标签:意义 html 曲线 position ram 获得 cep int 情况
https://blog.csdn.net/shijing_0214/article/details/53143393
孔子说过,温故而知新,时隔俩月再重看CNNs,当时不太了解的地方,又有了新的理解与体会,特此记录下来。文章图片及部分素材均来自网络,侵权请告知。
卷积神经网络(Convolutinal Neural Networks)是非常强大的一种深度神经网络,它在图片的识别分类、NLP句子分类等方面已经获得了巨大的成功,也被广泛使用于工业界,例如谷歌将它用于图片搜索、亚马逊将它用于商品推荐等。
首先给出几个CNNs应用的两个例子如下:
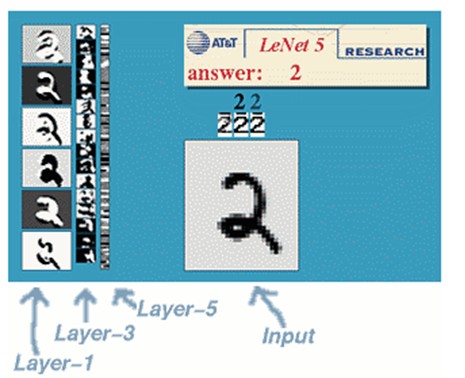 (1)、手写体数字识别
(1)、手写体数字识别 (2)、对象识别
(2)、对象识别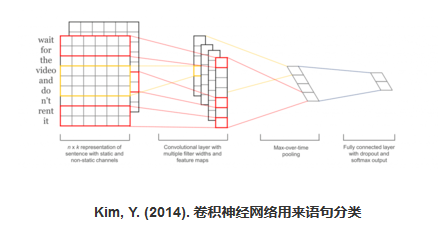
可以看到CNNs可以被用来做许多图像与NLP的事情,且效果都很不错。那么CNNs的工作框架是什么样子呢?
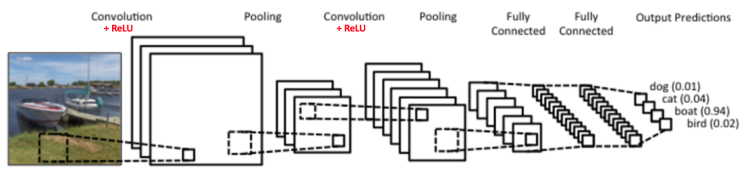
由上可以看到,CNNs的输入层为原始图片,当然,在计算机中图片就是用构成像素点的多维矩阵来表示了。然后中间层包括若干层的卷积+ReLU+池化,和若干层的全连接层,这一部分是CNNs的核心,是用来对特征进行学习和组合的,最终会学到一些强特征,具体是如何学习到的会在下面给出。最后会利用中间层学到的强特征做为输入通过softmax函数来得到输出标记。
下面就针对上面给出的CNNs框架一层层进行解析。
输入层没有什么可讲的,就是将图片解析成由像素值表示的多维矩阵即可,如下:
通道为1也就是厚度为1的图称为灰度图,也即上图。若是由RGB表示的图片则是一个三维矩阵表示的形式,其中第三维长度为3,包含了RGB每个通道下的信息。
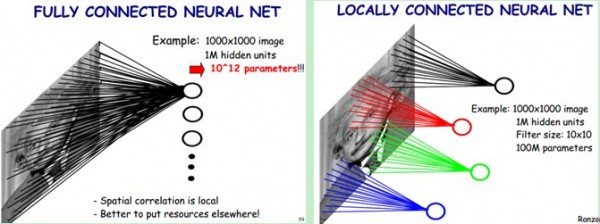
CNNs隐层与ANN相比,不仅增加了隐层的层数,而且在结构上增加了convolution卷积、ReLU线性修正单元和pooling池化的操作。其中,卷积的作用是用来过滤特征,ReLu作为CNNs中的激活函数,作用稍后再说,pooling的作用是用来降低维度并提高模型的容错性,如保证原图片的轻微扭曲旋转并不会对模型产生影响。 由于CNNs与ANN相比,模型中包含的参数多了很多,若是直接使用基于全连接的神经网络来处理,会因为参数太多而根本无法训练出来。那有没有一些方法降低模型的参数数目呢?答案就是局部感知野和权值共享,中间层的操作也就是利用这些trick来实现降低参数数目的目的。
首先解释一下什么是局部感知野
举个例子来讲就是,一个32
通过局部感知的特性,可以大大减少神经元间的连接数目,也就大大减少了模型参数。
但是这样还不行,参数还是会有很多,那么就有了第二个trick,权值共享。那么什么是权值共享呢?在上面提到的局部感知中图中,假设有1m的隐层神经元,每个神经元对应了10
为什么是一样的呢?其实,同一层下的神经元的连接参数只与特征提取的方式有关,而与具体的位置无关,因此可以保证同一层中对所有位置的连接是权值共享的。举个例子来讲,第一层隐层是一般用来做边缘和曲线检测,第二层是对第一层学到的边缘曲线组合得到的一些特征,如角度、矩形等,第三层则会学到更复杂的一些特征,如手掌、眼睛等。对于同一层来讲,它们提取特征的方式一样,所以权值也应该一样。
通过上面讲到的局部感知野和权值共享的trick,CNNs中的参数会大幅减少,从而使模型训练成为可能。
在讲局部感知野时提到了卷积操作,卷积操作,说白了就是矩阵的对位位置的相乘相加操作,如下:
