 this.area = area; 63 } 64 65 @Override 66 public void readFields(DataInput arg0) throws IOException { 67 // TODO 自动生成的方法存根 68 this.type.readFields(arg0); 69 this.count.readFields(arg0); 70 this.area.readFields(arg0); 71 } 72 73 @Override 74 public void write(DataOutput arg0) throws IOException { 75 // TODO 自动生成的方法存根 76 this.type.write(arg0); 77 this.count.write(arg0); 78 this.area.write(arg0); 79 } 80 } 81 82 public class PhoneComparator implements RawComparator<PhoneWritable> { 83 private DataInputBuffer buffer=null; 84 private PhoneWritable phone1=null; 85 private PhoneWritable phone2=null; 86 87 public PhoneComparator(){ 88 buffer=new DataInputBuffer(); 89 phone1=new PhoneWritable(); 90 phone2=new PhoneWritable(); 91 } 92 93 @Override 94 public int compare(PhoneWritable o1, PhoneWritable o2) { 95 // TODO 自动生成的方法存根 96 if(!o1.getArea().equals(o2.getArea())) 97 return o1.getArea().compareTo(o2.getArea()); 98 else 99 return o1.getType().compareTo(o2.getType()); 100 } 101 102 @Override 103 public int compare(byte[] arg0, int arg1, int arg2, byte[] arg3, int arg4, int arg5) { 104 // TODO 自动生成的方法存根 105 try { 106 buffer.reset(arg0,arg1,arg2); 107 phone1.readFields(buffer); 108 buffer.reset(arg3,arg4,arg5); 109 phone2.readFields(buffer); 110 } catch (IOException e) { 111 // TODO 自动生成的 catch 块 112 e.printStackTrace(); 113 } 114 return this.compare(phone1, phone2); 115 } 116 117 } 118 119 public class SaleManager extends Configured implements Tool{ 120 121 public static class MyMapper extends Mapper<LongWritable,Text,PhoneWritable,IntWritable>{ 122 123 public void map(LongWritable key,Text value,Context context) 124 throws IOException,InterruptedException{ 125 String data=value.toString(); 126 Phone iPhone=new Phone(data); 127 PhoneWritable phone=new PhoneWritable(iPhone.getType(),iPhone.getCount(),iPhone.getArea()); 128 context.write(phone, phone.getCount()); 129 } 130 } 131 132 public static class MyReducer extends Reducer<PhoneWritable,IntWritable,Text,Text>{ 133 public void reduce(PhoneWritable phone,Iterable<IntWritable> values,Context context) 134 throws IOException,InterruptedException{ 135 //对不同类型iPhone数量进行统计 136 Integer total=new Integer(0); 137 138 for(IntWritable count : values){ 139 total+=count.get(); 140 } 141 context.write(new Text(phone.getArea()+" "+phone.getType()),new Text(total.toString())); 142 } 143 } 144 145 public int run(String[] arg0) throws Exception { 146 // TODO 自动生成的方法存根 147 // TODO Auto-generated method stub 148 Job job=Job.getInstance(getConf()); 149 job.setJarByClass(SaleManager.class); 150 //注册Key/Value类型为Text 151 job.setOutputKeyClass(Text.class); 152 job.setOutputValueClass(Text.class); 153 //若Map的转出Key/Value不相同是需要分别注册 154 job.setMapOutputKeyClass(PhoneWritable.class); 155 job.setSortComparatorClass(PhoneComparator.class); 156 job.setMapOutputValueClass(IntWritable.class); 157 //注册Mapper及Reducer处理类 158 job.setMapperClass(MyMapper.class); 159 job.setReducerClass(MyReducer.class); 160 //输入输出数据格式化类型为TextInputFormat 161 job.setInputFormatClass(TextInputFormat.class); 162 job.setOutputFormatClass(TextOutputFormat.class); 163 //伪分布式情况下不设置时默认为1 164 job.setNumReduceTasks(1); 165 //获取命令参数 166 String[] args=new GenericOptionsParser(getConf(),arg0).getRemainingArgs(); 167 //设置读入文件路径 168 FileInputFormat.setInputPaths(job,new Path(args[0])); 169 //设置转出文件路径 170 FileOutputFormat.setOutputPath(job,new Path(args[1])); 171 boolean status=job.waitForCompletion(true); 172 if(status) 173 return 0; 174 else 175 return 1; 176 } 177 178 public static void main(String[] args) throws Exception{ 179 Configuration conf=new Configuration(); 180 ToolRunner.run(new SaleManager(), args); 181 } 182 }
计算结果
6.2 WritableComparator 类介绍
