标签:的区别 服务器 种类 数据库 概念 最好 几分钟 主备 aws
1.高可用 (High Availability,简称 HA)
高可用性是指提供在本地系统单个组件故障情况下,能继续访问应用的能力,无论这个故障是业务流程、物理设施、IT软/硬件的故障。最好的可用性, 就是你的一台机器宕机了,但是使用你的服务的用户完全感觉不到。你的机器宕机了,在该机器上运行的服务肯定得做故障切换(failover),切换有两个维度的成本:RTO (Recovery Time Objective)和 RPO(Recovery Point Objective)。RTO 是服务恢复的时间,最佳的情况是 0,这意味着服务立即恢复;最坏是无穷大意味着服务永远恢复不了;RPO 是切换时向前恢复的数据的时间长度,0 意味着使用同步的数据,大于 0 意味着有数据丢失,比如 ” RPO = 1 天“ 意味着恢复时使用一天前的数据,那么一天之内的数据就丢失了。因此,恢复的最佳结果是 RTO = RPO = 0,但是这个太理想,或者要实现的话成本太高,全球估计 Visa 等少数几个公司能实现,或者几乎实现。
对 HA 来说,往往使用共享存储,这样的话,RPO =0 ;同时往往使用 Active/Active (双活集群) HA 模式来使得 RTO 几乎0,如果使用 Active/Passive 模式的 HA 的话,则需要将 RTO 减少到最小限度。HA 的计算公式是[ 1 - (宕机时间)/(宕机时间 + 运行时间)],我们常常用几个 9 表示可用性:
- 2 个9:99% = 1% * 365 = 3.65 * 24 小时/年 = 87.6 小时/年的宕机时间
