标签:log php lines for out 新闻 blank ima open
数据集来源:http://www.sogou.com/labs/resource/cs.php

目的:得到title集合文本,content集合文本
代码:
#python2 import chardet with open("news_sohusite_xml.dat",‘r‘) as h: x=h.readlines() # print(x[3]) topics=x[3::6] print(len(topics)) contents=x[4::6] type = chardet.detect(x[3]) print(type) # a = topics[0].decode(type["encoding"]) for i in topics: with open("sohusite_topics.txt","a") as f_out: f_out.write(i[14:-16].decode("gb18030").encode("utf-8")+‘\n‘) # f_out.write(i[14:-16].decode(type["encoding"]).encode("utf-8")+‘\n‘) for i in contents: with open("sohusite_contents.txt","a") as f_outt: f_outt.write(i[9:-11].decode("gb18030").encode("utf-8")+‘\n‘)
解码编码上花了点时间:原本用chardet.detect可以得到文本编码是gb2312,但是decode的时候会报错:
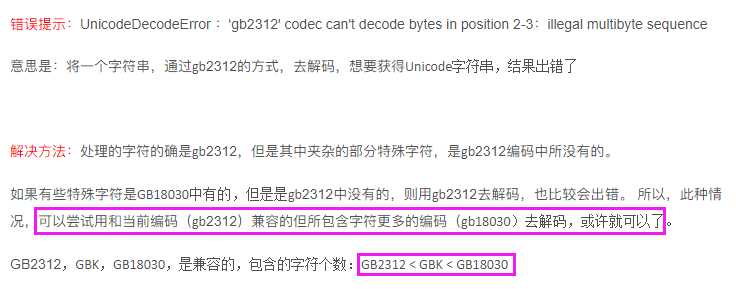
标签:log php lines for out 新闻 blank ima open
原文地址:https://www.cnblogs.com/helloworld0604/p/9492682.html