标签:过程 span height 无法 特性 修复 个数 bsp search
之前我们谈论过AVL树,这是一种典型适度平衡的二叉搜索树,成立条件是保持平衡因子在[-1,1]的范围内,这个条件已经是针对理想平衡做出的一个妥协了,但依然显得过于苛刻,因为在很多时候我们需要频繁的做重平衡操作,能不能改进一下,让失衡先积累着,然后等到某个时机,一下子全部解决呢?严谨一点来说就是我们能否秉持一种更为宽松的准则,同时又从长远、整体的角度来看,依然不失某种意义上的平衡性呢?
根据写作套路,那肯定就是点题了。。。对!就是伸展树了,他的出现是因为有人注意到了在信息处理过程中的“局部性”,就是刚被访问过的数据,极有可能很快的被再次访问到,针对特性大做文章,就能切中肯綮了,这也是下面我们要分析的细节。
在二叉搜索树里也时常遇到,主要是两种情况:
通过此前的学习我们已经知道,对于AVL树而 每一次查找所需的时间都是logn,因此任意的连续m次查找,所需要的累积时间就是mlogn,为了改进,就针对这个局部性来做一做文章吧:先来看一个例子,然后类比推理即可。链表里越靠近表头的节点的查找速度越快,遍历所走的步数少嘛,那么如果数据访问有局部性,我们就——访问一个元素后立即把他移动到最前端。
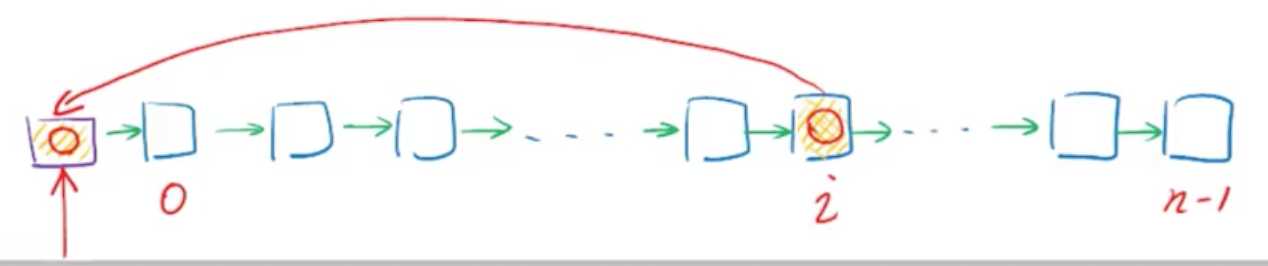