WritableComparator 是系统自带的接口 RawComparartor 实现类,它实现了 RawComparator 接口的两个基础方法 int compare(object , object ) 与 int compare(byte[] b1,int s1, int l1,byte[] b2 ,int s2, int l2)
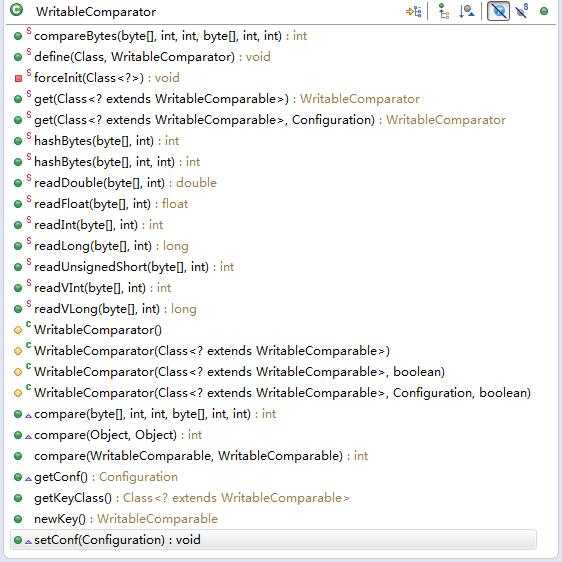
通过反编译查看源代码可知道,系统也是通过 WritableComparable 接口的 readField 方法重构对象,然后调用 int compareTo (WritableComparable,WritableComparable) 方法完成排序的。因此一般情况下我们在继承 WritableComparator 类实现排序时,只需要重构此方法实现业务逻辑即可。
6.3 利用 WritableComparator 实现数据排序
假设系统原有的键类型 PhoneKey 是以手机类型 type作为排序标准,现在我们需要通过 WritableComparator 把排序标准修改为按先按地区 area 再按类型 type 排序。按照第上节所述,我们只需要继承 WritableComparator 类,重写 int compareTo (WritableComparable,WritableComparable),按照地区 area 及 类型 type 进行排序,最后使用 job.setSortComparatorClass(Class<? extends RawComparator> cls) 设置排序方式即可。
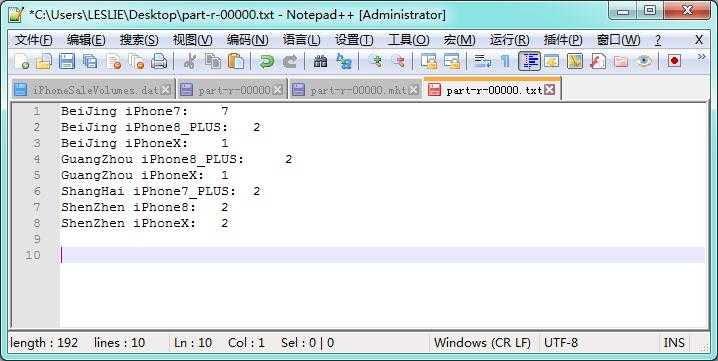
1 public class Phone { 2 public String type; 3 public Integer count; 4 public String area; 5 6 public Phone(String line){ 7 String[] data=line.split(","); 8 this.type=data[0].toString().trim(); 9 this.count=Integer.valueOf(data[1].toString().trim()); 10 this.area=data[2].toString().trim(); 11 } 12 13 public String getType(){ 14 return this.type; 15 } 16 17 public Integer getCount(){ 18 return this.count; 19 } 20 21 public String getArea(){ 22 return this.area; 23 } 24 } 25 26 public class PhoneKey implements WritableComparable<PhoneKey> { 27 public Text type=new Text(); 28 public Text area=new Text(); 29 30 public PhoneKey(){ 31 32 } 33 34 public PhoneKey(String type,String area){ 35 this.type=new Text(type); 36 this.area=new Text(area); 37 } 38 39 public Text getType() { 40 return type; 41 } 42 43 public void setType(Text type) { 44 this.type = type; 45 } 46 47 public Text getArea() { 48 return area; 49 } 50 51 public void setArea(Text area) { 52 this.area = area; 53 } 54 55 @Override 56 public void readFields(DataInput arg0) throws IOException { 57 // TODO 自动生成的方法存根 58 this.type.readFields(arg0); 59 this.area.readFields(arg0); 60 } 61 62 @Override 63 public void write(DataOutput arg0) throws IOException { 64 // TODO 自动生成的方法存根 65 this.type.write(arg0); 66 this.area.write(arg0); 67 } 68 69 @Override 70 public int compareTo(PhoneKey o) { 71 // TODO 自动生成的方法存根 72 return this.type.compareTo(o.type); 73 } 74 75 @Override 76 public boolean equals(Object o){ 77 if(!(o instanceof PhoneKey)){ 78 return false; 79 } 80 PhoneKey phone=(PhoneKey) o; 81 return this.area.equals(phone.area); 82 } 83 84 @Override 85 public int hashCode(){ 86 return this.area.hashCode(); 87 } 88 } 89 90 public class PhoneSortComparator extends WritableComparator{ 91 92 public PhoneSortComparator(){ 93 super(PhoneKey.class,true); 94 } 95 96 @Override 97 public int compare(WritableComparable a,WritableComparable b){ 98 PhoneKey key1=(PhoneKey) a; 99 PhoneKey key2=(PhoneKey) b; 100 if(!key1.getArea().equals(key2.getArea())) 101 return key1.getArea().compareTo(key2.getArea()); 102 else 103 return key1.getType().compareTo(key2.getType()); 104 } 105 } 106 107 public class SaleManager extends Configured implements Tool{ 108 109 public static class MyMapper extends Mapper<LongWritable,Text,PhoneKey,IntWritable>{ 110 111 public void map(LongWritable key,Text value,Context context) 112 throws IOException,InterruptedException{ 113 String data=value.toString(); 114 Phone iPhone=new Phone(data); 115 PhoneKey phone=new PhoneKey(iPhone.getType(),iPhone.getArea()); 116 context.write(phone, new IntWritable(iPhone.getCount())); 117 } 118 } 119 120 public static class MyReducer extends Reducer<PhoneKey,IntWritable,Text,Text>{ 121 public void reduce(PhoneKey phone,Iterable<IntWritable> values,Context context) 122 throws IOException,InterruptedException{ 123 //对不同类型iPhone数量进行统计 124 Integer total=new Integer(0); 125 