标签:view 就是 任务 权重 src 现象 操作 工作 1.5
from https://blog.csdn.net/weixin_40645129/article/details/81173088
CVPR2018已公布关于视频目标跟踪的论文简要分析与总结
一,A Twofold Siamese Network for Real-Time Object Tracking
|
论文名称 |
A Twofold Siamese Network for Real-Time Object Tracking |
|
简介 |
此算法在SiamFC的基础上增加了语义分支,进一步提升SiamFC的判别力,从而提升了跟踪效果,即使损失了一些速度,但是仍然达到了实时的跟踪速度。总的来说,本文思路简单明了,逻辑清晰,道理透彻,是一个不错的单目标跟踪工作,唯一欠缺的是其仍然沿用SiamFC在跟踪过程中所有帧都和第一帧对比,是该类方法的主要缺陷。 |
|
创新点 |
1:将图像分类任务中的语义特征与相似度匹配任务中的外观特征互补结合,非常适合目标跟踪任务,因此此算法可以简单概括为:SA-Siam=语义分支+外观分支; 2:对于新引入的语义分支,此算法进一步提出了通道注意力机制。在使用网络提取目标物体的特征时,不同的目标激活不同的特征通道,作者对被激活的通道赋予高的权值,此算法通过目标物体在网络特定层中的响应计算这些不同层的权值。 3:Motivation:目标跟踪的特点是,作者从众多背景中区分出变化的目标物体,其中难点为:背景和变化。此算法的思想是用一个语义分支过滤掉背景,同时用一个外观特征分支来泛化目标的变化,如果一个物体被语义分支判定为不是背景,并且被外观特征分支判断为该物体由目标物体变化而来,那就认为这个物体即需要被跟踪的物体; |
|
主要框架 |
基于SiamFC修改,Siamese 网络 |
|
效果 |
速度:50fps, 语义分支权重:外观分支权重 = 7:3 OTB实验:OTB-2013(0.896,0.677),OTB-2015(0.865,0.657) |
|
代码 |
没公布 |
二,Context-aware Deep Feature Compression for High-speed Visual Tracking
|
论文名称 |
Context-aware Deep Feature Compression for High-speed Visual Tracking |
|
简介 |
作者提出了一种在实时跟踪领域高速且state-of-the-art表现的基于context-aware correlation filter的跟踪框架。这个方法的高速性依赖于会根据内容选择对应的专家自编码器来对图片进行压缩;context在此算法中表示根据要跟踪目标的外观大致分的类。在预训练阶段,每个类训练一个自编码器。在跟踪阶段,根据给定目标选择最佳的自编码器——专家自编码器,并且在下面阶段中仅使用这个网络。为了在压缩后的特征图上达到好的跟踪效果,作者分别在与训练阶段和微调专家自编码器阶段提出了一种去噪过程和新的正交损失函数。 |
|
创新点 |
对于视频这种高维度数据,作者训练了多个自编码器AE来进行数据压缩,至于怎么选择具体的网络, 本文创新的地方在于: |
|
主要框架 |
correlation filter+ VGG-Net |
|
效果 |
速度:超过100fps。 精度: |
|
代码 |
没公布 |
三,Learning Spatial-Temporal Regularized Correlation Filters for Visual Tracking
|
论文名称 |
Learning Spatial-Temporal Regularized Correlation Filters for Visual Tracking(STRCF) |
|
简介 |
此算法研究了在不损失效率的情况下,利用空间正则化和大型训练集形式的优点的方法。一方面,SRDCF 的高复杂度主要来源于对多幅图像的训练形式。通过去除约束条件,单图像样本上的 SRDCF 可以通过 ADMM 有效地解决。由于 SRDCF 的凸性,ADMM 也能保证收敛到全局最优。另一方面,在 SRDCF 算法中,将空间正则化集成到多幅图像的训练形式中,实现了 DCF 学习与模型更新的耦合,提高了追踪准确率。在在线被动攻击 ( PA ) 学习 [ 6] 的启发下,作者将时间正则化方法引入到单图像 SRDCF 中,得到了时空正则化相关滤波器 ( STRCF )。STRCF 是多训练图像上 SRDCF 形式的合理近似,也可用于同时进行 DCF 学习和模型更新。此外,ADMM 算法也可以直接用于求解 STRCF。因此,本文提出的 STRCF 将空间正则化和时间正则化结合到 DCF 中,可以用来加速 SRDCF。此外,作为在线 PA 算法的扩展,STRCF 还可以在外观大幅变化的情况下实现比 SRDCF 更鲁棒的外观建模。与 SRDCF 相比,引入时间正则化后的 STRCF 对遮挡具有更强的鲁棒性,同时能够很好地适应较大的外观变化。 |
|
创新点 |
|
|
主要框架 |
相关滤波,HOG,CN特征 |
|
效果 |
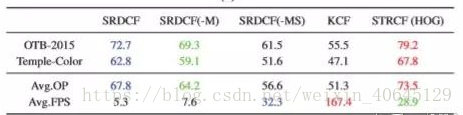
SRDCF 的变体和使用 HOG 特征的 STRCF 在 OTB-2015 和 Temple-Color 数据集上关于 OP(%)和速度(FPS)的比较。