- 4 个9: 99.99% = 0.01% * 365 * 24 * 60 = 52.56 分钟/年
- 5 个9:99.999% = 0.001% * 365 = 5.265 分钟/年的宕机时间,也就意味着每次停机时间在一到两分钟。
- 11 个 9:几乎就是几年才宕机几分钟。 据说 AWS S3 的设计高可用性就是 11 个 9。
服务的分类
HA 将服务分为两类:
- 有状态服务:后续对服务的请求依赖于之前对服务的请求。
- 无状态服务:对服务的请求之间没有依赖关系,是完全独立的。
HA 的种类
HA 需要使用冗余的服务器组成集群来运行负载,包括应用和服务。这种冗余性也可以将 HA 分为两类:
- Active/Passive HA:集群只包括两个节点简称主备。在这种配置下,系统采用主和备用机器来提供服务,系统只在主设备上提供服务。在主设备故障时,备设备上的服务被启动来替代主设备提供的服务。典型地,可以采用 CRM 软件比如 Pacemaker 来控制主备设备之间的切换,并提供一个虚机 IP 来提供服务。
- Active/Active HA:集群只包括两个节点时简称双活,包括多节点时成为多主(Multi-master)。在这种配置下,系统在集群内所有服务器上运行同样的负载。以数据库为例,对一个实例的更新,会被同步到所有实例上。这种配置下往往采用负载均衡软件比如 HAProxy 来提供服务的虚拟 IP。
2.灾难恢复 (Disaster Recovery)
几个概念:
- 灾难(Disaster)是由于人为或自然的原因,造成一个数据中心内的信息系统运行严重故障或瘫痪,使信息系统支持的业务功能停顿或服务水平不可接受、达到特定的时间的突发性事件,通常导致信息系统需要切换到备用场地运行。
