标签:sch spark集群 thread rate message 本地 ror register for
一般情况下,我们启动spark集群都是start-all.sh或者是先启动master(start-master.sh),然后在启动slave节点(start-slaves.sh),其实翻看start-all.sh文件里面的代码,可以发现它里面其实调用的执行的也是start-master.sh和start-slaves.sh文件的内容:
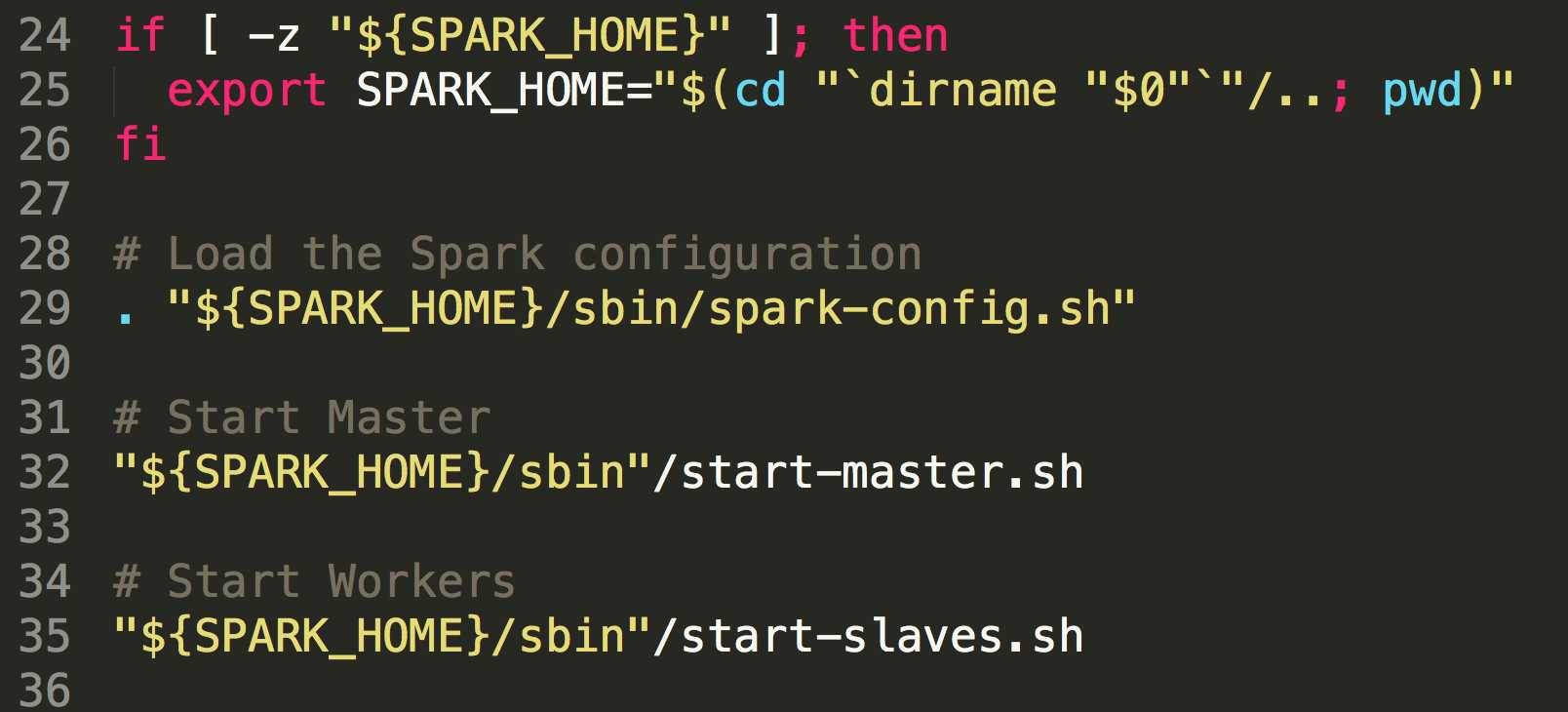
在start-master.sh中定义了CLASS="org.apache.spark.deploy.master.Master" ,最终调用其main方法启动master服务,在start-slaves.sh文件中有调用了start-slave.sh内容,只是定义了
CLASS="org.apache.spark.deploy.worker.Worker"来启动worker。
接下来先看master中的main方法,在main方法中调用了startRpcEnvAndEndpoint()方法,来定义并启动消息通信。
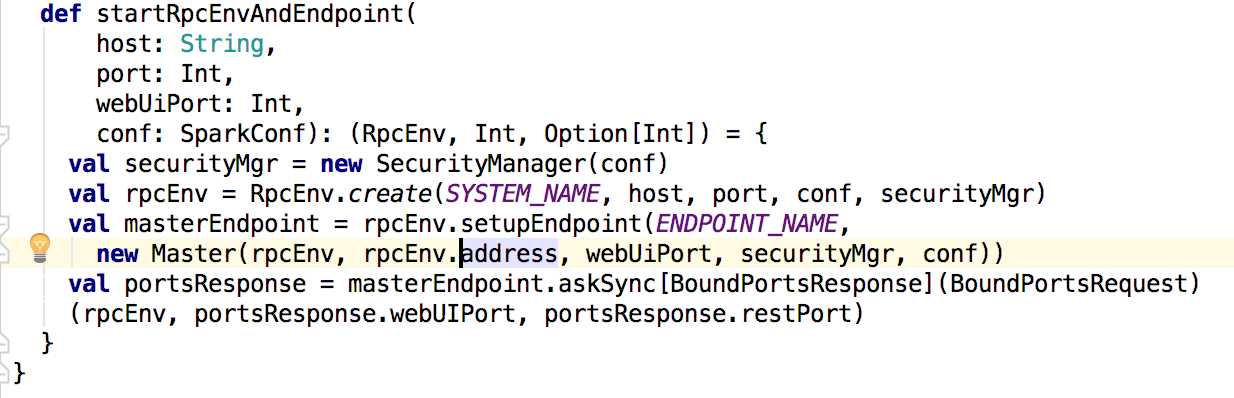
在启动服务端master通信的时候,会在inbox中调用master的onStart方法(关于spark RPC可以查阅其他博客);下面就分析master的onStart方法:
1 override def onStart(): Unit = { 2 logInfo("Starting Spark master at " + masterUrl) 3 logInfo(s"Running Spark version ${org.apache.spark.SPARK_VERSION}") 4 webUi = new MasterWebUI(this, webUiPort) 5 webUi.bind() 6 masterWebUiUrl = "http://" + masterPublicAddress + ":" + webUi.boundPort 7 if (reverseProxy) { 8 masterWebUiUrl = conf.get("spark.ui.reverseProxyUrl", masterWebUiUrl) 9 webUi.addProxy() 10 logInfo(s"Spark Master is acting as a reverse proxy. Master, Workers and " + 11 s"Applications UIs are available at $masterWebUiUrl") 12 } 13 checkForWorkerTimeOutTask = forwardMessageThread.scheduleAtFixedRate(new Runnable { 14 override def run(): Unit = Utils.tryLogNonFatalError { 15 self.send(CheckForWorkerTimeOut) 16 } 17 }, 0, WORKER_TIMEOUT_MS, TimeUnit.MILLISECONDS) 18 19 if (restServerEnabled) { 20 val port = conf.getInt("spark.master.rest.port", 6066) 21 restServer = Some(new StandaloneRestServer(address.host, port, conf, self, masterUrl)) 22 } 23 restServerBoundPort = restServer.map(_.start()) 24 25 masterMetricsSystem.registerSource(masterSource) 26 masterMetricsSystem.start() 27 applicationMetricsSystem.start() 28 // Attach the master and app metrics servlet handler to the web ui after the metrics systems are 29 // started. 30 masterMetricsSystem.getServletHandlers.foreach(webUi.attachHandler) 31 applicationMetricsSystem.getServletHandlers.foreach(webUi.attachHandler) 32 33 val serializer = new JavaSerializer(conf) 34 val (persistenceEngine_, leaderElectionAgent_) = RECOVERY_MODE match { 35 case "ZOOKEEPER" => 36 logInfo("Persisting recovery state to ZooKeeper") 37 val zkFactory = 38 new ZooKeeperRecoveryModeFactory(conf, serializer) 