标签:sel == regress 数值 eps 存在 block 决策 count
大神经验:
1、应用机器学习,千万不要一上来就试图做到完美,先撸一个baseline的model出来,再进行后续的分析步骤,一步步提高,所谓后续步骤可能包括『分析model现在的状态(欠/过拟合),分析我们使用的feature的作用大小,进行feature selection,以及我们模型下的bad case和产生的原因』等等。
2、
对数据的认识太重要了!
数据中的特殊点/离群点的分析和处理太重要了!
特征工程(feature engineering)太重要了!在很多Kaggle的场景下,甚至比model本身还要重要!
要做模型融合(model ensemble)!
3、
问题或问题的定义。
获取训练和测试数据。
Wrangle,准备,清理数据。
分析,识别模式并探索数据。
建模,预测和解决问题。
可视化,报告和呈现问题解决步骤和最终解决方案。
提供或提交结果。
工作流程
分类。我们可能希望对样本进行分类。我们可能还想了解不同类的含义或相关性与我们的解决方案目标。
相关。可以基于训练数据集中的可用特征来解决问题。数据集中的哪些功能对我们的解决方案目标有重大贡献?从统计上讲,功能和解决方案目标之间是否存在相关性?随着特征值的变化,解决方案状态也会发生变化,反之亦然?这可以针对给定数据集中的数字和分类特征进行测试。我们可能还希望确定除后续目标和工作流程阶段的生存之外的特征之间的相关性。关联某些功能可能有助于创建,完成或更正功能。
转换。对于建模阶段,需要准备数据。根据模型算法的选择,可能需要将所有特征转换为数值等效值。例如,将文本分类值转换为数值。
填补。数据准备可能还需要我们估计要素中的任何缺失值。当没有缺失值时,模型算法可能最有效。
纠正。我们还可以分析给定的训练数据集中的错误或可能在特征内删除值,并尝试纠正这些值或排除包含错误的样本。一种方法是检测我们的样本或特征中的任何异常值。如果某项功能无法进行分析,或者可能会严重影响结果,我们也可能会完全丢弃该功能。
创建。我们是否可以基于现有功能或一组功能创建新功能,以便新功能遵循关联,转换和完整性目标。
图表。如何根据数据的性质和解决方案目标选择正确的可视化图表和图表。
正式开始
介绍
数据集包含两部分
具体内容
| Variable | Definition | Key |
|---|---|---|
| survival | Survival | 0 = No, 1 = Yes |
| pclass | Ticket class | 1 = 1st, 2 = 2nd, 3 = 3rd |
| sex | Sex | |
| Age | Age in years | |
| sibsp | # of siblings / spouses aboard the Titanic | |
| parch | # of parents / children aboard the Titanic | |
| ticket | Ticket number | |
| fare | Passenger fare | |
| cabin | Cabin number | |
| embarked | Port of Embarkation | C = Cherbourg, Q = Queenstown, S = Southampton |
变量解释
pclass: A proxy for socio-economic status (SES) 社会地位
1st = Upper
2nd = Middle
3rd = Lower
age: Age is fractional if less than 1. If the age is estimated, is it in the form of xx.5
sibsp: The dataset defines family relations in this way...
Sibling = brother, sister, stepbrother, stepsister 兄弟姐妹,横向
Spouse = husband, wife (mistresses and fiancés were ignored) 配偶
parch: The dataset defines family relations in this way...
Parent = mother, father 父母
Child = daughter, son, stepdaughter, stepson 儿女
Some children travelled only with a nanny, therefore parch=0 for them.