- 灾难恢复(Diaster Recovery)是指当灾难破坏生产中心时在不同地点的数据中心内恢复数据、应用或者业务的能力。
- 容灾是指,除了生产站点以外,用户另外建立的冗余站点,当灾难发生,生产站点受到破坏时,冗余站点可以接管用户正常的业务,达到业务不间断的目的。为了达到更高的可用性,许多用户甚至建立多个冗余站点。
- 衡量容灾系统有两个主要指标:RPO(Recovery Point Objective)和 RTO(Recovery Time Object),其中 RPO代表 了当灾难发生时允许丢失的数据量,而 RTO 则代表了系统恢复的时间。RPO 与 RTO 越小,系统的可用性就越高,当然用户需要的投资也越大。
大体上讲,容灾可以分为3个级别:数据级别、应用级别以及业务级别。
| 级别 |
定义 |
RTO |
CTO |
| 数据级 |
指通过建立异地容灾中心,做数据的远程备份,在灾难发生之后要确保原有的数据不会丢失或者遭到破坏。但在数据级容灾这个级别,发生灾难时应用是会中断的。
在数据级容灾方式下,所建立的异地容灾中心可以简单地把它理解成一个远程的数据备份中心。数据级容灾的恢复时间比较长,但是相比其他容灾级别来讲它的费用比较低,而且构建实施也相对简单。
但是,“数据源是一切关键性业务系统的生命源泉”,因此数据级容灾必不可少。
|
RTO 最长(若干天) ,因为灾难发生时,需要重新部署机器,利用备份数据恢复业务。 |
最低 |
| 应用级 |
在数据级容灾的基础之上,在备份站点同样构建一套相同的应用系统,通过同步或异步复制技术,这样可以保证关键应用在允许的时间范围内恢复运行,尽可能减少灾难带来的损失,让用户基本感受不到灾难的发生,这样就使系统所提供的服务是完整的、可靠的和安全的。 |
RTO 中等(若干小时) |