126 for(IntWritable count : values){ 127 total+=count.get(); 128 } 129 context.write(new Text(phone.getArea()+" "+phone.getType()+": "),new Text(total.toString())); 130 } 131 } 132 133 public int run(String[] arg0) throws Exception { 134 // TODO 自动生成的方法存根 135 // TODO Auto-generated method stub 136 Job job=Job.getInstance(getConf()); 137 job.setJarByClass(SaleManager.class); 138 //注册Key/Value类型为Text 139 job.setOutputKeyClass(Text.class); 140 job.setOutputValueClass(Text.class); 141 //若Map的转出Key/Value不相同是需要分别注册 142 job.setMapOutputKeyClass(PhoneKey.class); 143 job.setMapOutputValueClass(IntWritable.class); 144 //设置排序类型 SortComparator 145 job.setSortComparatorClass(PhoneSortComparator.class); 146 //注册Mapper及Reducer处理类 147 job.setMapperClass(MyMapper.class); 148 job.setReducerClass(MyReducer.class); 149 //输入输出数据格式化类型为TextInputFormat 150 job.setInputFormatClass(TextInputFormat.class); 151 job.setOutputFormatClass(TextOutputFormat.class); 152 //伪分布式情况下不设置时默认为1 153 job.setNumReduceTasks(1); 154 //获取命令参数 155 String[] args=new GenericOptionsParser(getConf(),arg0).getRemainingArgs(); 156 //设置读入文件路径 157 FileInputFormat.setInputPaths(job,new Path(args[0])); 158 //设置转出文件路径 159 FileOutputFormat.setOutputPath(job,new Path(args[1])); 160 boolean status=job.waitForCompletion(true); 161 if(status) 162 return 0; 163 else 164 return 1; 165 } 166 167 public static void main(String[] args) throws Exception{ 168 Configuration conf=new Configuration(); 169 ToolRunner.run(new SaleManager(), args); 170 } 171 }
从计算结果可以看到数据是先按照地区 area 再按手机型号 type 进行排序的
6.4 利用 WritableComparator 实现数据分组
在 6.3 节的例子中,数据是先按照地区号 area 再按手机类型 type 进行排序的,因此在 reduce 方法中根据 Iterable 集合计算出来的将会同一地区同一类型的手机。若此时需要对同一地区所有手机类型的销售情况进行合计,可以使用 GroupingComparator 分组计算方式 。其方法是继承 WritableComparator 类,重写 int compareTo (WritableComparable,WritableComparable),以地区号 area 作为分组标识,最后使用 job.setGroupComparatorClass(Class<? extends RawComparator> cls) 设置分组方式即可。
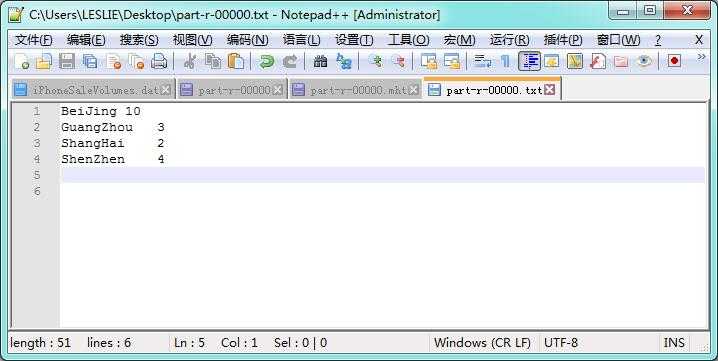
1 public class Phone { 2 public String type; 3 public Integer count; 4 public String area; 5 6 public Phone(String line){ 7 String[] data=line.split(","); 8 this.type=data[0].toString().trim(); 9 this.count=Integer.valueOf(data[1].toString().trim()); 10 this.area=data[2].toString().trim(); 11 } 12 13 public String getType(){ 14 return this.type; 15 } 16 17 public Integer getCount(){ 18 return this.count; 19 } 20 21 public String getArea(){ 22 return this.area; 23 } 24 } 25 26 public class PhoneKey implements WritableComparable<PhoneKey> { 27 public Text type=new Text(); 28 public Text area=new Text(); 29 30 public PhoneKey(){ 31 32 } 33 34 public PhoneKey(String type,String area){ 35 this.type=new Text(type); 36 this.area=new Text(area); 37 } 38 39 public Text getType() { 40 return type; 41 } 42 43 public void setType(Text type) { 44 this.type = type; 45 } 46 47 public Text getArea() { 48 return area; 49 } 50 51 public void setArea(Text area) { 52 this.area = area; 53 } 54 55 @Override 56 public void readFields(DataInput arg0) throws IOException { 57 // TODO 自动生成的方法存根 58 this.type.readFields(arg0); 59 this.area.readFields(arg0); 60 } 61 62 @Override 63 public void write(DataOutput arg0) throws IOException { 64 // TODO 自动生成的方法存根 65 this.type.write(arg0); 66 this.area.write(arg0); 67 } 68 69 @Override 70 public int compareTo(PhoneKey o) { 71 // TODO 自动生成的方法存根 72 return this.type.compareTo(o.type); 73 } 74 75 @Override 76 public boolean equals(Object o){ 77 if(!