# data analysis and wrangling import pandas as pd import numpy as np import random as rnd # visualization import seaborn as sns import matplotlib.pyplot as plt %matplotlib inline # machine learning from sklearn.linear_model import LogisticRegression from sklearn.svm import SVC, LinearSVC from sklearn.ensemble import RandomForestClassifier from sklearn.neighbors import KNeighborsClassifier from sklearn.naive_bayes import GaussianNB from sklearn.linear_model import Perceptron from sklearn.linear_model import SGDClassifier from sklearn.tree import DecisionTreeClassifier
导入数据,把训练集和测试集合并来一起实施操作
train_df = pd.read_csv(‘../input/train.csv‘) test_df = pd.read_csv(‘../input/test.csv‘) combine = [train_df, test_df]
对数据进行分析,先看看有哪些特征列
print(train_df.columns.values)
out:
[‘PassengerId‘ ‘Survived‘ ‘Pclass‘ ‘Name‘ ‘Sex‘ ‘Age‘ ‘SibSp‘ ‘Parch‘
‘Ticket‘ ‘Fare‘ ‘Cabin‘ ‘Embarked‘]
哪些特征是 categorical,哪些是numerical的?
- 分类: Survived, Sex, and Embarked. 序列: Pclass.
- 连续: Age, Fare. 分离: SibSp, Parch.
整体观看数据
# preview the data train_df.head()

哪些特征是混合数据类型的?
船票是数字和字母数字数据类型的混合。 船舱是字母和数字混合。
哪些特征是包含错误值或错别字的?
名称功能可能包含错误或拼写错误,因为有多种方法可用于描述名称,包括标题,圆括号和用于替代或短名称的引号。
哪些特征包含blank, null or empty values?
- Cabin> Age> Embarked 按训练数据集的顺序包含许多空值。
- Cabin > Age 在测试集上是不完整的
各个特征的数据类型是什么?
如训练集上2个float,5个int,5个object
train_df.info() print(‘_‘*40) test_df.info()
out:
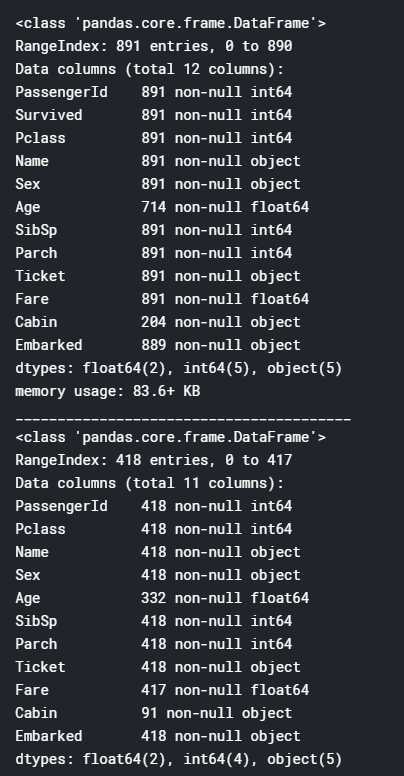
样本的特征(数字类)的分布如何?分析一下:
这有助于我们了解早期的数据概貌。
- 实际乘客人数(891)是总样本泰坦尼克号(2,224)上的40%。
- Survived是一个具有0或1值的分类特征。
- 约38%的样本存活,代表实际存活率为32%。
- 大多数乘客(> 75%)没有与父母或孩子一起旅行。
- 近30%的乘客有兄弟姐妹和/或配偶。
- 票价差异很大,很少有乘客(<1%)支付高达512美元。
- 年龄在65-80岁之间的老年乘客(<1%)很少。
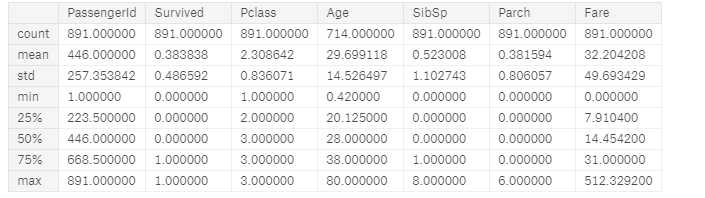
train_df.describe() # Review survived rate using `percentiles=[.61, .62]` knowing our problem description mentions 38% survival rate. # Review Parch distribution using `percentiles=[.75, .8]` # SibSp distribution `[.68, .69]` # Age and Fare `[.1, .2, .3, .4, .5, .6, .7, .8, .9, .99]`
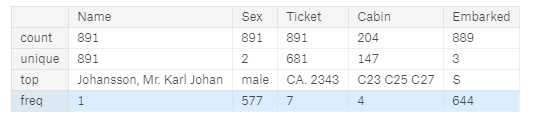
分析完数据型的特征,那分类型的特征的分布又是怎样的?