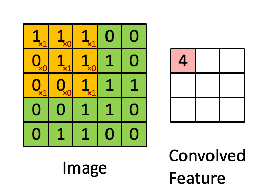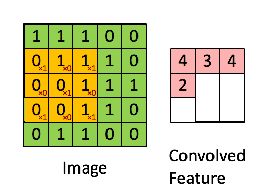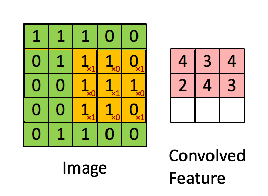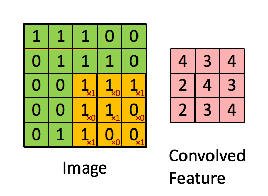
绿色为原始输入,黄色为卷积核,也称为过滤器,右侧为经过卷积操作生成的特征图。值得一提的是,卷积核的通道长度需要与输入的通道长度一致。 下面一张图很好地诠释了卷积核的作用,如图:

上图中的红色和绿色两个小方块对应两个卷积核,通过两轮卷积操作会产生两个特征图作为下一层的输入进行操作。
为什么在CNNs中激活函数选用ReLU,而不用sigmoid或tanh函数?这里给出网上的一个回答
第一个问题:为什么引入非线性激励函数? 如果不用激励函数(其实相当于激励函数是f(x) = x),在这种情况下你每一层输出都是上层输入的线性函数,很容易验证,无论你神经网络有多少层,输出都是输入的线性组合,与没有隐藏层效果相当,这种情况就是最原始的感知机(Perceptron)了。 正因为上面的原因,我们决定引入非线性函数作为激励函数,这样深层神经网络就有意义了(不再是输入的线性组合,可以逼近任意函数)。最早的想法是sigmoid函数或者tanh函数,输出有界,很容易充当下一层输入(以及一些人的生物解释balabala)。
第二个问题:为什么引入ReLU呢? 第一,采用sigmoid等函数,算激活函数时(指数运算),计算量大,反向传播求误差梯度时,求导涉及除法,计算量相对大,而采用ReLU激活函数,整个过程的计算量节省很多。 第二,对于深层网络,sigmoid函数反向传播时,很容易就会出现梯度消失的情况(在sigmoid接近饱和区时,变换太缓慢,导数趋于0,这种情况会造成信息丢失,参见 @Haofeng Li 答案的第三点),从而无法完成深层网络的训练。 第三,ReLU会使一部分神经元的输出为0,这样就造成了网络的稀疏性,并且减少了参数的相互依存关系,缓解了过拟合问题的发生(以及一些人的生物解释balabala)。
接下来讲一下pooling过程。 池化pooling,也称为欠采样(subsampling)或下采样(downsampling),主要用于降低特征的维度,同时提高模型容错性,主要有max,average和sum等不同类型的操作。如下图对特征图进行最大池化的操作:
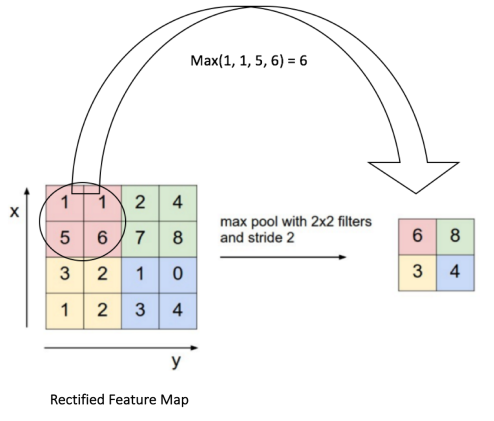
通过池化操作,使原本4
经过若干次的卷积+线性修正+pooling后,模型会将学到的高水平的特征接到一个全连接层。这个时候你就可以把它理解为一个简单的多分类的神经网络,通过softmax函数得到输出,一个完整的过程如下图:

参考【1】中给了一个CNNs做手写体数字识别的2D可视化展示,可以看到每一层做了什么工作,很有意思,大家可以看看。
【1】、An Intuitive Explanation of Convolutional Neural Networks 【2】、技术向:一文读懂卷积神经网络CNN 【3】、知乎Begin Again关于ReLU作用的回答
标签:意义 html 曲线 position ram 获得 cep int 情况
原文地址:https://www.cnblogs.com/DicksonJYL/p/9493126.html
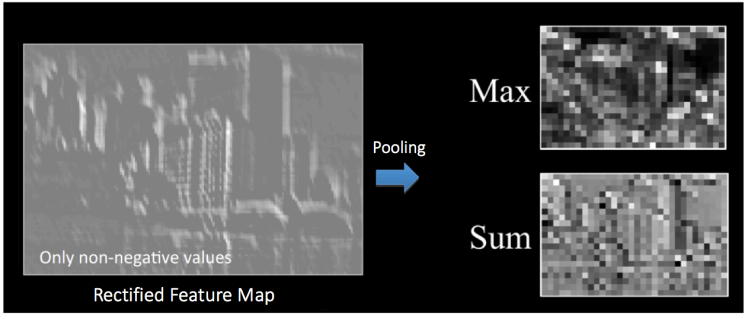 是不是人眼不太容易分辨出来特征了?没关系,机器还是可以的。
是不是人眼不太容易分辨出来特征了?没关系,机器还是可以的。