(o instanceof PhoneKey)){ 78 return false; 79 } 80 PhoneKey phone=(PhoneKey) o; 81 return this.area.equals(phone.area); 82 } 83 84 @Override 85 public int hashCode(){ 86 return this.area.hashCode(); 87 } 88 } 89 90 public class PhoneSortComparator extends WritableComparator{ 91 92 public PhoneSortComparator(){ 93 super(PhoneKey.class,true); 94 } 95 96 @Override 97 public int compare(WritableComparable a,WritableComparable b){ 98 PhoneKey key1=(PhoneKey) a; 99 PhoneKey key2=(PhoneKey) b; 100 if(!key1.getArea().equals(key2.getArea())) 101 return key1.getArea().compareTo(key2.getArea()); 102 else 103 return key1.getType().compareTo(key2.getType()); 104 } 105 } 106 107 public class PhoneGroupComparator extends WritableComparator{ 108 109 public PhoneGroupComparator(){ 110 super(PhoneKey.class,true); 111 } 112 113 @Override 114 public int compare(WritableComparable a,WritableComparable b){ 115 PhoneKey key1=(PhoneKey) a; 116 PhoneKey key2=(PhoneKey) b; 117 return key1.getArea().compareTo(key2.getArea()); 118 } 119 } 120 121 public class SaleManager extends Configured implements Tool{ 122 123 public static class MyMapper extends Mapper<LongWritable,Text,PhoneKey,IntWritable>{ 124 125 public void map(LongWritable key,Text value,Context context) 126 throws IOException,InterruptedException{ 127 String data=value.toString(); 128 Phone iPhone=new Phone(data); 129 PhoneKey phone=new PhoneKey(iPhone.getType(),iPhone.getArea()); 130 context.write(phone, new IntWritable(iPhone.getCount())); 131 } 132 } 133 134 public static class MyReducer extends Reducer<PhoneKey,IntWritable,Text,Text>{ 135 public void reduce(PhoneKey phone,Iterable<IntWritable> values,Context context) 136 throws IOException,InterruptedException{ 137 //对不同类型iPhone数量进行统计 138 Integer total=new Integer(0); 139 140 for(IntWritable count : values){ 141 total+=count.get(); 142 } 143 context.write(new Text(phone.getArea()),new Text(total.toString())); 144 } 145 } 146 147 public int run(String[] arg0) throws Exception { 148 Job job=Job.getInstance(getConf()); 149 job.setJarByClass(SaleManager.class); 150 //注册Key/Value类型为Text 151 job.setOutputKeyClass(Text.class); 152 job.setOutputValueClass(Text.class); 153 //若Map的转出Key/Value不相同是需要分别注册 154 job.setMapOutputKeyClass(PhoneKey.class); 155 job.setMapOutputValueClass(IntWritable.class); 156 //设置排序类型 SortComparator 157 job.setSortComparatorClass(PhoneSortComparator.class); 158 //设置分组类型GroupComparator 159 job.setGroupingComparatorClass(PhoneGroupComparator.class); 160 //注册Mapper及Reducer处理类 161 job.setMapperClass(MyMapper.class); 162 job.setReducerClass(MyReducer.class); 163 //输入输出数据格式化类型为TextInputFormat 164 job.setInputFormatClass(TextInputFormat.class); 165 job.setOutputFormatClass(TextOutputFormat.class); 166 //伪分布式情况下不设置时默认为1 167 job.setNumReduceTasks(1); 168 //获取命令参数 169 String[] args=new GenericOptionsParser(getConf(),arg0).getRemainingArgs(); 170 //设置读入文件路径 171 FileInputFormat.setInputPaths(job,new Path(args[0])); 172 //设置转出文件路径 173 FileOutputFormat.setOutputPath(job,new Path(args[1])); 174 boolean status=job.waitForCompletion(true); 175 if(status) 176 return 0; 177 else 178 return 1; 179 } 180 181 public static void main(String[] args) throws Exception{ 182 Configuration conf=new Configuration(); 183 ToolRunner.run(new SaleManager(), args); 184 } 185 }
计算结果
注意:一般情况下 job.setSortComparatorClass(Class<? extends RawComparator> cls) 与 job.setGroupComparatorClass(Class<? extends RawComparator> cls) 应该同时调用。若只设置了排序方式 SortComparator 而没有调用 job.setGroupComparatorClass(Class<? extends RawComparator> cls) 方法,则 GroupComparator 分组方式视为与 SortComparator 一致。
这也是 6.3 节在没有设置 GroupComparator 的情况下系统会按照 area 与 type 进行分组计算的原因。
七、数据集连接处理方式介绍
在处理关系数据库时,经常会遇到外连接,内连接等复杂数据查询,在 Hadoop 的数据集处理上同样会遇上类似问题。当数据源来源于不同数据集时,Hadoop 框架提供了2种不同的方法实现合并查询。
7.1 Map 端连接介绍
假设有这样一个使用场景:在 *.gds 结尾的数据集中记录了所有手机的编号 number、类型 type 、单价 price,由于手机类型有限,所以数据量较小。在 *.sal 结尾的数据集中记录了每个客户名称 name 与其所购买的手机编号 number,数量 count,总体价格 total,由于订单数据具大,所以数据量比较庞大。此时,我们可以在 map 方法运行前,在 setup 方法中通过 job.addCacheFile(URI)把手机型号的数据加载到缓存当中,在读入销售订单数据时,从缓存中查询对应的手机型号,合并数据后一同发送到 Reduce 端。