- Names 在整个数据集中是唯一的(count = unique = 891)
- Sex 变量为两个可能的值,男性为65%(top=男性,fre= 577 /计数= 891)。
- Cabin 的值在样本中有几个副本。 因为有几名乘客共用一间cabin。
- Embarked 采取三个可能的值。 大多数乘客前往S港口(top= S)
- Ticket 特征具有高比率(22%)的重复值(unique= 681)。
train_df.describe(include=[‘O‘]) #参数O代表只列出object类型的列
out:
综上分析一波:
基于数据分析的假设
我们基于迄今为止所做的数据分析得出以下假设。我们可能会在采取适当行动之前进一步验证这些假设。
相关:
我们想知道每个特征与生存的相关性。我们希望在项目的早期阶段完成这项工作,并将这些快速关联与项目后期的建模关联相匹配。
填补:
1.我们可能希望填补Age特征,因为它与生存明确相关。
2.我们可能希望填补Embarked特征,因为它也可能与生存或其他重要功能相关。
修正:
1. Ticket 特征可能会从我们的分析中删除,因为它包含高比例的重复项(22%),并且Ticket和生存之间可能没有相关性。
2. Cabin 特征可能会因为高度不完整而丢弃,因为在训练和测试数据集中包含许多空值。
3. PassengerId 可能会从训练数据集中删除,因为它对生存没有贡献。
4. Names 特征相对不标准,可能无法直接促成生存,因此可能会丢掉。
创建:
1.我们可能想要创建一个名为Family的基于Parch和SibSp的新特征,以获得船上家庭成员的总数。
2.我们可能想要创建Name 特征来将Title 提取为新特征。
3.我们可能想为Age列创建新特征。这将连续的数字特征转换为序数分类特征。
4.如果有助于我们的分析,我们可能还想创建一个Fare 范围特征。
分类
我们还可以根据前面提到的问题描述添加我们的假设。
1.女性更有可能幸存下来。
2.儿童(Age<?)更有可能存活下来。
3.上层乘客(Pclass = 1)更有可能幸存下来。
通过pivoting进行分析
为了确认我们的一些观察和假设,我们可以通过相互pivote特征来快速分析我们的特征相关性。 我们只能在此阶段对没有任何空值的特征执行此操作。 对于分类(Sex),序数(Pclass)或离散(SibSp,Parch)类型的特征,这样做也是有意义的。
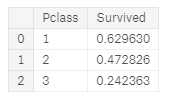
- Pclass 我们观察到 Pclass = 1 和 Survived(分类#3)之间存在显着的相关性(> 0.5)。 我们决定在我们的模型中包含此功能。
- Sex 我们在问题定义中确认 Sex=female 的存活率非常高,为74%(分类#1)。
- SibSp和Parch 这些特征对于某些值具有零相关性。 最好从这些单独的特征中导出一个特征或一组特征(创建#1)。
//as_index参数为false时输出表格为SQL的风格
train_df[[‘Pclass‘, ‘Survived‘]].groupby([‘Pclass‘], as_index=False).mean().sort_values(by=‘Survived‘, ascending=False)
out:
train_df[["Sex", "Survived"]].groupby([‘Sex‘], as_index=False).mean().sort_values(by=‘Survived‘, ascending=False)
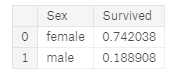
