标签:综述 运动 ble 视频识别 lin lstm nta 类别 kill
【胡扯】:最近一周一直在忙着做视频识别的项目,前期对视频完全小白,最近复现了cvpr 2018 上面的一篇文章,效果还行,下周把自己的思路加上网络,进行训练,看看效果如何,我想应该效果不错,因为我是大佬呀~~~哈哈。这篇博文只是一些简单的综述,换言之也是我这周的学习之旅,就做个总结吧。
我们这里主要介绍常用的大点的数据集,像KTH 这种小的,咱就不说了。
其实也没啥介绍的,就是101种视频,现在CVPR 最高的结果好像是>93.4% 效果还是不错的。
官网:UCF101
使用方式:UCF101的处理与加载
这个数据集最难,现在最高的识别率也就82%左右,其实我感觉主要数据量太少了,如果这个数据集能扩充,估计效果还行,有没有小伙伴去干这件事情呢,我的意思是只针对这51种视频,数据量(double kill、 triple kill、quadra kill、penta kill)原谅我是moba 游戏粉呢。如果数据量充分,我想我后面介绍的几种思路的结果应该可以更上一层楼。
官网:HMDB51
这个思路其实很朴素,在image caption中现在最先进的一类方法就是在这个加上attention model。
方法如下:
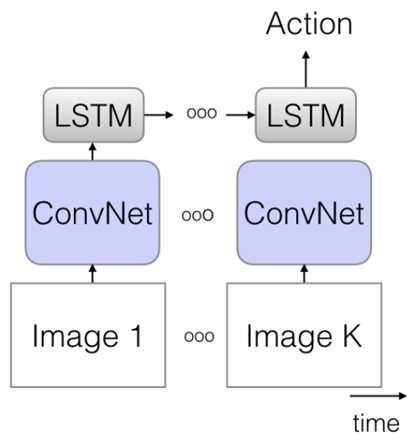
视频嘛,说白了就是由很多图片组成的,只是这些图片有个特点就是有很强的时序性,那么这就好办了啊,抽取特征,然后代入RNN 或者LSTM,最后进行预测,这个想法很直接,但是目前的效果不太好,不过这个时序的思想,可以借用。
这个就是传统的卷积上加了一维用于预测时序,以前的卷积核是这样(Kxk),现在的卷积核是这样(kxkxk)变成了三维的,最后一维就是时序,框架如下:
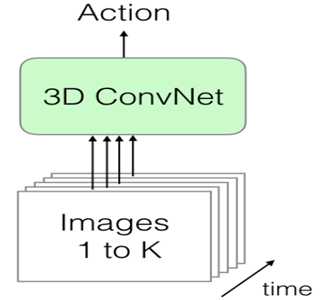
但是这个方法有个缺点就是参数特别巨大,而视频这一块的数据量不够,也不能这么说,就是被清洗干净的数据集太少了,希望有李飞飞那样的大佬出来,出一个更大的数据集。
3 Two-stream
双流型:
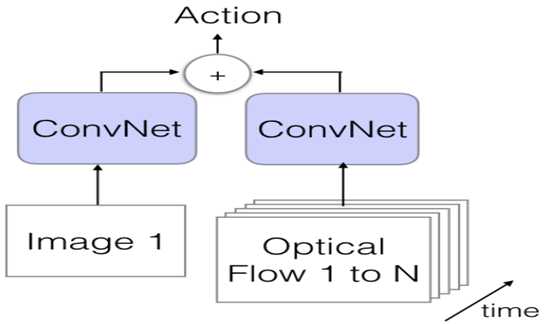
如上图,视频可以很自然的被分为 空间部分和时间部分,空间部分主要对应单张图像中的 appearance,传递视频中描述的场景和物体的相关信息。时间部分对应连续帧的运动,主要用最基本的光流法,有兴趣的小伙伴可以去研究下,包含物体和观察者(相机)的运动信息,之后直接进行特征相连进行分类(这里没有融合,之后这篇文章的下文就进行了融合)。 这篇文章是2014NIPS上发表的:
Two-Stream Convolutional Networks for Action Recognition in Videos
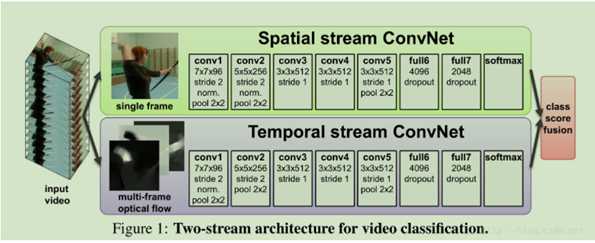
下面的图是论文额框架,更加清晰:
4:3D-Fused two-strean
框架:
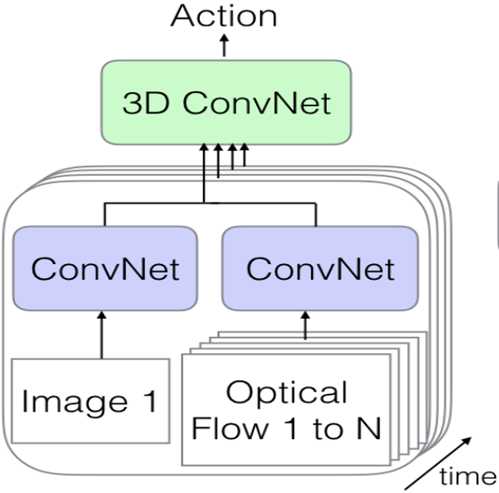
这个用3D convNet的融合策略不一定是最好的,相信这里还有很多研究的机会。关于这个,大家可以仔细去看这篇文章。
Convolutional Two-Stream Network Fusion for Video Action Recognition
5:two-stream 3D-ConvNet
这个方法的思路也比较自然,结合了第二种结构和第三种结构,如图:
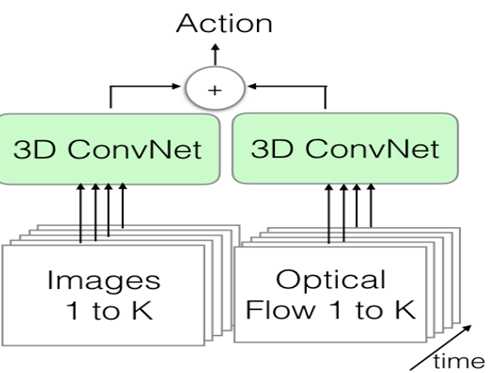
把一段视频分成n个K帧大小的视频流,然后分别用两个3D 卷积进行apperance 和光流进行特征抽取,在连接成一组新的特征,作为最后的识别特征,这个方法的缺点还是参数太多,咱们的数据集太小,容易过拟合,但是kinetics出来,很好的解决了这个问题,所有这个方法是现在最好的。
结尾
写的不是太多,也不详细,只是粗略地整理了下思路。
思路点1:识别动作,无非就是时间与空间的协调性,如何处理这两者的关系。
思路点2:两者的融合问题。
思路点3:我感觉视频里的多余动作如何进行有效隔离,这个是研究的重点。、
视频动作识别的应用:
标签:综述 运动 ble 视频识别 lin lstm nta 类别 kill
原文地址:https://www.cnblogs.com/xiaohuahua108/p/9497431.html