标签:直接 http drive 网卡 class hdf image 自己的 cli
一、spark的三种提交模式
1、第一种,Spark内核架构,即standalone模式,基于Spark自己的Master-Worker集群。
2、第二种,基于YARN的yarn-cluster模式。
3、第三种,基于YARN的yarn-client模式。
如果,你要切换到第二种和第三种模式,在提交spark应用程序的spark-submit脚本加上--master参数,设置为yarn-cluster,或yarn-client,即可。如果没设置,那么,就是standalone模式。
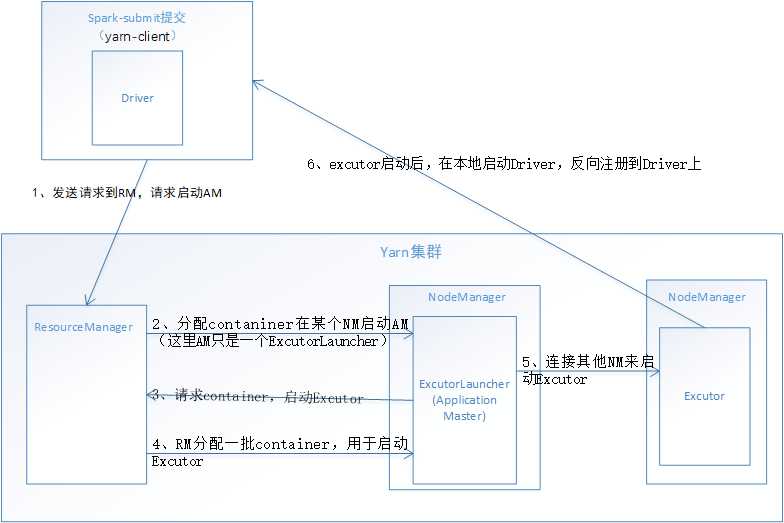
一、基于YARN的yarn-client模式
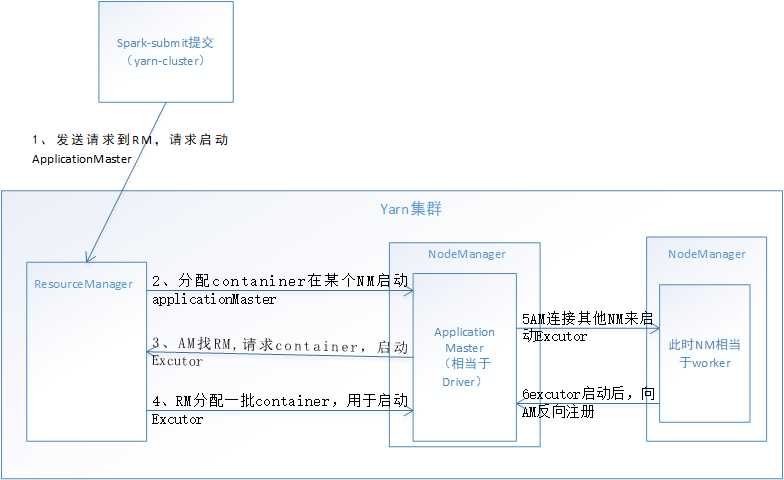
二、基于YARN的yarn-cluster模式
三、yarn-cluster和yarn-client区别
1, yarn-client用于测试,因为,driver运行在本地客户端,负责调度application ,会与yarn集群产生超大量的网络通信,从而导致网卡流星激增,可能会被SA (运维)给警告。优点是,直接执行时,本地可以看到所有的log,方便调试.
2, yarn-cluster ,用于生产环境,因为driver运行在nodemanager ,没有网卡流星激增的问题。缺点在于,调试不方便,本地用spark-submit堤交后,看不到log,只能通过yarn applicaition-logs application_id这种命令来查看,麻烦
如果spark不依托于yarn,或者就是搭建一个spark集群,底层基于hdfs、hive大数据操作,或者hadoop版本低,没有yarn,就用standalone模式即可,
建议,做成分布式,提交应用的机器做成分布式(多几台),在实际提交的时候能够负载均衡,在不同的机器上面去提交,避免单台机器网卡流量激增问题,
标签:直接 http drive 网卡 class hdf image 自己的 cli
原文地址:https://www.cnblogs.com/suwy/p/9510939.html