train_df[["SibSp", "Survived"]].groupby([‘SibSp‘], as_index=False).mean().sort_values(by=‘Survived‘, ascending=False)
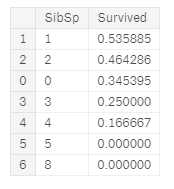
train_df[["Parch", "Survived"]].groupby([‘Parch‘], as_index=False).mean().sort_values(by=‘Survived‘, ascending=False)
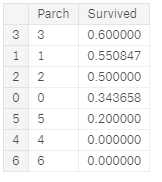
到现在为止,进行可视化数据来直观分析
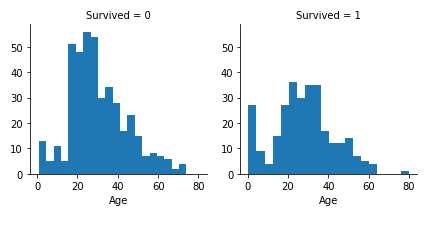
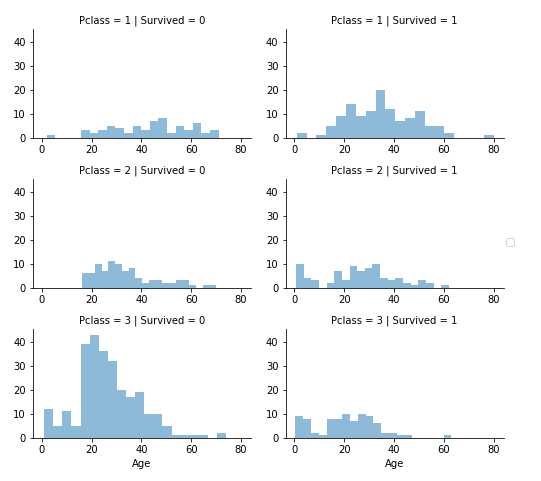
g = sns.FacetGrid(train_df, col=‘Survived‘) g.map(plt.hist, ‘Age‘, bins=20)
关联数字和序数特征
我们可以使用单个图组合多个功能来识别相关性。 这可以通过具有数值的数字和分类特征来完成。
观察
- Pclass = 3有大多数乘客,但大部分都无法生存。 证实我们的分类假设#2。
- Pclass = 2和 Pclass = 3 的婴儿乘客大部分幸存下来。 进一步证实了我们的分类假设#2。
- Pclass = 1的大多数乘客幸免于难。 证实我们的分类假设#3。
- Pclass在乘客年龄分布方面有所不同。
决定
- 考虑使用Pclass进行模型训练。
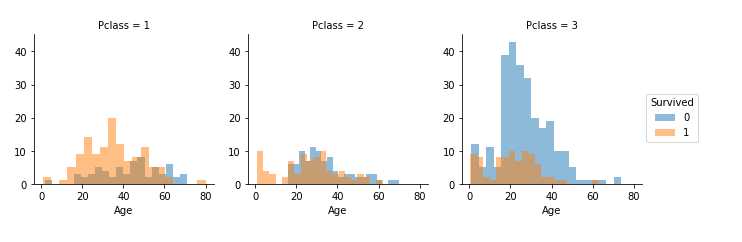
#grid = sns.FacetGrid(train_df, col=‘Pclass‘, hue=‘Survived‘) grid = sns.FacetGrid(train_df, col=‘Survived‘, row=‘Pclass‘, size=2.2, aspect=1.6) grid.map(plt.hist, ‘Age‘, alpha=.5, bins=20) grid.add_legend();
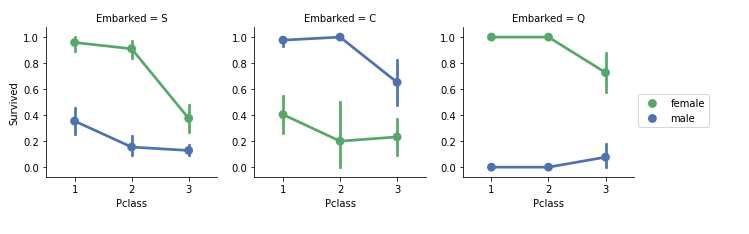
关联分类功能
现在我们可以将分类特征与我们的解决方案目标相关联。
观察
- 女性乘客的生存率远高于男性。 证实分类(#1)。
- 在 Embarked = C 中的例外情况,其中男性的存活率更高。 这可能是 Pclass 和 Embarked 之间的相关性,反过来是 Pclass 和 Survived,不一定是 Embarked 和 Survived 之间的直接相关。
- 对 C 和 Q港口,男性在 Pclass = 3相比在Pclass = 2时的存活率更高。 证实填补(#2)。
- 对于Pclass = 3的男性,不同的登船港口他们的生存率各不相同。 证实相关(#1)。
决定
- 为模型训练添加 Sex 特征。
- 填补并添加 Embarked 特征来进行模型训练。
grid = sns.FacetGrid(train_df, col=‘Embarked‘) #grid = sns.FacetGrid(train_df, row=‘Embarked‘, size=2.2, aspect=1.6) grid.map(sns.pointplot, ‘Pclass‘, ‘Survived‘, ‘Sex‘, palette=‘deep‘) grid.add_legend()
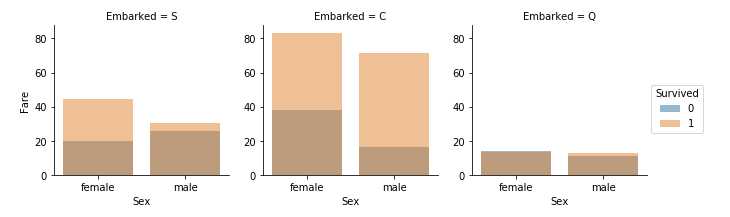
