标签:info ice pie name concat html_ 脚本 code 读取数据
因为最近要买房子,然后对房市做了一些调研,发现套路极多。卖房子的顾问目前基本都是一派胡言能忽悠就忽悠,所以基本他们的话是不能信的。一个楼盘一次开盘基本上都是200-300套房子,数据量虽然不大,但是其实看一下也很烦要一页一页的翻,如果是在纸上的话,他们还不让你给带回去。所以就是在选一个价格楼层也合适的房子,基本上很不方便。但是幸运的是,合肥市的房子的所有的价格都在合肥是物价局上面公示出来了。所以这里考虑的就是先把房子的价格数据都给爬下来,然后分析房子的单价,总价来选个觉得最适合自己的房源。
这里涉及的技术点是这样
1. 发出post指令传入参数,获取url不变的分页网络信息
2. 解析网页的结构,用bs4去抓取自己需要的内容
3. 综合1,2两点编写完整的脚本代码,讲自己需要的房源的信息给爬取下来
4. pandas的对于dataframe的操作,选出适合自己的房子。
下面是操作步骤:
这里是我们要爬取的页面
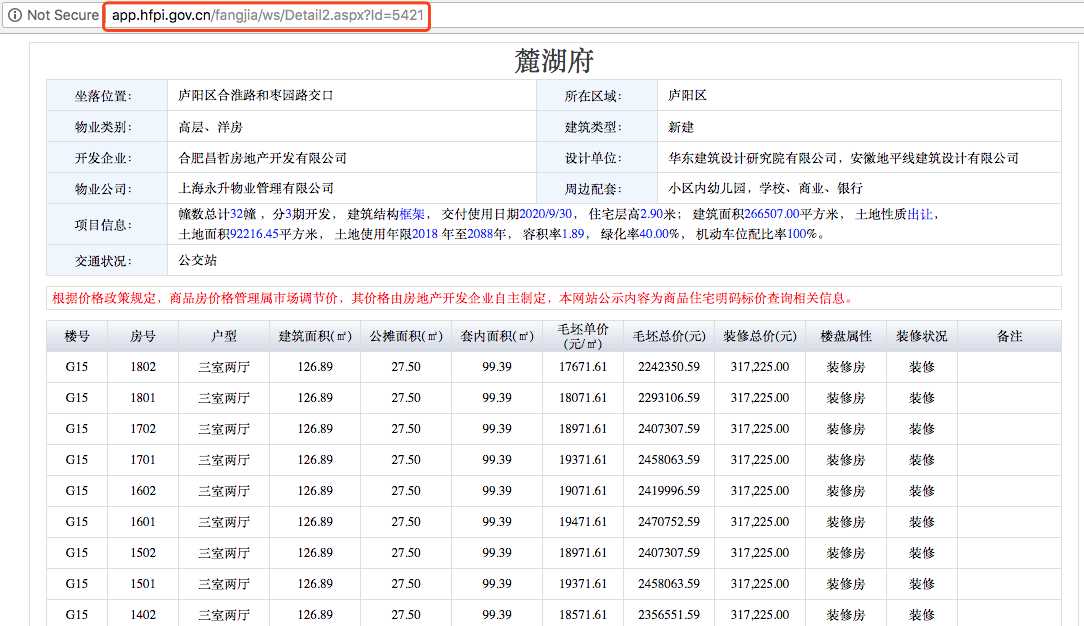
一共是15个分页,但是每个分页点进去的时候,url是没有变化的,也就是说我们没办法直接的通过更改url来访问页面。

打开Network,参数在这里,把他们用post请求发进去,就可以翻页了。
这时候我们需要找到我们需要爬取的数据的信息,看下网页的element,来定位到我们的数据信息
好像都在这里
那这个里面的子节点呢
大概是这个样子。
下面是我写的爬虫:
# import libraray import requests import os import pandas as pd import re from lxml import etree from bs4 import BeautifulSoup # source url url2 = "http://app.hfpi.gov.cn/fangjia/ws/Detail2.aspx?Id=5421" headers = {"User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36"} # 每次都更新下参数 def update_data_dict(soup): data_dict[‘__VIEWSTATE‘] = soup.find(id=‘__VIEWSTATE‘)[‘value‘] data_dict[‘__EVENTTARGET‘] = ‘AspNetPager1‘ data_dict[‘__EVENTARGUMENT‘] += 1 #保存下来爬取的当页的数据 def save_data(soup): x = soup(‘table‘,width=‘97%‘) xx = x[2] y = xx(‘tr‘) total = [] for item in y[1:-1]: content1 = item(‘td‘) empty = ‘‘ for i in content1: if i.find(‘div‘) == None: continue else: infopiece = i.find(‘div‘).text.strip() + ‘ ‘ empty += infopiece total.append(empty) with open(‘result0.txt‘,‘a‘) as f: for senc in total: f.write(senc + ‘\n‘) # 接着去下一页继续爬 def get_next_page_data(): html2 = requests.post(url, data=data_dict).text soup2 = BeautifulSoup(html2, ‘lxml‘) update_data_dict(soup2) save_data(soup2) ## 现在开始爬取 html_jsy = requests.get(url2).text soup_jsy = BeautifulSoup(html_jsy,‘lxml‘) save_data(soup_jsy) update_data_dict(soup_jsy) # 这里总页数我就设置20,如果后面没有了,也不会继续访问 for i in range(20): get_next_page_data_2()
那么我们看下我们爬取的结果

美滋滋,数据我们拿下来了。
接着我们要开始读取数据开始分析了
import pandas as pd df = pd.read_csv(‘result-jsy.txt‘, sep=‘ ‘,header=None) #change column name df.columns = [‘BuildingNo‘,‘RmNo‘,‘Type‘,‘Area‘,‘ShareArea‘,‘RealArea‘,‘Price‘,‘totalPrice‘,‘1‘,‘2‘,‘3‘,‘4‘] # 这次开盘只有16还有18, 先把16 18给选出来,然后合并 df_16 = df[df.BuildingNo ==‘G16‘] df_18 = df[df.BuildingNo == ‘G18‘] p_list = [df_16,df_18] df_temp = pd.concat(p_list)
因为这个楼盘有优惠,91折,所以单价我可以接受的范围我设置在14500
df_temp[df_temp.Price <= 14500.0]
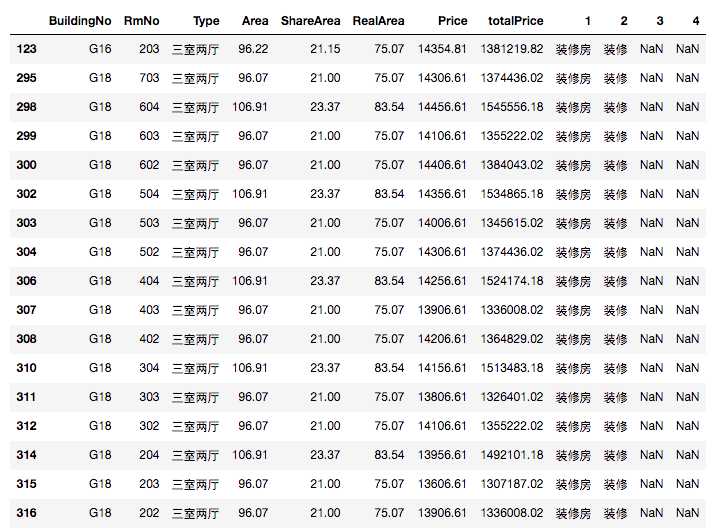
这里,我想住在5楼以上
df_select1[df_select1.RmNo > 500]
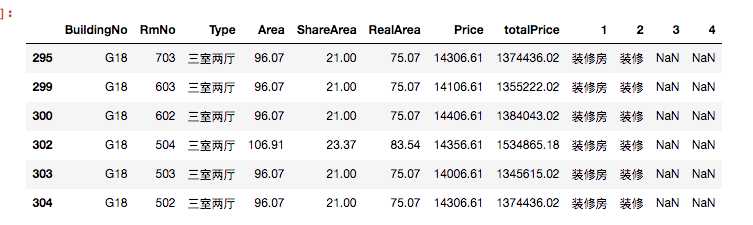
好吧,其实筛选就很简单了,这里因为明天就开盘了,所以首要就是看到价格然后楼层尽量高,
这里看,我的首选就是G18-703,但是上面其他的也都可以考虑。
BS4爬取物价局房产备案价以及dataframe的操作来获取房价的信息分析
标签:info ice pie name concat html_ 脚本 code 读取数据
原文地址:https://www.cnblogs.com/chenyusheng0803/p/9503430.html