这样做的逻辑是:根据局部性,接下来将要访问的元素很可能就是刚访问的那个元素,而这个元素就在最前端,头部元素的访问是访问是唾手可得的,走一步就到了。从整个数据结构的生命周期而言,这样一个列表结构即便最初是完全随机分布的,在经过了足够长时间的使用之后,在某一段时间内被集中访问的元素都会集中到这个列表的前端去。我们已经知道这个区域(列表前段部分)的访问效率是相应更高的,那就能有更高的访问效率了。
现在回到二叉树,为了对比就让树横过来。
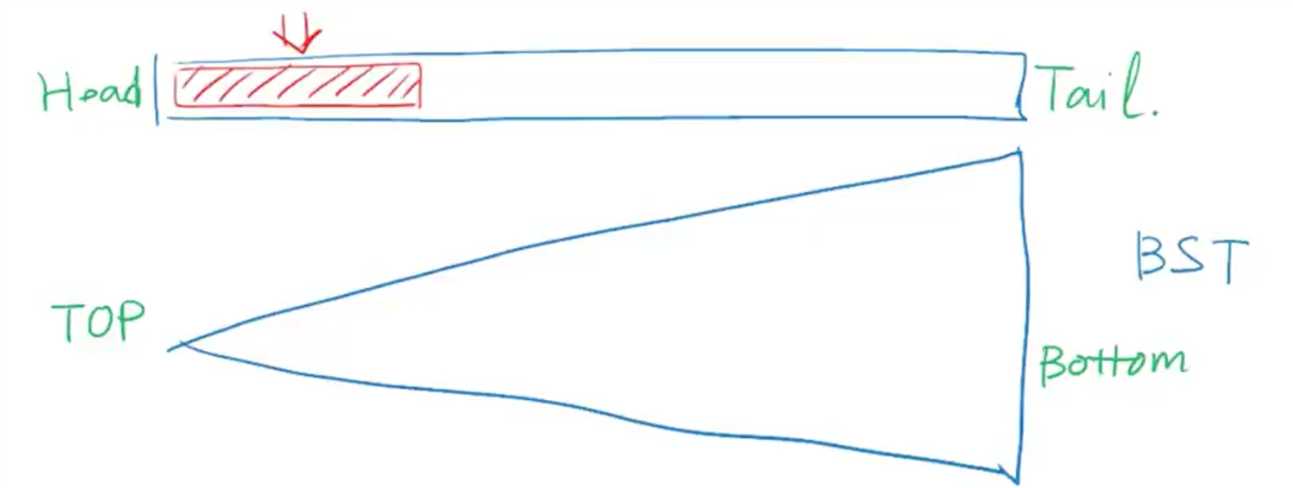
树的顶部元素访问效率更高,所以我们要参照列表,把经常要访问到的元素尽可能的移送到接近树根的位置,也就是要尽可能的降低他们的深度。
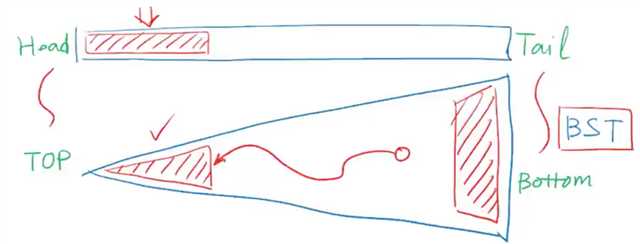
那我们就这么办:某个元素一经访问,就把它移到树根处。具体做法就是把被访问元素不断做旋转操作直到抵达树根,这样的策略被称为“逐层伸展”,是一种朴素的想法,但是不够好,因为在最坏情况下树退化为一条单链,我们来个极端的,每次恶意访问最深的节点,就会变成这样:
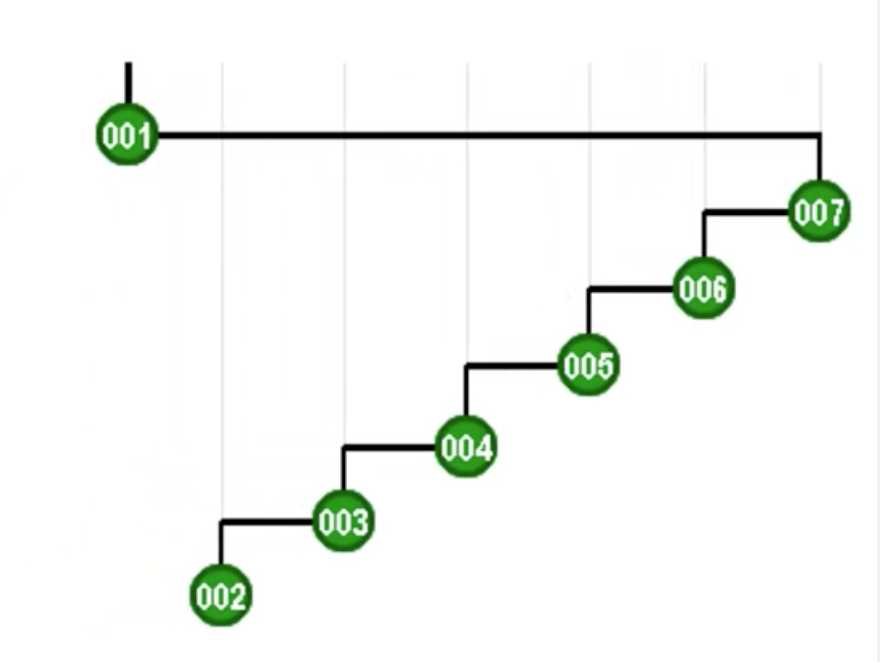
先注意一下特征:每层只挂了一个节点,这是弊端所在,后面还会提到。然后经过一轮询问,这个树就复原了。看一下整个过程(竖着看)
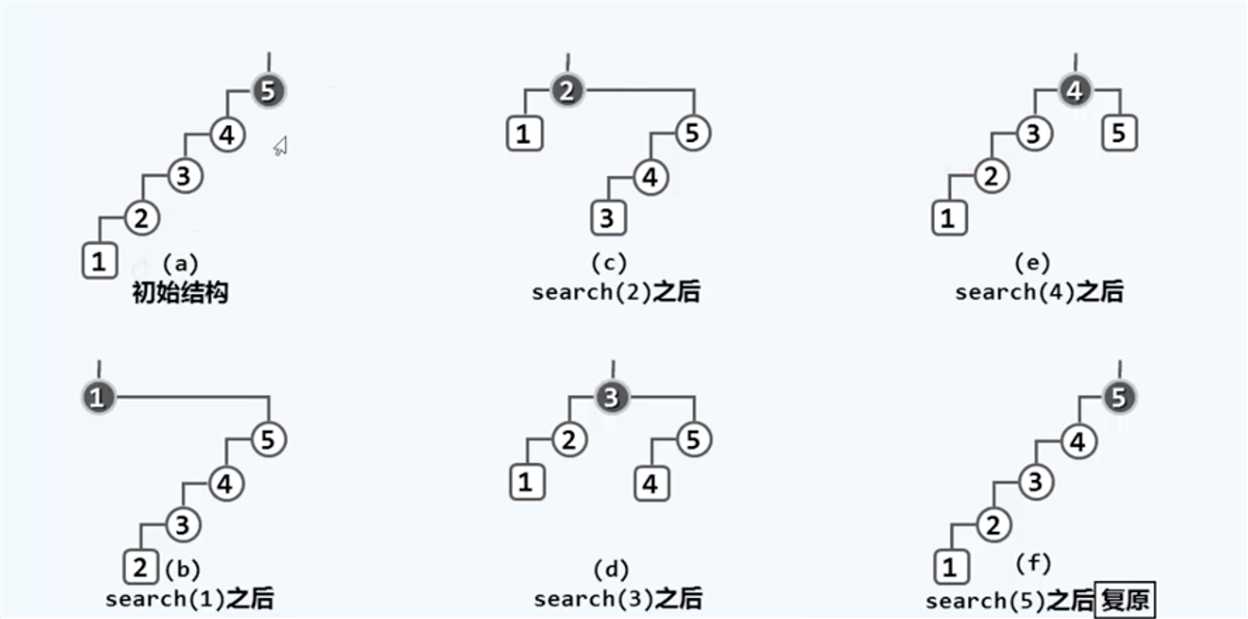