关联分类和数字特征
我们可能还想关联分类特征(使用非数字值)和数字特征。 我们可以考虑将Embarked(分类非数字),Sex(分类非数字),Ticket(数字连续)与 Survivied(分类数字)相关联。
观察
- 高票价乘客的生存率更高。 证实我们创建(#4)Fare 范围的假设。
- 登船港与生存率相关。 证实相关(#1)和填补(#2)。
决定
- 考虑绑定票价功能。
grid = sns.FacetGrid(train_df, col=‘Embarked‘, hue=‘Survived‘) #grid = sns.FacetGrid(train_df, row=‘Embarked‘, col=‘Survived‘, size=2.2, aspect=1.6) grid.map(sns.barplot, ‘Sex‘, ‘Fare‘, alpha=.5, ci=None) grid.add_legend()
Wrangle数据
我们收集了有关数据集和解决方案要求的若干假设和决策。 到目前为止,我们没有必要更改单个功能或值来实现这些功能。 现在让我们执行我们的决策和假设,以纠正,创建和填补目标。
通过删除功能进行更正
这是一个很好的起始目标。 通过删除功能,我们处理的数据点更少。 加速我们的笔记本电脑并简化分析。
根据我们的假设和决定,我们希望放弃 Cabin(纠正#2)和 Ticket(纠正#1)特征。
请注意,在适用的情况下,我们同时对训练和测试数据集执行操作以保持一致。
print("Before", train_df.shape, test_df.shape, combine[0].shape, combine[1].shape) train_df = train_df.drop([‘Ticket‘, ‘Cabin‘], axis=1) test_df = test_df.drop([‘Ticket‘, ‘Cabin‘], axis=1) combine = [train_df, test_df] print("After", train_df.shape, test_df.shape, combine[0].shape, combine[1].shape)
out:
Before (891, 12) (418, 11) (891, 12) (418, 11) After (891, 10) (418, 9) (891, 10) (418, 9)
从现有特征提取的新特征
在丢弃 Name 和 PassengerId 特征之前,我们想要分析是否可以设计 Name 特征来提取 titles(称谓) 并测试 titles (称谓)和 Survived 之间的相关性,然后再删除 Name 和 PassengerId 功能。
在下面的代码中,我们使用正则表达式提取标题功能。 RegEx模式 `(\w+\.)` 匹配名称特征中以点字符结尾的第一个单词。 `expand = False` 标志返回一个DataFrame。
观察
当我们绘制 Title(称谓),Age和 Survived 时,我们注意到以下观察结果。
- 大多数titles(称谓)准确地围绕年龄组。 例如:Master 称谓的年龄均值为5年。
- Title 和 Age 列的生存率略有不同。
- 某些 titles称谓 大多存活下来(Mme,Lady,Sir)或者没有(Don,Rev,Jonkheer)。
决策
- 我们决定保留新的 Title(称谓) 特征以进行模型训练。
for dataset in combine: dataset[‘Title‘] = dataset.Name.str.extract(‘ ([A-Za-z]+)\.‘, expand=False) # 参数expand=false 标志返回一个df pd.crosstab(train_df[‘Title‘], train_df[‘Sex‘])