|
|
代码 |
没公布 |
四,End-to-end Flow Correlation Tracking with Spatial-temporal Attention
|
论文名称 |
End-to-end Flow Correlation Tracking with Spatial-temporal Attention |
|
简介 |
首先是motivation,作者注意到几乎所有的跟踪器都只用到了RGB信息,很少有用到视频帧和帧之间丰富的运动信息;这就导致了跟踪器在目标遇到运动模糊或者部分遮挡的时候,性能只能依靠离线训练的特征的质量,鲁棒性很难保证。于是作者就想利用视频中的运动信息(Flow)来补偿这些情况下RGB信息的不足,来提升跟踪器的性能. 具体来说,作者首先利用历史帧和当前帧得到Flow,利用Flow信息把历史帧warp到当前帧,然后将warp过来的帧和本来的当前帧进行融合,这样就得到了当前帧不同view的特征表示,然后在Siamese和DCF框架下进行跟踪. |
|
创新点 |
1. 第一篇把Flow提取和tracking任务统一在一个网络里面的工作。 2.采用Siamese结构,分为historical branch和current branch. 在historical branch里面,进行Flow的提取和warp, 3.在融合阶段,我们设计了一种spatial-temporal attention的机制. 4.在current branch,只提取特征. Siamese结构两支出来的特征送进DCF layer, 得到response map. 总结来说,就是把Flow提取,warp操作,特征提取和融合,CF tracking都做成了网络的layer,端到端地训练它们。 |
|
主要框架 |
Siamese结构和DCF框架 |
|
效果 |
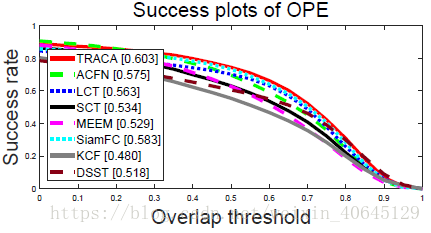
VOT2015结果 |
|
代码 |
没公布 |
五, Visual Tracking via Adversarial Learning
|
论文名称 |
Visual Tracking via Adversarial Learning(VITAL) |
|
简介 |
|
|
创新点 |
此算法主要分析了现有的检测式跟踪的框架在模型在线学习过程中的两个弊病,即: 2.正负样本之间存在严重的不均衡分布的问题; |
|
主要框架 |
在VGG-M模型基础上进行改进 |
|
效果 |
速度:1.5fps,(在Tesla K40c GPU下的速度) |
|
代码 |
没公布 |
六,Unveiling the Power of Deep Tracking
|
论文名称 |
Unveiling the Power of Deep Tracking(ECO+) |
|
简介 |
论文是对ECO的改进,deep tracker无法受益于更好更深CNN的深度特征,针对这一反常现象,实验和分析表明这主要是由于浅层特征和深度特征的特性差异,两种特征分而治之,深度特征部分加入了数据增强增加训练样本数量,用不同label function,浅层特征正样本更少,深度特征正样本更多。两部分响应图自适应融合,提出了可以同时反映准确性和鲁棒性的检测质量估计方法,基于这个质量评估,最优化方法自适应融合两部分的响应图,得到最优的目标定位结果。实验结果在各个测试集上都是目前最好。 |
|
创新点 |
ECO+对ECO的核心改进是: 两种特征区别对待,分而治之,深度特征负责鲁棒性,浅层特征负责准确性,两种检测响应图在最后阶段自适应融合,目标定位最优化,兼具两者的优势。 |
|
主要框架 |
对ECO的改进,相关滤波+深度特征 |
|
效果 |
精度: |
|
代码 |
没公布 |
七,Learning Spatial-Aware Regressions for Visual Tracking
八,Learning Attentions: Residual Attentional Siamese Network for High Performance Online Visual Tracking
|
论文名称 |
Learning Attentions: Residual Attentional Siamese Network for High Performance Online Visual Tracking |
|
简介 |
RASNet使用三个attention机制对SiamFC特征的空间和channel进行加权,分解特征提取和判别性分析的耦合,用来提升判别能力。 |
|
创新点 |
1.作者做的工作的本质就是让网络去预测对偶变量。 2.为了增加网络的判别能力,一个通用的attention似乎并不够。CF根据每个模板图像进行学习,得到很好的判别器。作者也模仿这个机制,根据第一帧图像的feature,使用网络学习一个动态的attention。 3.能让网络学习的就学习,尽量避免在线学习。 4.提出残差结构,希望残差学习的部分的均值近似为0。 |
|
主要框架 |
深度学习框架 |
|
效果 |
精度: |
|
代码 |
没公布 |
标签:view 就是 任务 权重 src 现象 操作 工作 1.5
原文地址:https://www.cnblogs.com/wanghuadongsharer/p/9503318.html