中等。异地可以搭建一样的系统,或者小些的系统。 |
| 业务级 |
全业务的灾备,除了必要的 IT 相关技术,还要求具备全部的基础设施。其大部分内容是非IT系统(如电话、办公地点等),当大灾难发生后,原有的办公场所都会受到破坏,除了数据和应用的恢复,更需要一个备份的工作场所能够正常的开展业务。 |
RTO 最小(若干分钟或者秒) |
最高
|
3.HA 和 DR 的关系
两者相互关联,互相补充,互有交叉,同时又有显著的区别:
- HA 往往指本地的高可用系统,表示在多个服务器运行一个或多种应用的情况下,应确保任意服务器出现任何故障时,其运行的应用不能中断,应用程序和系统应能迅速切换到其它服务器上运行,即本地系统集群和热备份。HA 往往是用共享存储,因此往往不会有数据丢失(RPO = 0),更多的是切换时间长度考虑即 RTO。
- DR 是指异地(同城或者异地)的高可用系统,表示在灾害发生时,数据、应用以及业务的恢复能力。异地灾备的数据灾备部分是使用数据复制,根据使用的不同数据复制技术(同步、异步、Strectched Cluster 等),数据往往有损失导致 RPO >0;而异地的应用切换往往需要更长的时间,这样 RT0 >0。 因此,需要结合特定的业务需求,来定制所需要的 RTO 和 RPO,以实现最优的 CTO。
也可以从别的角度上看待两者的区别:
- 从故障角度,HA 主要处理单组件的故障导致负载在集群内的服务器之间的切换,DR 则是应对大规模的故障导致负载在数据中心之间做切换。
- 从网络角度,LAN 尺度的任务是 HA 的范畴,WAN 尺度的任务是 DR 的范围。
- 从云的角度看,HA 是一个云环境内保障业务持续性的机制,DR 是多个云环境间保障业务持续性的机制。