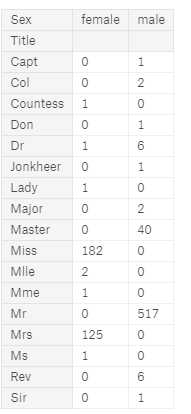
我们可以用更常见的名称替换许多称谓或将它们归类为 ‘Rare’。
for dataset in combine: dataset[‘Title‘] = dataset[‘Title‘].replace([‘Lady‘, ‘Countess‘,‘Capt‘, ‘Col‘, ‘Don‘, ‘Dr‘, ‘Major‘, ‘Rev‘, ‘Sir‘, ‘Jonkheer‘, ‘Dona‘], ‘Rare‘) dataset[‘Title‘] = dataset[‘Title‘].replace(‘Mlle‘, ‘Miss‘) dataset[‘Title‘] = dataset[‘Title‘].replace(‘Ms‘, ‘Miss‘) dataset[‘Title‘] = dataset[‘Title‘].replace(‘Mme‘, ‘Mrs‘) train_df[[‘Title‘, ‘Survived‘]].groupby([‘Title‘], as_index=False).mean()
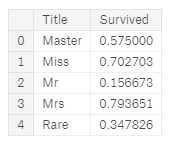
我们可以把分类的称谓转换为序列类
title_mapping = {"Mr": 1, "Miss": 2, "Mrs": 3, "Master": 4, "Rare": 5}
for dataset in combine:
dataset[‘Title‘] = dataset[‘Title‘].map(title_mapping)
dataset[‘Title‘] = dataset[‘Title‘].fillna(0)
train_df.head()

现在我们可以安全地从训练和测试数据集中删除Name 特征。 我们也不需要训练数据集中的PassengerId功能。
train_df = train_df.drop([‘Name‘, ‘PassengerId‘], axis=1) test_df = test_df.drop([‘Name‘], axis=1) combine = [train_df, test_df] train_df.shape, test_df.shape
out:
((891, 9), (418, 9))
转换分类特征
现在我们可以将包含字符串的特征转换为数值。 这是大多数模型算法所必需的。 这样做也有助于我们实现功能完成目标。
让我们首先将性别特征转换为名为Gender的新功能,其中女性= 1,男性= 0。
for dataset in combine: dataset[‘Sex‘] = dataset[‘Sex‘].map( {‘female‘: 1, ‘male‘: 0} ).astype(int) train_df.head()
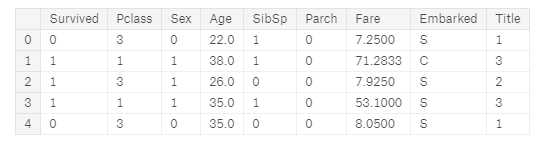
完成数字连续特征
现在我们应该开始估计和填补缺少值或空值的功能。我们将首先针对Age功能执行此操作。
我们可以考虑三种方法来填补数值连续特征。
1. 一种简单的方法是在均值和标准偏差之间生成随机数。
2. 更准确地猜测缺失值的方法是使用其他相关特征。在我们的例子中,我们注意到Age,Gender和Pclass之间的相关性。使用 中位数 的值来猜测年龄值,包括 Pclass 和 Gender 特征组合的集合。因此,年龄中位数对于 Pclass = 1且 Gender = 0,对于Pclass = 1且 Gender = 1,依此类推......