我们分析一下这一轮操作的代价:假设树的规模是n,访问第一个最深节点的成本是n,第二个节点是n-1,第三个是n-2,然后是n-3,n-4和最终的1。整个成本按算术级数增长,这就很恐怖了,总体时间O(N2),分摊到整个周期的n次操作,复杂度Ω(N)居高不下,和AVL树的logn相差甚远,这已经沦落到了线性序列的地步。另外还有一个弊端在于:我们需要为此考虑很多种特殊情况。所以这个策略无法让人满意。
我们还要另找方法——在初始访问路径上进行一些神奇的旋转,只用了O(1)的空间,而且保持O(logN)的时间复杂度。
具体而言就是:双层伸展,向上追溯两层,通过两次旋转把被访问节点上移至祖父的位置,而且!不是像之前一样自下而上伸展,而是自顶向下进行伸展。这可以说是SplayTree的点睛之笔。这是在1985年Tarjan大神的一篇论文《Self-adjusting binary search trees》里提出来的(和他有关的还有一个Tarjan算法,是关于图的连通性的神奇算法)。他们的相对位置无非四种:之字型两种,一字型两种。
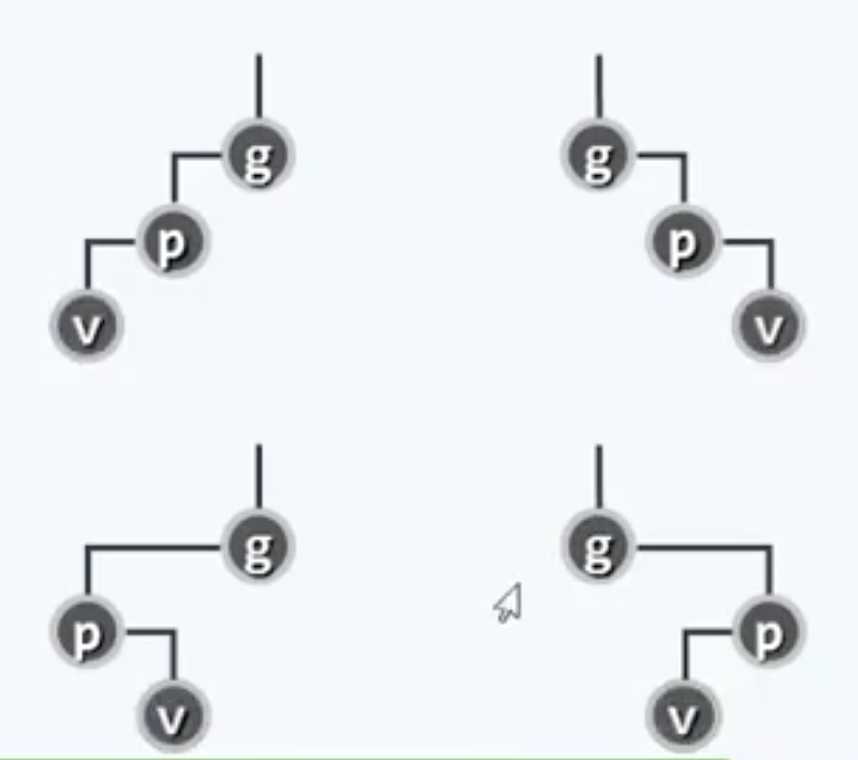
子孙异侧
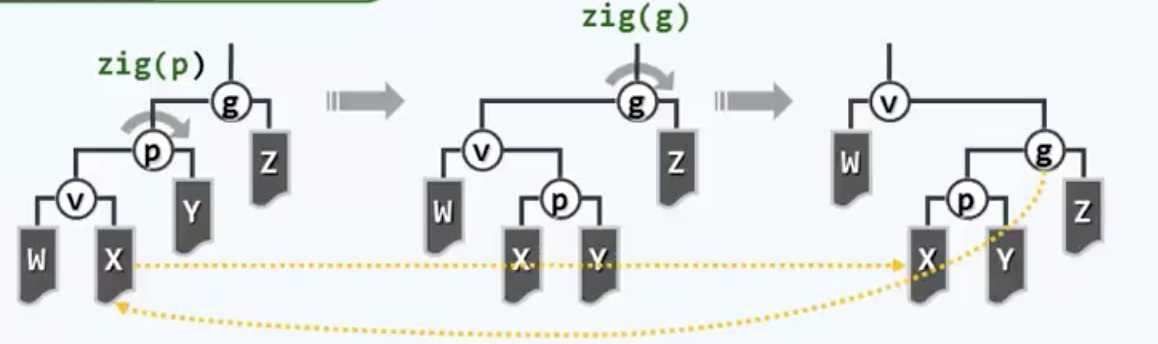
先从这个情况说起,从难啃的骨头开始。有些书上会把这种情况称为“之字形”,以此为例:
“这特么不就是双旋转么,而且这也就是逐层伸展两次而已,没什么实质区别啊(摔)”,的确是这样,这个部分区别不大。但重点在于另外这条龙一只眼睛才是闪光之处。
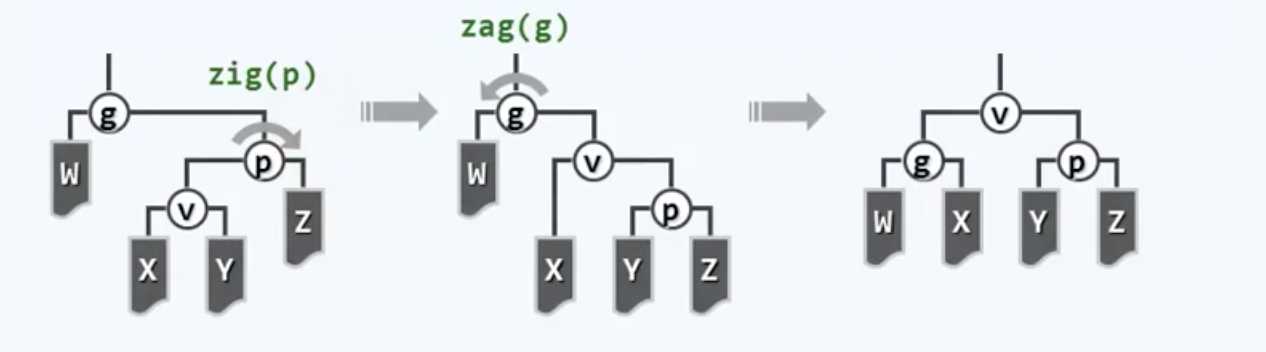