39 (zkFactory.createPersistenceEngine(), zkFactory.createLeaderElectionAgent(this)) 40 case "FILESYSTEM" => 41 val fsFactory = 42 new FileSystemRecoveryModeFactory(conf, serializer) 43 (fsFactory.createPersistenceEngine(), fsFactory.createLeaderElectionAgent(this)) 44 case "CUSTOM" => 45 val clazz = Utils.classForName(conf.get("spark.deploy.recoveryMode.factory")) 46 val factory = clazz.getConstructor(classOf[SparkConf], classOf[Serializer]) 47 .newInstance(conf, serializer) 48 .asInstanceOf[StandaloneRecoveryModeFactory] 49 (factory.createPersistenceEngine(), factory.createLeaderElectionAgent(this)) 50 case _ => 51 (new BlackHolePersistenceEngine(), new MonarchyLeaderAgent(this)) 52 } 53 persistenceEngine = persistenceEngine_ 54 leaderElectionAgent = leaderElectionAgent_ 55 }
在这个方法里面首先针对webui进行了一系列的处理,然后启动一个线程来检查任何超时的worker,并且清除它;其次处理了一些关于Metrics的内容和在多个master下面的的关于元数据和master选举的一些机制;
根据spark.deploy.recoveryMode设置的参数,可以是ZOOKEEPER,FILESYSTEM,CUSTOM,默认为NONE,当是zookeeper时,基于ZooKeeper选举,元数据信息会持久化到ZooKeeper中。当是fileSystem时集群的元数据会保存到本地的文件系统中,而master启动会立即成为集群的master。当是custom时,是用户自定义,需要实现StandaloneRecoveryModeFactory,并将类的名字配置到spark.deploy.recoveryMode.factory;当是NONE的时候不会持久化元数据信息,master启动会即是集群的master。
接下来看看worker中的处理,在worker的mian方法中调用的是startRpcEnvAndEndpoint()方法
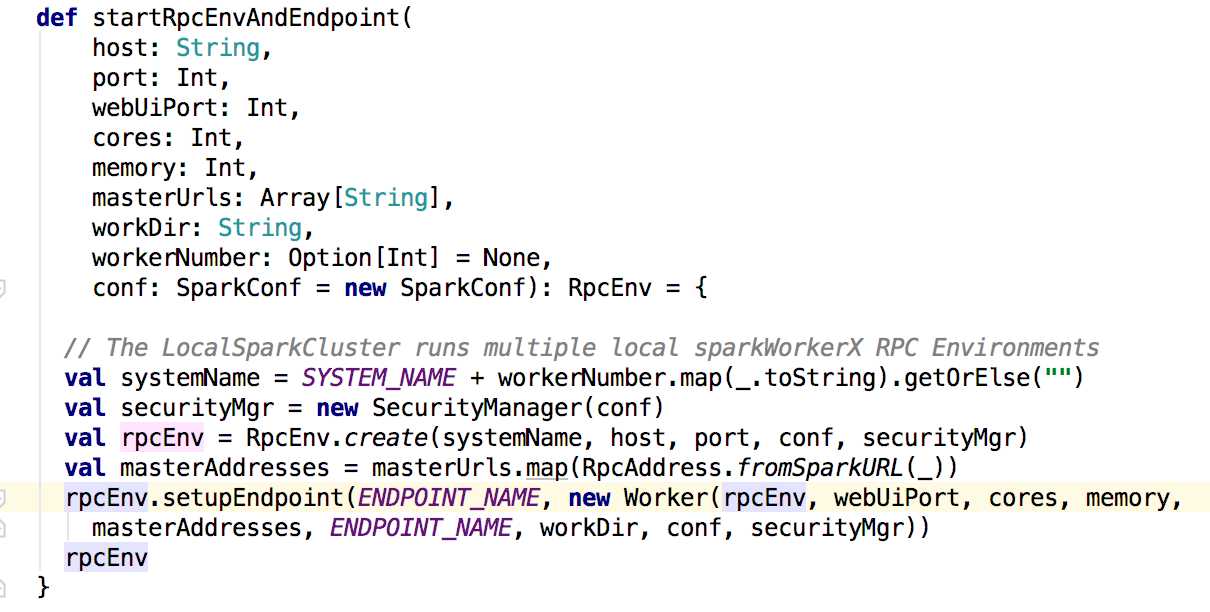
上面的方法也是注册启动了worker的消息通信,同理也会调用worker的onStart方法。在onstart方法里面会调用registerWithMaster()方法来注册到master上。
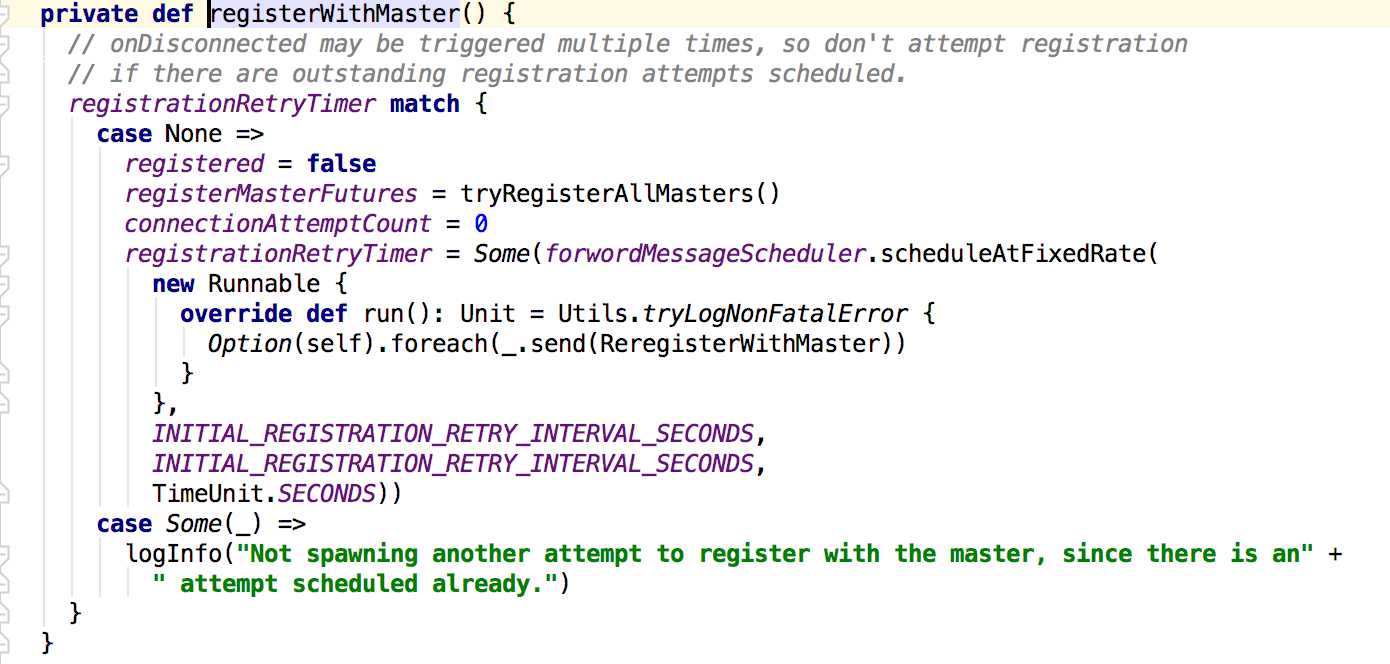
在这个方法里面会调用tryRegisterAllMasters来注册到master,在其后面是关于重试的处理,主要是判断registered的值来进行相应的处理。接下来是tryRegisterAllMasters方法:
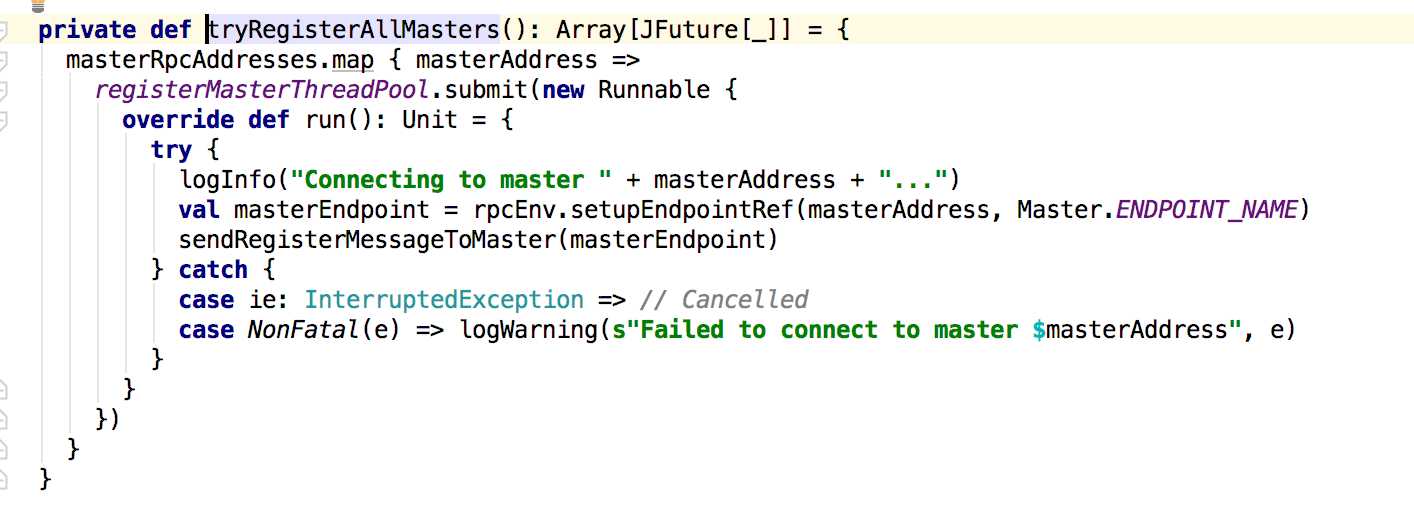
这里会创建一个注册master的线程池来管理,发送的消息在sendRegisterMessageToMaster方法中,就是发送一个RegisterWorker的消息给master;接下俩看master对这个消息的处理:
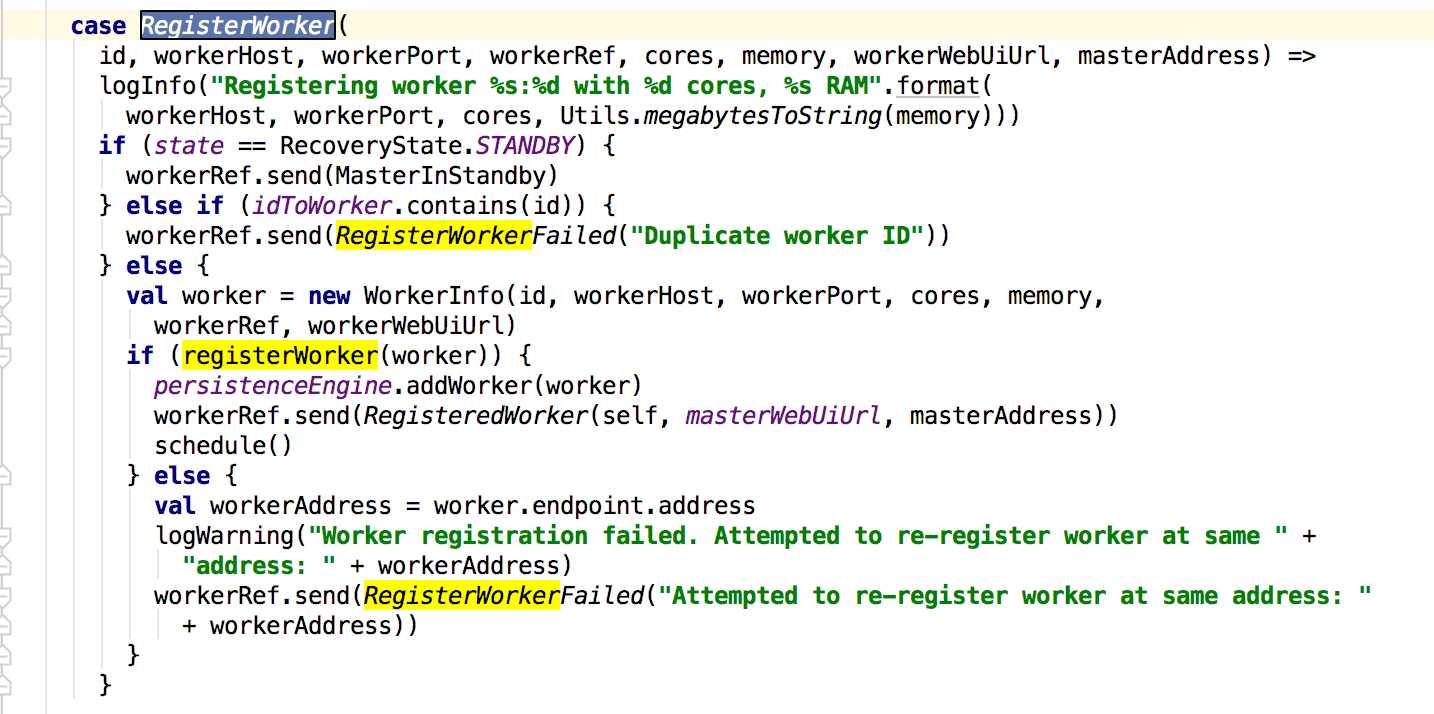
master在接收到这个消息的时候会先判断state状态以及现有注册的worker是否存在新的注册的worker的id,若状态和id没有匹配到则新建一个workerInfo来保存worker的信息,最后调用registerWorker方法添加worker,早真正添加完成之后,会给worker发送RegisteredWorker消息,其后会调用schedule方法;下面先看worker接收到消息的处理:
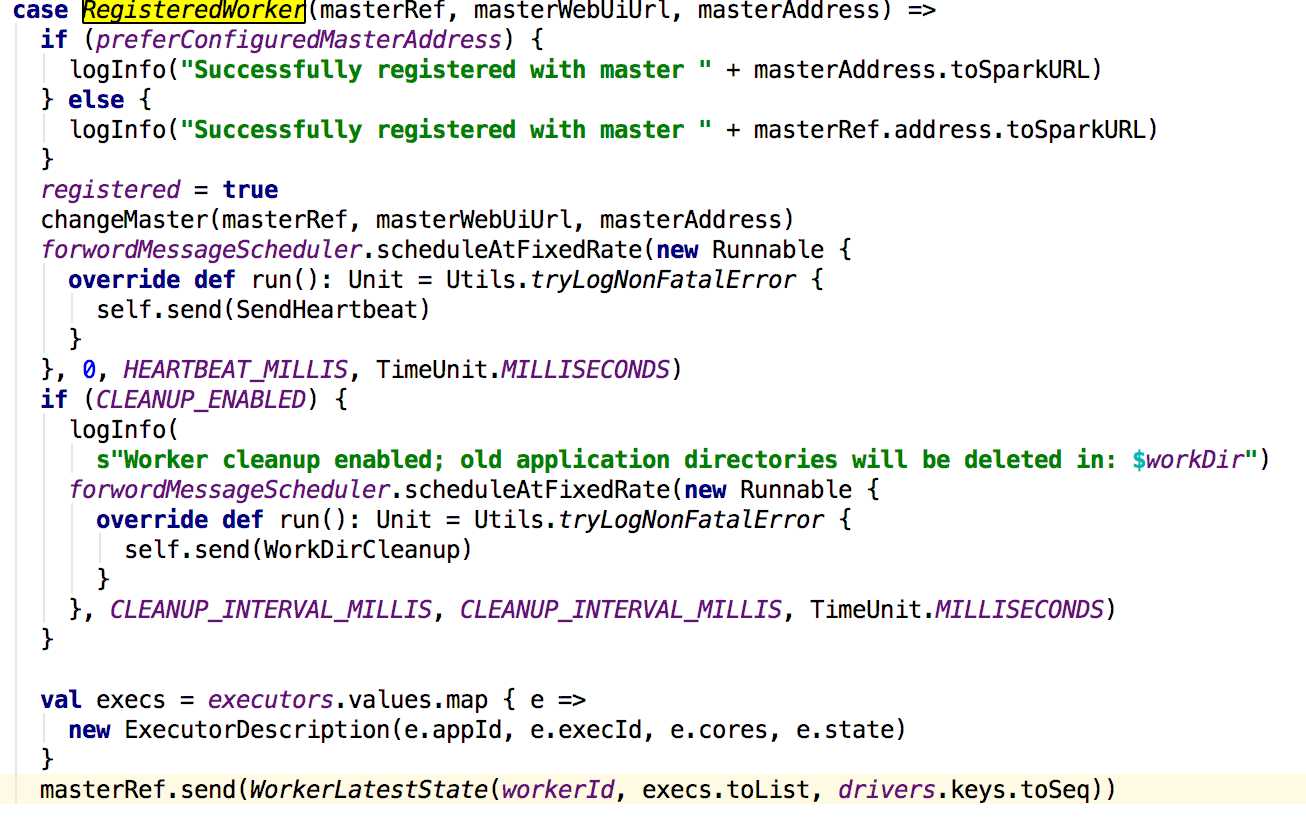
worker在接收到来master的消息之后,先更新registered的值,然后更新master的信息,启动一个线程定时给master发送心跳信息,如果配置了spark.worker.cleanup.enabled为true,则进行清理工作,最后会向master发送worker的exector的信息。
到这个时候master和worker已经完全启动,接下来就是启动worker中的exectors。这个改天再说!
标签:sch spark集群 thread rate message 本地 ror register for
原文地址:https://www.cnblogs.com/ldsggv/p/9489541.html