3. 结合方法1和2。因此,不是基于中位数来猜测年龄值,而是根据Pclass和Gender组合的集合使用均值和标准差之间的随机数。
方法1和3将随机噪声引入我们的模型。多次执行的结果可能会有所不同。我们更喜欢方法2。
#grid = sns.FacetGrid(train_df, col=‘Pclass‘, hue=‘Gender‘) grid = sns.FacetGrid(train_df, row=‘Pclass‘, col=‘Sex‘, size=2.2, aspect=1.6) grid.map(plt.hist, ‘Age‘, alpha=.5, bins=20) grid.add_legend()
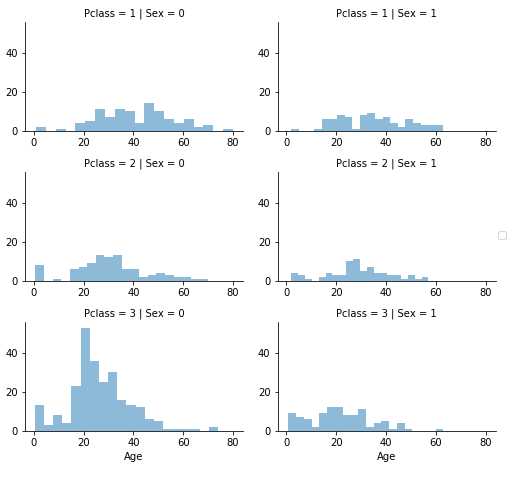
让我们首先准备一个空数组,以包含基于Pclass 和 Gender组合的Age猜测值。
然后我们迭代Sex(0或1)和Pclass(1,2,3)来计算六种组合的Age的猜测值。
guess_ages = np.zeros((2,3))
for dataset in combine: for i in range(0, 2): for j in range(0, 3): guess_df = dataset[(dataset[‘Sex‘] == i) & (dataset[‘Pclass‘] == j+1)][‘Age‘].dropna() # age_mean = guess_df.mean() # age_std = guess_df.std() # age_guess = rnd.uniform(age_mean - age_std, age_mean + age_std) age_guess = guess_df.median() # Convert random age float to nearest .5 age guess_ages[i,j] = int( age_guess/0.5 + 0.5 ) * 0.5 for i in range(0, 2): for j in range(0, 3): dataset.loc[ (dataset.Age.isnull()) & (dataset.Sex == i) & (dataset.Pclass == j+1), ‘Age‘] = guess_ages[i,j] dataset[‘Age‘] = dataset[‘Age‘].astype(int) train_df.head()
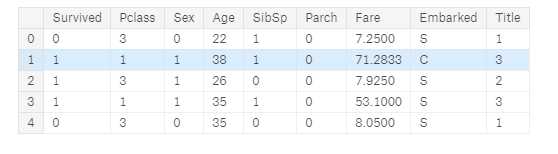
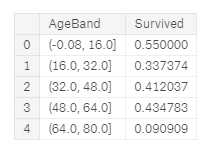
让我们创建 Age bands 并确定与 Survived 的相关性。
train_df[‘AgeBand‘] = pd.cut(train_df[‘Age‘], 5) #把Age列等间隔分成5个区间 train_df[[‘AgeBand‘, ‘Survived‘]].groupby([‘AgeBand‘], as_index=False).mean().sort_values(by=‘AgeBand‘, ascending=True)
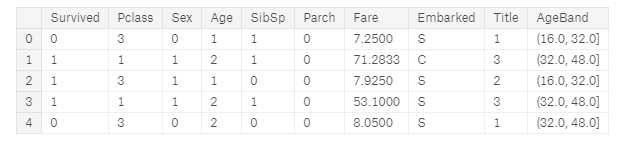
让我们使用序列来代替Age上的区间
for dataset in combine: dataset.loc[ dataset[‘Age‘] <= 16, ‘Age‘] = 0 dataset.loc[(dataset[‘Age‘] > 16) & (dataset[‘Age‘] <= 32), ‘Age‘] = 1 dataset.loc[(dataset[‘Age‘] > 32) & (dataset[‘Age‘] <= 48), ‘Age‘] = 2 dataset.loc[(dataset[‘Age‘] > 48) & (dataset[‘Age‘] <= 64), ‘Age‘] = 3 dataset.loc[ dataset[‘Age‘] > 64, ‘Age‘] train_df.head()