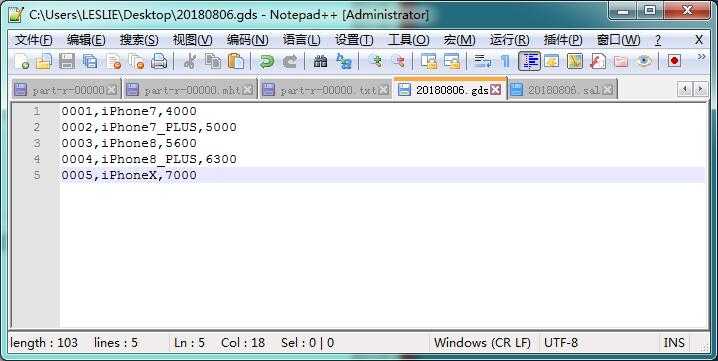
*.gds 数据
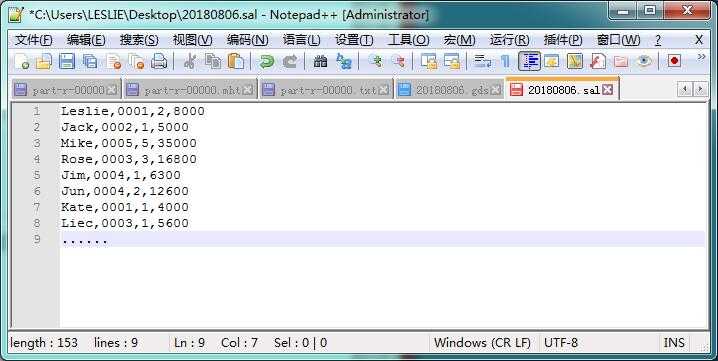
*.sal 数据
1 public class Goods { 2 public Text number; 3 public Text type; 4 public IntWritable price; 5 6 public Goods(String[] dataline){ 7 this.number=new Text(dataline[0]); 8 this.type=new Text(dataline[1]); 9 this.price=new IntWritable(Integer.valueOf(dataline[2])); 10 } 11 12 public Text getNumber() { 13 return number; 14 } 15 16 public void setNumber(Text number) { 17 this.number = number; 18 } 19 20 public Text getType() { 21 return type; 22 } 23 24 public void setType(Text type) { 25 this.type = type; 26 } 27 28 public IntWritable getPrice() { 29 return price; 30 } 31 32 public void setPrice(IntWritable price) { 33 this.price = price; 34 } 35 } 36 37 public class OrderWritable implements Writable{ 38 public Text name=new Text(); 39 public Text number=new Text(); 40 public Text type=new Text(); 41 public IntWritable price=new IntWritable(); 42 public IntWritable count=new IntWritable(); 43 public IntWritable total=new IntWritable(); 44 45 public OrderWritable(){ 46 47 } 48 49 public OrderWritable(String[] data,Goods goods){ 50 this.name=new Text(data[0]); 51 this.number=new Text(data[1]); 52 this.type=goods.getType(); 53 this.price=goods.getPrice(); 54 this.count=new IntWritable(new Integer(data[2])); 55 this.total=new IntWritable(new Integer(data[3])); 56 } 57 58 public Text getName() { 59 return name; 60 } 61 public void setName(Text name) { 62 this.name = name; 63 } 64 public Text getNumber() { 65 return number; 66 } 67 public void setNumber(Text number) { 68 this.number = number; 69 } 70 public Text getType() { 71 return type; 72 } 73 public void setType(Text type) { 74 this.type = type; 75 } 76 public IntWritable getPrice() { 77 return price; 78 } 79 80 public void setPrice(IntWritable price) { 81 this.price = price; 82 } 83 public IntWritable getCount() { 84 return count; 85 } 86 public void setCount(IntWritable count) { 87 this.count = count; 88 } 89 public IntWritable getTotal() { 90 return total; 91 } 92 public void setTotal(IntWritable total) { 93 this.total = total; 94 } 95 96 @Override 97 public void readFields(DataInput in) throws IOException { 98 // TODO 自动生成的方法存根 99 this.name.readFields(in); 100 this.number.readFields(in); 101 this.type.readFields(in); 102 this.price.readFields(in); 103 this.count.readFields(in); 104 this.total.readFields(in); 105 } 106 107 @Override 108 public void write(DataOutput out) throws IOException { 109 // TODO 自动生成的方法存根 110 this.name.write(out); 111 this.number.write(out); 112 this.type.write(out); 113 this.price.write(out); 114 this.count.write(out); 115 this.total.write(out); 116 } 117 } 118 119 public class MapJoinExample extends Configured implements Tool{ 120 121 public static class MyMapper extends Mapper<LongWritable,Text,Text,OrderWritable>{ 122 private Map<String,Goods> map=new HashMap<String,Goods>(); 123 private Configuration conf; 124 125 //读取该URI下的文件,把文件中的goods放入map中存储 126 private void read(URI uri){ 127 try { 128 FileSystem file=FileSystem.get(uri,conf); 129 FSDataInputStream hdfsInStream = file.open(new Path(uri)); 130 InputStreamReader isr = new InputStreamReader(hdfsInStream); 131 BufferedReader br = new BufferedReader(isr); 132 String line; 133 while ((line = br.readLine()) != null) { 134 Goods goods=new Goods(line.split(",")); 135 map.put(goods.getNumber().toString(), goods); 136 } 137 } catch (IOException e) { 138 // TODO 自动生成的 catch 块 139 e.printStackTrace(); 140 } 141 } 142 143 public void setup(Context context){ 144 //获取配置 145 conf=context.getConfiguration(); 146 //按照输入路径读取文件 147 try{ 148 URI[] uris=context.getCacheFiles(); 149 if(uris[0].toString().endsWith("gds")){ 150 read(uris[0]); 151 } 152 }catch(Exception ex){ 153 throw new RuntimeException(ex); 154 } 155 } 156 157 public void map(LongWritable key,Text value,Context context) 158 throws IOException,InterruptedException{ 159 String[] datalist=value.toString().split(","); 160 Goods goods=map.get(datalist[1]); 161 if(goods!