标签:ctc col 图片 value 主机名 out 文件中 replica ati
一.修改配置文件(hadoop目录/etc/hadoop/配置文件)
1.修改hadoop-env.sh,指定JAVA_HOME

修改完毕后

2.修改core-site.xml
1 <configuration>
2 <!-- 指定hdfs namenode的缺省路径,可以是ip,也可以是主机名 -->
3 <property>
4 <name>fs.tmp.dir</name>
5 <value>/hadoop/tmp</value>
6 </property>
7
8 <!-- 指定hadoop运行时产生文件的存储目录 -->
9 <property>
10 <name>fs.defaultFS</name>
11 <value>hdfs://hadoop002:9000</value>
12 </property>
13 </configuration>
3.修改hdfs-site.xml
1 <configuration>
2 <!-- 指定HDFS副本的数量 -->
3 <property>
4 <name>dfs.replication</name>
5 <value>1</value>
6 </property>
7 <!--配置namenode的web界面-->
8 <property>
9 <name>dfs.namenode.http-address</name>
10 <value>hadoop002:50070</value>
11 </property>
12 </configuration>
到这启动hadoop的基本配置已经完成了(配置完这些已经可以启动hadoop了),下面配置yarn相关的文件
4.修改mapred-site.xml
1 <configuration>
2 <!-- 使用yarn框架 -->
3 <property>
4 <name>mapreduce.framework.name</name>
5 <value>yarn</value>
6 </property>
7 </configuration>
5.修改yarn-site,xml(此配置文件中尽量不要使用中文注释,否则启动的时候会有一个java.lang.RuntimeException: com.ctc.wstx.exc.WstxIOException: Invalid UTF-8 start byte 0xb5 (at char #672, byte #20))
1 <configuration>
2 <!-- Site specific YARN configuration properties -->
3 <!--resourcemanager address-->
4 <property>
5 <name>yarn.resourcemanager.hostname</name>
6 <value>localhost</value>
7 </property>
8
9 <!--reduce-->
10 <property>
11 <name>yarn.nodemanager.aux-services</name>
12 <value>mapreduce_shuffle</value>
13 </property>
14 </configuration>
6.启动
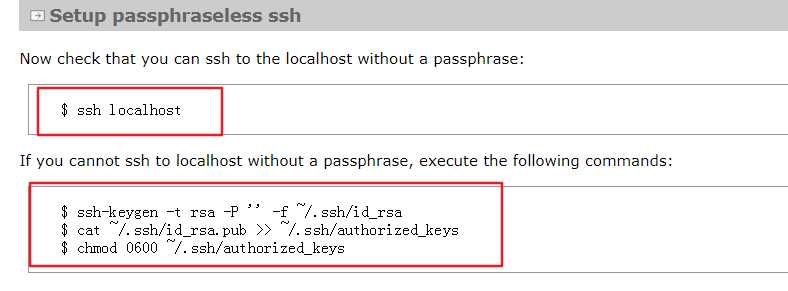
6.1按照官方文档,第一步先检查ssh能否免密登录如果不能免密登录需要执行以下命令
ssh-keygen -t rsa -P ‘‘ -f ~/.ssh/id_rsa cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys chmod 0600 ~/.ssh/authorized_keys
如果不能免密且没有执行这三个命令,那么启动时会有Permission Dennied
如果出现ssh connect to host xxx port 22:Connection timed out,ifconfig查看自己的ip与 /etc/hosts下的映射中的ip是否一致
6.2执行hdfs namenode -format格式化namenode,第一次启动时执行即可,今后不再需要
6.3执行start-dfs.sh(必须)
6.4执行start-yarn.sh(可选)
6.5jps查看进程
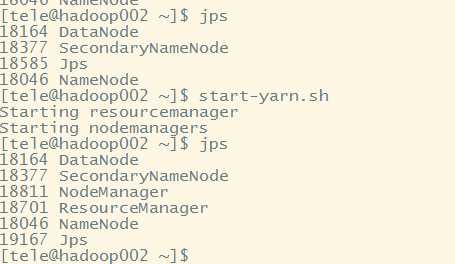
6.6停止的话使用对应的stop-xxx.sh即可
到这hadoop已经成功启动了
hadoop 3.1.1 单机集群配置/启动问题时的问题处理
标签:ctc col 图片 value 主机名 out 文件中 replica ati
原文地址:https://www.cnblogs.com/tele-share/p/9495578.html