子孙同侧
有些书上也称为“一字形”。我们先看一下逐层伸展的调整过程,然后和Tarjan的策略作一比较,就知道差距有多大了。
这是我们凡人想到的方法。下面是Tarjan的点睛之笔:
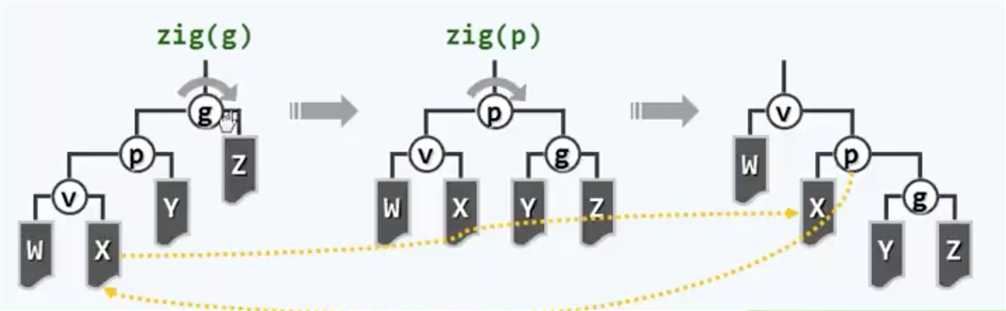
这里的重中之重是:需要首先越级,从祖父而不是父节点来开始旋转,具体来说就是,经过祖父节点的一次左-左旋转,节点p以及v都会上升一层。接下来对新的树根也就是p,再做一次左-左旋转,把v拉上来成为树根,Done。把这两种方法作一对比,emmm好像没什么大差别啊,是吧?的确这里面的神奇之处一时半会难以察觉,看起来反正都是提高了两层倍,
毕竟在局部拓扑结构上还是有微妙的差异,更重要的是——这种局部的微妙差异将导致全局的不同,而且那种不同将是根本性的、颠覆性的!Splay树在这个伸展方式的革命中失去的只是锁链,他们获得的将是整个世界。
现在来看看这个差异所带来的利好。如果用这种方式我们再来访问最深的节点,会有什么改进呢?
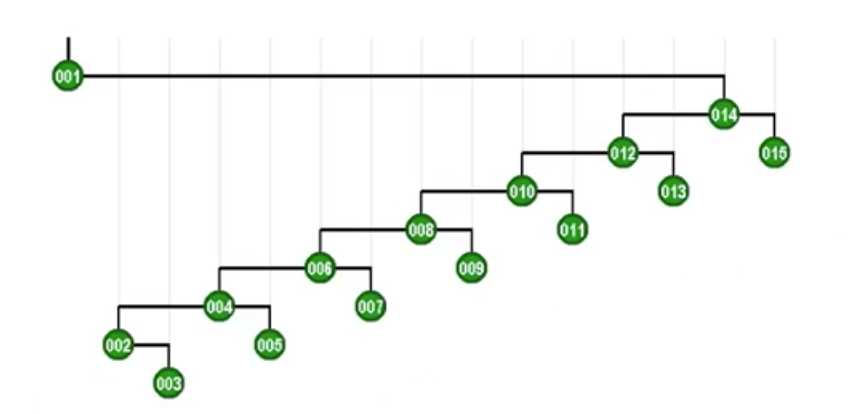
现在的改进在于每一层能挂更多的节点了,这就是有效控制树高的一个方法。之前说的逐层伸展最坏情况之所以“坏”是因为,尽管能调整到树根,但是在这个过程中树的高度会以算术级数的速度急剧膨胀,这是一种不计后果的方法,所以很坏。