标签:在线 charm anaconda 9.png alt 回车 网页 域名 spi
一.安装
conda install Scrapy :之后在按y 表示允许安装相关的依赖库(下载速度慢的话也可以借助镜像源),安装的前提是安装了anaconda作为python , 测试scrapy是否安装成功,在窗口输入scrapy回车
注意:我这是之前安装了anaconda 所以能直接这样下载 如果没有则需要自己一个一个下载依赖库 和scrapy 但是可以借助豆瓣的镜像源来快速安装
格式: pip install -i https://pypi.douban.com/simaple/ scrapy

二.创建scrapy项目的过程:
1.首先进入到你所要创建项目文件的路径下。cd ……
2.scrapy startproject 项目(文件)名 ------这就是创建一个scrapy项目文件了

3.cd (我们刚刚刚创建的)项目(文件)名。
4.scrapy genspider spider的一个名称(一个.py的爬虫文件) spider的域名(爬取的网页的网址)

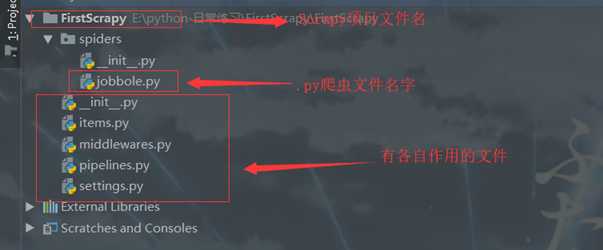
5上面我们创建了一个scrapy文件 并且在spider(scrapy项目文件下)下创建一个.py文件 ,名字是jobbole 地址blog.jobbole.com (伯乐在线的)
我通过pycharme打开scrapy文件,如图:
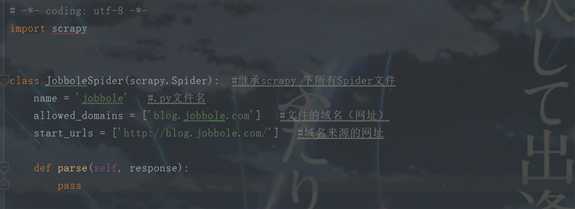
三.好了,这样我就可以在创建的.py的jobbole的爬虫文件下写代码了。
标签:在线 charm anaconda 9.png alt 回车 网页 域名 spi
原文地址:https://www.cnblogs.com/hum0ro/p/9490673.html
{kind=link}