=null){ 162 OrderWritable order=new OrderWritable(datalist,goods); 163 context.write(goods.getNumber(), order); 164 } 165 } 166 } 167 168 public static class MyReducer extends Reducer<Text,OrderWritable,Text,Text>{ 169 public void reduce(Text number,Iterable<OrderWritable> orders,Context context) 170 throws IOException,InterruptedException{ 171 172 for(OrderWritable order : orders) 173 context.write(number,new Text(order.getName()+","+order.getType() 174 +","+order.getPrice().toString()+","+order.getCount().toString() 175 +","+order.getTotal().toString())); 176 } 177 } 178 179 public int run(String[] arg0) throws Exception { 180 // TODO 自动生成的方法存根 181 // TODO Auto-generated method stub 182 Job job=Job.getInstance(getConf()); 183 job.setJarByClass(MapJoinExample.class); 184 //注册Key/Value类型为Text 185 job.setOutputKeyClass(Text.class); 186 job.setOutputValueClass(Text.class); 187 //若Map的转出Key/Value不相同是需要分别注册 188 job.setMapOutputKeyClass(Text.class); 189 job.setMapOutputValueClass(OrderWritable.class); 190 //注册Mapper及Reducer处理类 191 job.setMapperClass(MyMapper.class); 192 job.setReducerClass(MyReducer.class); 193 //输入输出数据格式化类型为TextInputFormat 194 job.setInputFormatClass(TextInputFormat.class); 195 job.setOutputFormatClass(TextOutputFormat.class); 196 //获取命令参数 197 String[] args=new GenericOptionsParser(getConf(),arg0).getRemainingArgs(); 198 //设置读入文件路径 199 FileInputFormat.setInputPaths(job,new Path(args[0])); 200 //设置转出文件路径 201 FileOutputFormat.setOutputPath(job,new Path(args[1])); 202 //加入缓存文件 203 job.addCacheFile(new URI(args[2])); 204 boolean status=job.waitForCompletion(true); 205 if(status) 206 return 0; 207 else 208 return 1; 209 } 210 211 public static void main(String[] args) throws Exception{ 212 Configuration conf=new Configuration(); 213 ToolRunner.run(new MapJoinExample(), args); 214 } 215 }
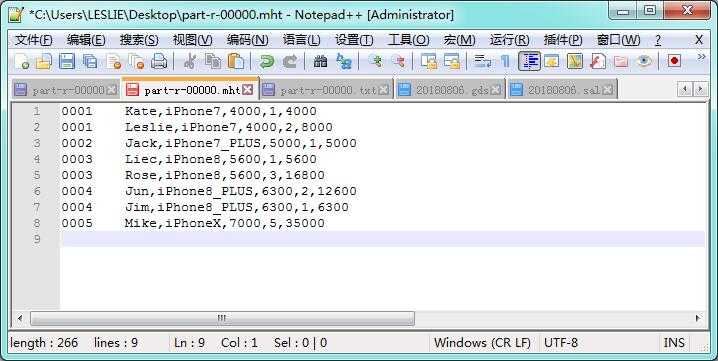
执行命令 hadoop jar 【Jar名称】 【Main类全名称】【InputPath】 【OutputPath】 【*.gds 数据的URI】
当中最后一个参数正是 *.gds 数据集的 HDFS 路径,可见执行结果如下:
7.2 Reduce 端连接介绍
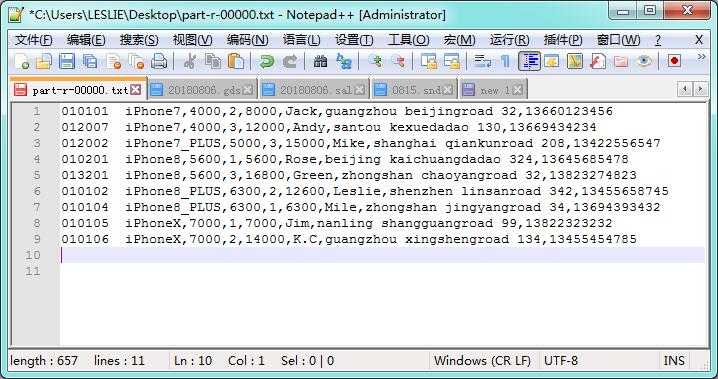
假设有以下的一个应用场景,在 Hadoop 数据集中存储了商品的订单数据 *.odr ,当中包含了订单号 orderCode,商品 goods,单价 price,数量 count,总体价格 total。在另一个数据集中存储了商品的送货信息 *.snd,当中包含中订单号 orderCode,商品 goods,送货地址 address,收货人 name,电话号码 tel。由于数据集的数据是一对一关系,所以数据量都非常具大,无法在 Mapper 端实现缓存扩展的方式。此时,可以通过系统提供的 MultipleInputs 类实现多个 Mapper 数据输入,不同的数据格式由不同的 Mapper 类进行处理。通过设置 GroupingComparator 按需要把连接键的属性作为分组处理的标识,最后在 Reduce 端把具有相同特性的数据进行合并处理。
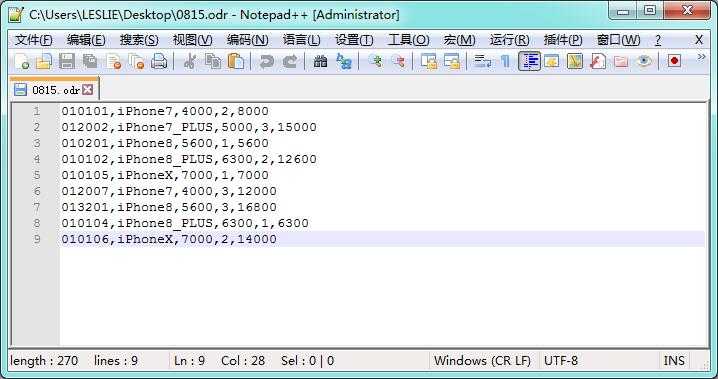
*.odr 订单数据
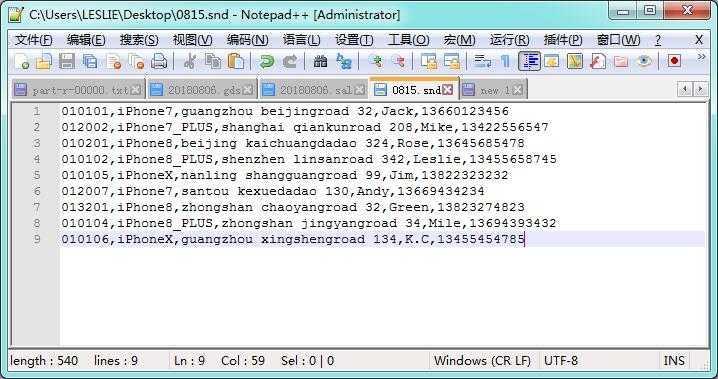
*.snd 送货数据
我们把订单号 orderCode 与商品 goods 作为了键的两个属性,目的在排序时先按商品类型再按订单号进行排序,而 type 值是用于区分此键的数据是来源于订单数据集还是送货单数据集。在设置 GroupComparator 时,我们把商品 goods 作为标识,把同一类商品的订单交付到同一个reduce方法中进行处理。最后通过 MultipleInputs.addInputPath (Job job, Path path, Class<? extends InputFormat> inputFormatClass, Class<? extends Mapper> mapperClass) 方法绑定不同数据集的 Mapper 处理方式。