而Tarjan的方法优越性在于,在每次即使访问最深的节点时候,也能控制树高,渐进意义上是之前逐层伸展树高的一半,记得前面说的“会导致全局的不同”么,就是这里的树高缩减一半!这个特性太好了,节点越多,访问次数越多,这个控制的效果越明显,这也被称为SplayTree的折叠效果。那么总结一下双层伸展的核心优势——

通过这个例子可以看出:任何一个节点经过访问,再经双层调整后,这个节点所在的路径长度就会减半。甚至可以说——这种效果具有某种意义上的智能:既然在一棵BST中非常忌讳访问很深的节点(这会导致复杂度急剧上升),那这种折叠效果自然就会具有对坏节点的修复作用,我们就不必担心了。犹如含羞草一旦感受到威胁,就会通过迅速收缩,将自己的弱点隐藏起来。因此在采用Tarjan所建议的这种新的策略之后,刚才所举的那种最坏情况就不至持续的发生,可以证明的是单次操作的时间上界是O(logN)。这也就是说!我们现在不仅足以应对此前涉及的最坏情况,而且也不会有任何其他的最坏情况,这是一个再好不过的消息了,简直让人开心到爆炸啊!
为了控制篇幅,也考虑到注意力的问题,具体的实现放在下一篇文章,因为那将会涉及到很多指针调整,需要集中精力,看到这里想必注意力消耗的差不多了,再看下去就容易跑神,具体的实现步骤相比上面的清谈要更耗费心力,因为我们要和细节打交道了。
标签:过程 span height 无法 特性 修复 个数 bsp search
原文地址:https://www.cnblogs.com/hongshijie/p/9497088.html