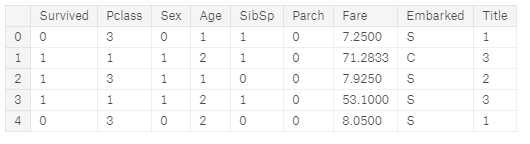
然后移除 AgeBand 列
train_df = train_df.drop([‘AgeBand‘], axis=1) combine = [train_df, test_df] train_df.head()
基于现有的特征来创建新的特征
我们可以为 FamilySize 创建一个新特征,它结合了 Parch 和 SibSp 。 这将使我们能够从数据集中删除Parch和SibSp。
for dataset in combine: dataset[‘FamilySize‘] = dataset[‘SibSp‘] + dataset[‘Parch‘] + 1 train_df[[‘FamilySize‘, ‘Survived‘]].groupby([‘FamilySize‘], as_index=False).mean().sort_values(by=‘Survived‘, ascending=False)
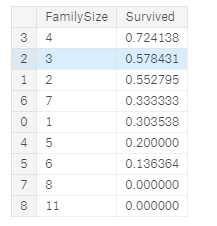
我们可以创建另外一个特征叫做 isAlone
for dataset in combine: dataset[‘IsAlone‘] = 0 dataset.loc[dataset[‘FamilySize‘] == 1, ‘IsAlone‘] = 1 train_df[[‘IsAlone‘, ‘Survived‘]].groupby([‘IsAlone‘], as_index=False).mean()
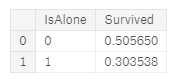
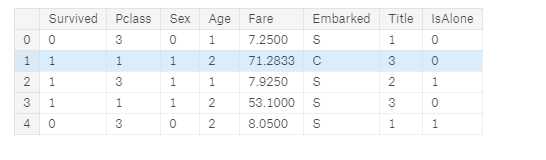
让我们放弃Parch,SibSp和FamilySize特征,转而使用IsAlone。
train_df = train_df.drop([‘Parch‘, ‘SibSp‘, ‘FamilySize‘], axis=1) test_df = test_df.drop([‘Parch‘, ‘SibSp‘, ‘FamilySize‘], axis=1) combine = [train_df, test_df] train_df.head()
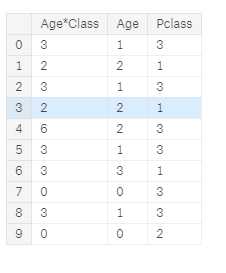
我们还可以创建一个结合了Pclass和Age的人工特征。
for dataset in combine: dataset[‘Age*Class‘] = dataset.Age * dataset.Pclass train_df.loc[:, [‘Age*Class‘, ‘Age‘, ‘Pclass‘]].head(10)
完成分类功能
Embarked 特征根据 登船港口获取S,Q,C值。 我们的训练数据集有两个缺失值。 我们只是填写最常见的事件。
freq_port = train_df.Embarked.dropna().mode()[0] freq_port # ‘S‘ for dataset in combine: dataset[‘Embarked‘] = dataset[‘Embarked‘].fillna(freq_port) train_df[[‘Embarked‘, ‘Survived‘]].groupby([‘Embarked‘], as_index=False).mean().sort_values(by=‘Survived‘, ascending=False)
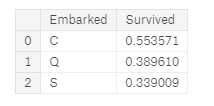
### Converting categorical feature to numeric
We can now convert the EmbarkedFill feature by creating a new numeric Port feature.
标签:sel == regress 数值 eps 存在 block 决策 count
原文地址:https://www.cnblogs.com/hotsnow/p/9488523.html