1 public class DispatchKey implements WritableComparable<DispatchKey> { 2 3 public static final IntWritable TYPE_ORDER=new IntWritable(0); 4 public static final IntWritable TYPE_SEND=new IntWritable(1); 5 ////数据类型,当前数据类型为订单时为0,当前数据类型为送货单时为1 6 public IntWritable type=new IntWritable(); 7 public Text orderCode=new Text(); 8 public Text goods=new Text(); 9 10 @Override 11 public void readFields(DataInput in) throws IOException { 12 // TODO 自动生成的方法存根 13 this.type.readFields(in); 14 this.orderCode.readFields(in); 15 this.goods.readFields(in); 16 } 17 18 @Override 19 public void write(DataOutput out) throws IOException { 20 // TODO 自动生成的方法存根 21 this.type.write(out); 22 this.orderCode.write(out); 23 this.goods.write(out); 24 } 25 26 @Override 27 public int compareTo(DispatchKey key) { 28 // 先按商品类型,再按订单号进行排序 29 if(this.goods.equals(key.goods)){ 30 if(this.orderCode.equals(key.orderCode)) 31 return this.type.compareTo(key.type); 32 else 33 return this.orderCode.compareTo(key.orderCode); 34 } 35 else 36 return this.goods.compareTo(key.goods); 37 } 38 39 @Override 40 public boolean equals(Object o){ 41 if(!(o instanceof DispatchKey)){ 42 return false; 43 } 44 45 DispatchKey key=(DispatchKey) o; 46 if(this.orderCode.equals(key.orderCode)&&this.goods.equals(key.orderCode)&& 47 (this.type.get()==key.type.get())) 48 return true; 49 return false; 50 } 51 52 @Override 53 public int hashCode(){ 54 return (this.orderCode.toString()+this.goods.toString() 55 +this.type.toString()).hashCode(); 56 } 57 58 } 59 60 public class DispatchValue implements Writable { 61 public Text order=new Text(); 62 public IntWritable price=new IntWritable(); 63 public IntWritable count=new IntWritable(); 64 public IntWritable total=new IntWritable(); 65 public Text address=new Text(); 66 public Text name=new Text(); 67 public Text tel=new Text(); 68 69 @Override 70 public void readFields(DataInput in) throws IOException { 71 // TODO 自动生成的方法存根 72 this.order.readFields(in); 73 this.price.readFields(in); 74 this.count.readFields(in); 75 this.total.readFields(in); 76 this.address.readFields(in); 77 this.name.readFields(in); 78 this.tel.readFields(in); 79 } 80 81 @Override 82 public void write(DataOutput out) throws IOException { 83 // TODO 自动生成的方法存根 84 this.order.write(out); 85 this.price.write(out); 86 this.count.write(out); 87 this.total.write(out); 88 this.address.write(out); 89 this.name.write(out); 90 this.tel.write(out); 91 } 92 93 } 94 95 public class DispatchSortComparator extends WritableComparator{ 96 97 public DispatchSortComparator(){ 98 super(DispatchKey.class,true); 99 } 100 } 101 102 public class DispatchGroupComparator extends WritableComparator{ 103 104 public DispatchGroupComparator(){ 105 super(DispatchKey.class,true); 106 } 107 108 @Override 109 public int compare(WritableComparable a,WritableComparable b){ 110 DispatchKey key1=(DispatchKey) a; 111 DispatchKey key2=(DispatchKey) b; 112 return key1.goods.compareTo(key2.goods); 113 } 114 } 115 116 public class MapJoinExample extends Configured implements Tool{ 117 118 public static class OrderMapper extends Mapper<LongWritable,Text,DispatchKey,DispatchValue>{ 119 120 public void map(LongWritable longwritable,Text text,Context context) 121 throws IOException,InterruptedException{ 122 String[] data=text.toString().split(","); 123 DispatchKey key=new DispatchKey(); 124 //设置KEY的类型为订单 125 key.type=DispatchKey.TYPE_ORDER; 126 key.orderCode=new Text(data[0]); 127 key.goods=new Text(data[1]); 128 DispatchValue value=new DispatchValue(); 129 value.order=new Text(data[0]); 130 value.price=new IntWritable(new Integer(data[2])); 131 value.count=new IntWritable(new Integer(data[3])); 132 value.total=new IntWritable(new Integer(data[4])); 133 context.write(key, value); 134 } 135 } 136 137 public static class SendMapper extends Mapper<LongWritable,Text,DispatchKey,DispatchValue>{ 138 139 public void map(LongWritable longwritable,Text text,Context context) 140 throws IOException,InterruptedException{ 141 String[] data=text.toString().split(","); 142 DispatchKey key=new DispatchKey(); 143 //设置KEY类型为送货单 144 key.type=DispatchKey.TYPE_SEND; 145 key.orderCode=new Text(data[0]); 146 key.goods=new Text(data[1]); 147 DispatchValue value=new DispatchValue(); 148 value.order=new Text(data[0]); 149 value.address=new Text(data[2]); 150 value.name=new Text(data[3]); 151 value.tel=new Text(data[4]); 152 context.write(key, value); 153 } 154 } 155 156 public static class MyReducer extends Reducer<DispatchKey,DispatchValue,Text,Text>{ 157 public void reduce(DispatchKey key,Iterable<DispatchValue> values,Context context) 158 throws IOException,InterruptedException{ 159 String mes="unknow"; 160 String orderCode="unknow"; 161 162 for(DispatchValue value : values){ 163 //当数据为订单数据时进行记录 164 if(key.type.equals(DispatchKey.TYPE_ORDER)){ 165 orderCode=key.orderCode.toString(); 166 mes=key.goods.toString()+","+value.price.toString()+"," 167 +value.count.toString()+","+value.total.toString()+","; 168 }//当数据为送货数据且订单号相等时追加记录 169 else if(key.type.equals(DispatchKey.TYPE_SEND) 170 &&key.orderCode.toString().equals(orderCode)){ 171 mes+=value.name.toString()+","+value.address.toString()+","+value.tel.toString(); 172 context.write(key.orderCode, new Text(mes)); 173 //清空记录 174 orderCode="unknow"; 175 mes="unkonw"; 176 } 177 } 178 } 179 } 180 181 public int run(String[] arg0) throws Exception { 182 // TODO 自动生成的方法存根 183 // TODO Auto-generated method stub 184 Job job=Job.getInstance(getConf()); 185 job.setJarByClass(MapJoinExample.class); 186 //注册Key/Value类型为Text 187 job.setOutputKeyClass(Text.class); 188 job.setOutputValueClass(Text.class); 189 //若Map的转出Key/Value不相同是需要分别注册 190 job.setMapOutputKeyClass(DispatchKey.class); 191 job.setMapOutputValueClass(DispatchValue.class); 192 //设置排序类型 SortComparator 193 job.setSortComparatorClass(DispatchSortComparator.class); 194 //设置分组类型 195 job.setGroupingComparatorClass(DispatchGroupComparator.class); 196 //注册Mapper及Reducer处理类 197 //job.setMapperClass(OrderMapper.class); 198 job.setReducerClass(MyReducer.class); 199 //输入输出数据格式化类型为TextInputFormat 200 job.setInputFormatClass(TextInputFormat.class); 201 job.setOutputFormatClass(TextOutputFormat.class); 202 //获取命令参数 203 String[] args=new GenericOptionsParser(getConf(),arg0).getRemainingArgs(); 204 //设置Order数据处理Mapper 205 MultipleInputs.addInputPath(job, new Path(args[0]), TextInputFormat.class,OrderMapper.class); 206 //设置Send数据处理Mapper 207 MultipleInputs.addInputPath(job, new Path(args[1]), TextInputFormat.class,SendMapper.class); 208 //设置输出路径 209 FileOutputFormat.setOutputPath(job, new Path(args[2])); 210 211 boolean status=job.waitForCompletion(true); 212 if(status) 213 return 0; 214 else 215 return 1; 216 } 217 218 public static void main(String[] args) throws Exception{ 219 Configuration conf=new Configuration(); 220 ToolRunner.run(new MapJoinExample(), args); 221 } 222 }
执行命令 hadoop jar 【Jar名称】 【Main类全名称】【OrderMapperInputPath】 【SendMapperInputPath】【OutputPath】 可以到以下计算结果。
注意系统是通过 String[] args=new GenericOptionsParser(getConf(),arg0).getRemainingArgs() 来获取输入参数的,所以执行时注意参数的输入顺序与代码获取参数时保持一致。
本章主要介绍了 MapReduce 的开发原理及应用场景,讲解如何利用 Combine、Partitioner、WritableComparable、WritableComparator 等组件对数据进行排序筛选聚合分组的功能。对多数据集的连接查询进行分析,介绍如何通过 Map 端与 Reduce 端对多数据集连接进行处理。
后面的文章将会进一步对 Apache Hive 的应用,HBase 的集成进行讲解,敬请期待。
希望本篇文章能对各位的学习研究有所帮助,由于时间比较仓促,当中有所错漏的地方欢迎点评。
对 JAVA 开发有兴趣的朋友欢迎加入QQ群:174850571 共同探讨!对 .NET 开发有兴趣的朋友欢迎加入QQ群:230564952 共同探讨 !
服务类工具的应用与管理
Windows Server 2008 R2 负载平衡入门篇
数字证书应用综合揭秘(包括证书生成、加密、解密、签名、验签)
作者:风尘浪子
https://www.cnblogs.com/leslies2/p/9009574.html
原创作品,转载时请注明作者及出处
Hadoop 综合揭秘——MapReduce 编程实例(详细介绍 Combine、Partitioner、WritableComparable、WritableComparator 使用方式)
标签:complete img 不同 特性 ret out 记录 generic ado
原文地址:https://www.cnblogs.com/leslies2/p/9009574.html