- 从目标角度,HA 主要是保证业务高可用,DR 是保证数据可靠的基础上的业务可用。
一个异地容灾系统,往往包括本地的 HA 集群和异地的 DR 数据中心。一个示例如下:

aster SQL Server 发生故障时,切换到 Standby SQL Server,继续提供数据库服务:

在主机房中心发生灾难时,切换到备份机房(总公司机房中心)上,恢复应用和服务:

4.现有系统的灾备架构
现有一个完整的应用灾备架构如图:
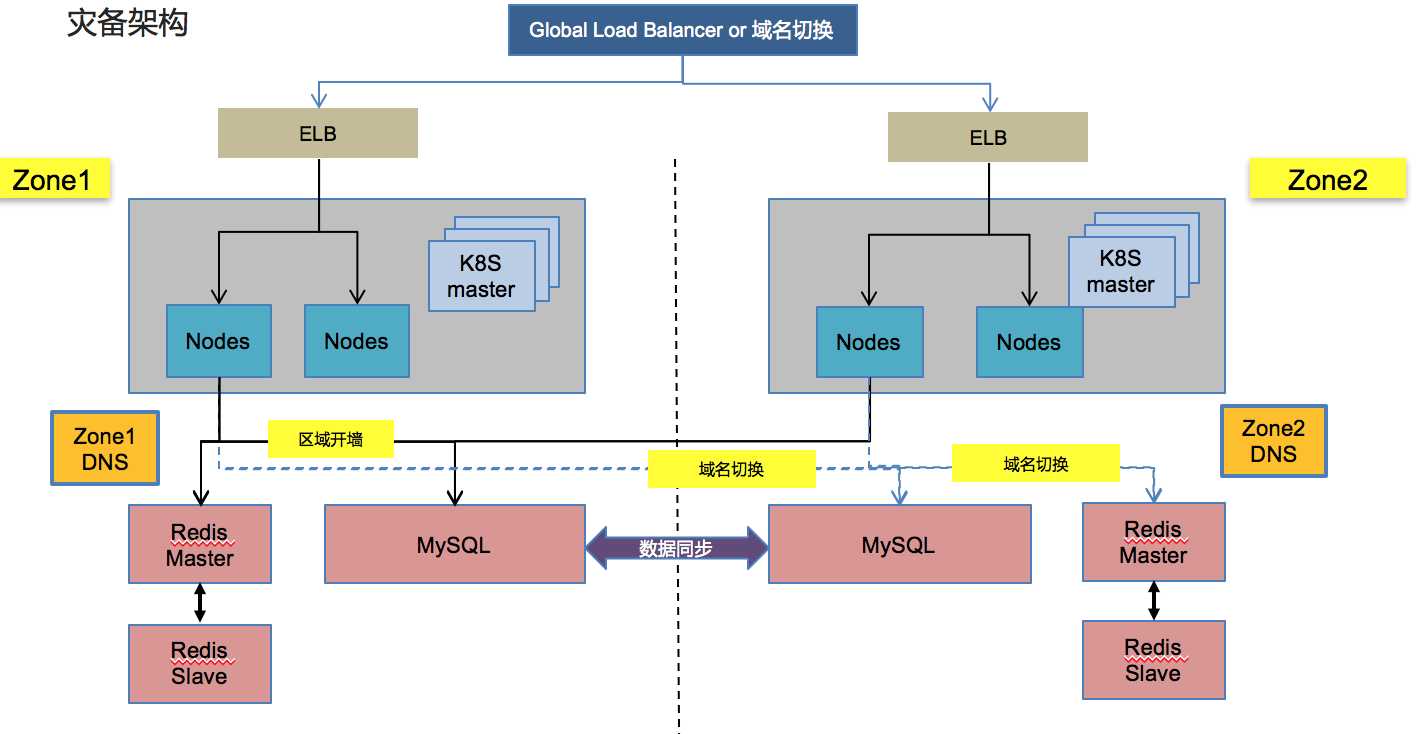
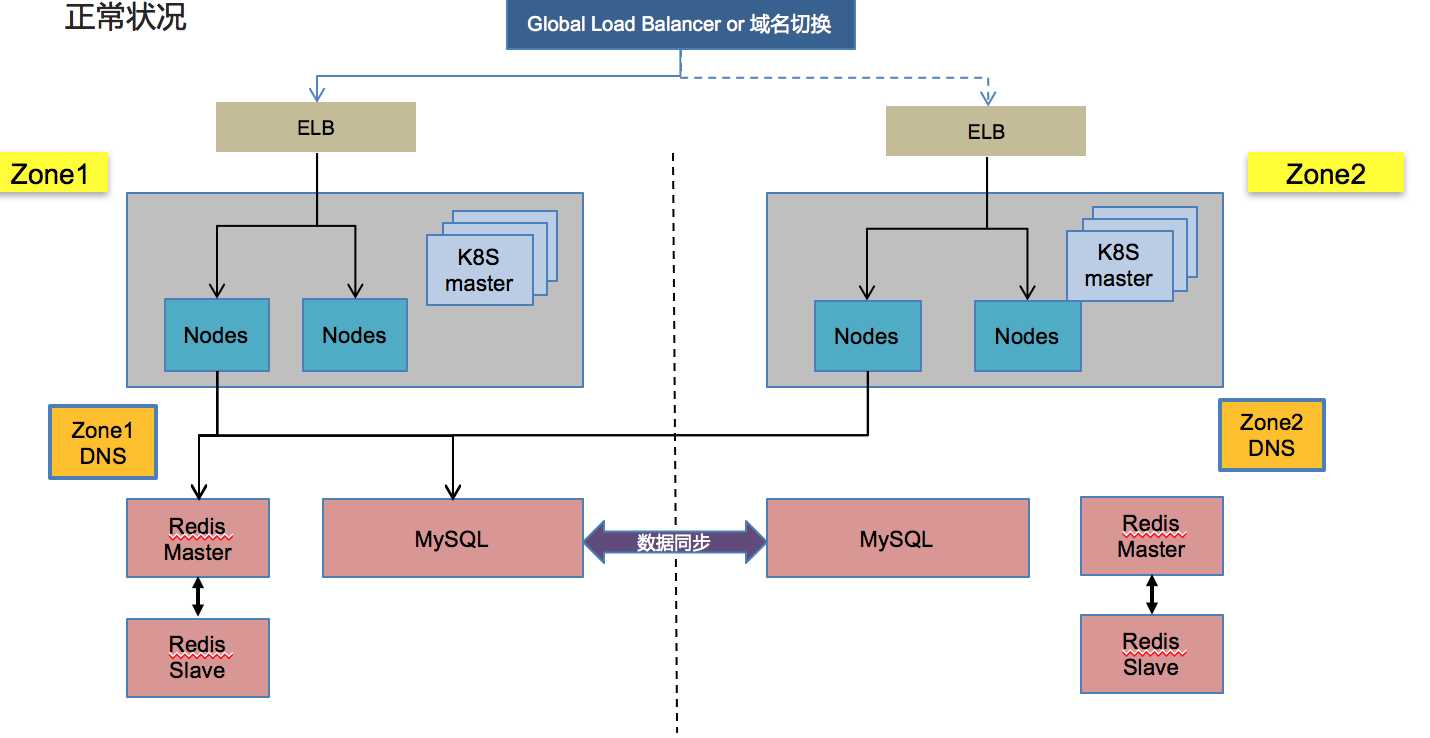
正常状况下,大家都联同一个区域的数据库
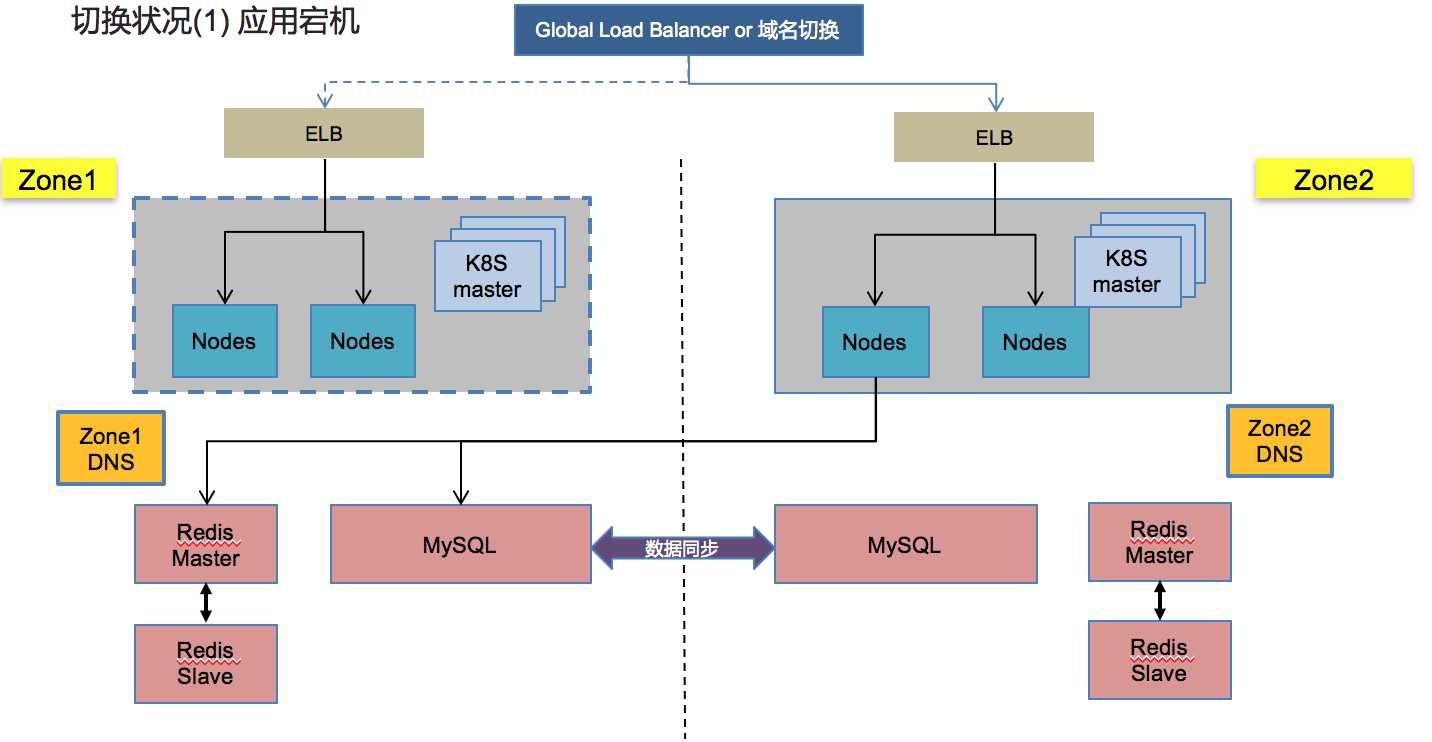
区域1应用当机情况:
应用及数据库当机情况:
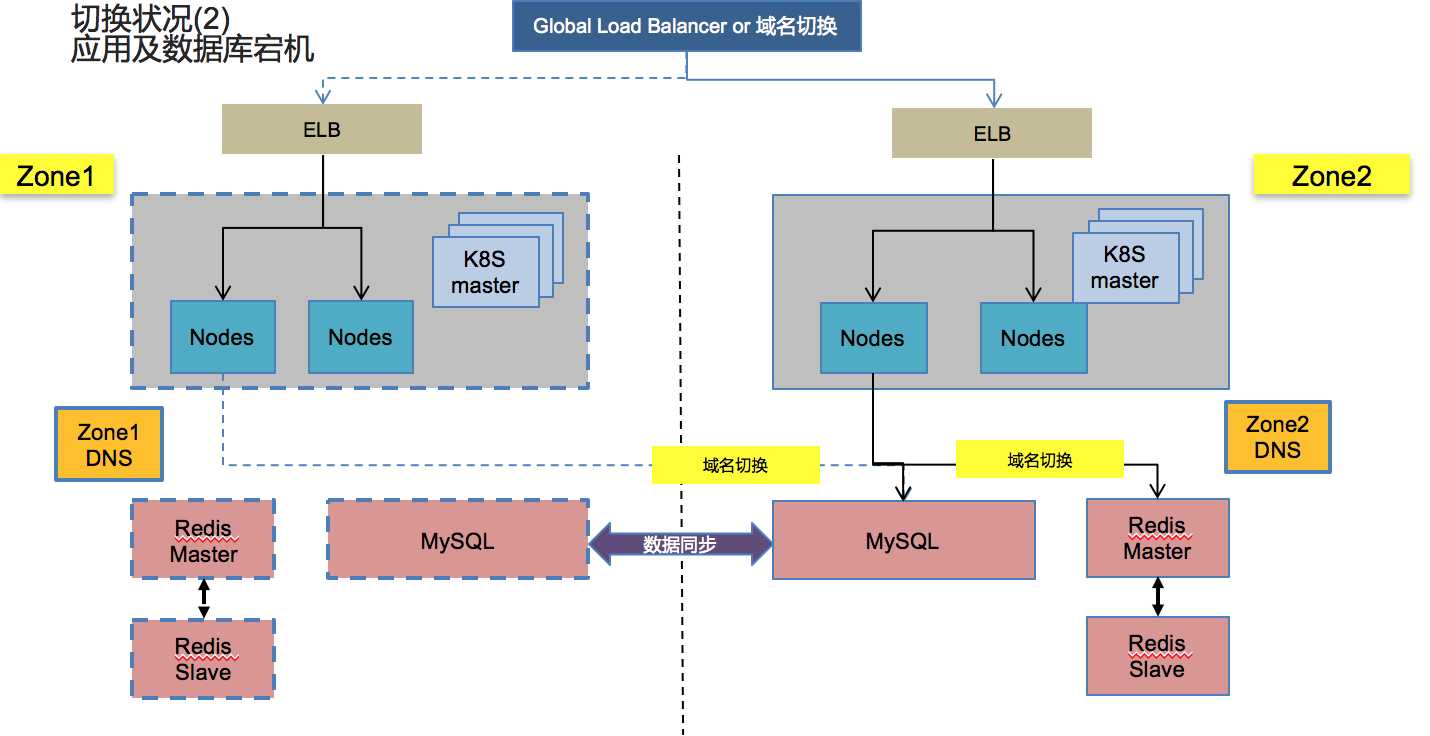
现有架构问题:
- 应用需要在两个区域分别发版本
- 在Kubernetes架构下,容器无法停止,只能基于helm进行删除,这导致再次切回来时需要重新发版本,存在风险
- 持久化数据通过nas进行不同区域间的拷贝,在非计划当机中,需要规划备份的时间
- 数据库和Redis域名同样基于域名切换,而不是VIP切换,易于出错
优化方案:
- 尝试Kubernetes Federation,解决多次发版本问题
- Zone1能否在出现问题时不再运行?有待探讨。
理解高可用和灾备
标签:的区别 服务器 种类 数据库 概念 最好 几分钟 主备 aws
原文地址:https://www.cnblogs.com/ericnie/p/9503012.html