标签:html pytho spl 失败 open pen raise 分享 .text
1 京东商品页面爬取
import requests
url = ‘https://item.jd.com/7694047.html‘
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
print(r.text)
except:
print("Error")
2 亚马逊商品页面的爬取

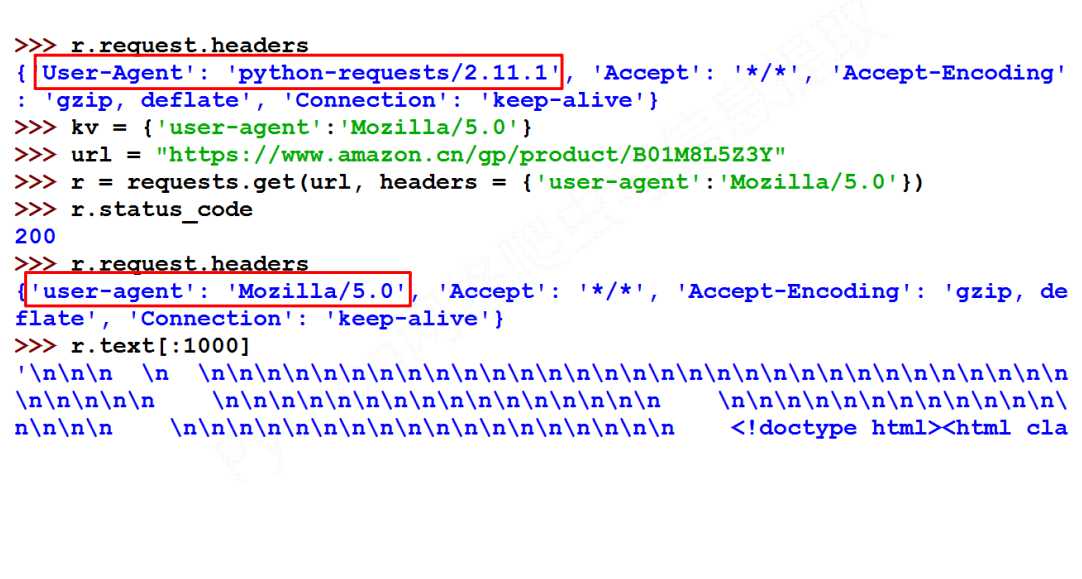
import requests
url = ‘https://www.amazon.cn/gp/product/B01M8L5Z3Y‘
try:
kv = {‘user-agent‘: "Mozilla/5.0"}
r = requests.get(url, timeout=30, headers=kv)#使用headers
r.raise_for_status()
r.encoding = r.apparent_encoding
print(r.text[1000:2000])
except:
print("Error")
3 百度/360搜索关键词提交
百度的关键词接口:
http://www.baidu.com/s?wd=keyword
360的关键词接口:
http://www.so.com/s?q=keyword
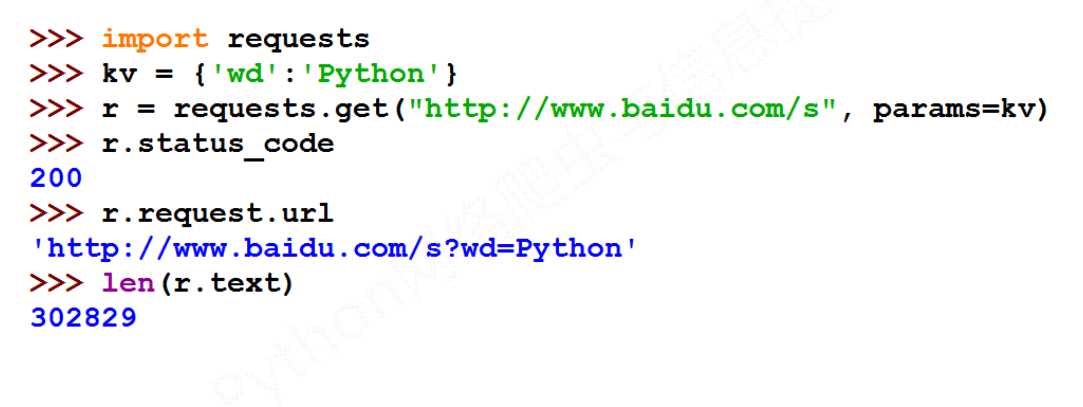
import requests
try:
kv = {‘wd‘: ‘Python‘}
r = requests.get(‘http://www.baidu.com/s‘, params=kv)
print(r.request.url)
r.raist_for_status()
print(len(r.text))
except:
print("爬取失败")
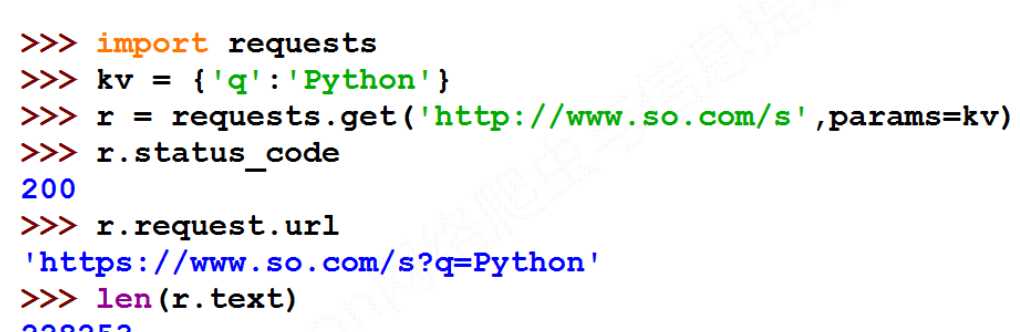
import requests
try:
kv = {‘q‘: "Python"}
r = requests.get(‘http://www.so.com/s‘, params=kv)
r.raise_for_status()
print(r.request.url)
print(len(r.text))
except:
print("爬取失败")
4 网络图片的爬取和储存
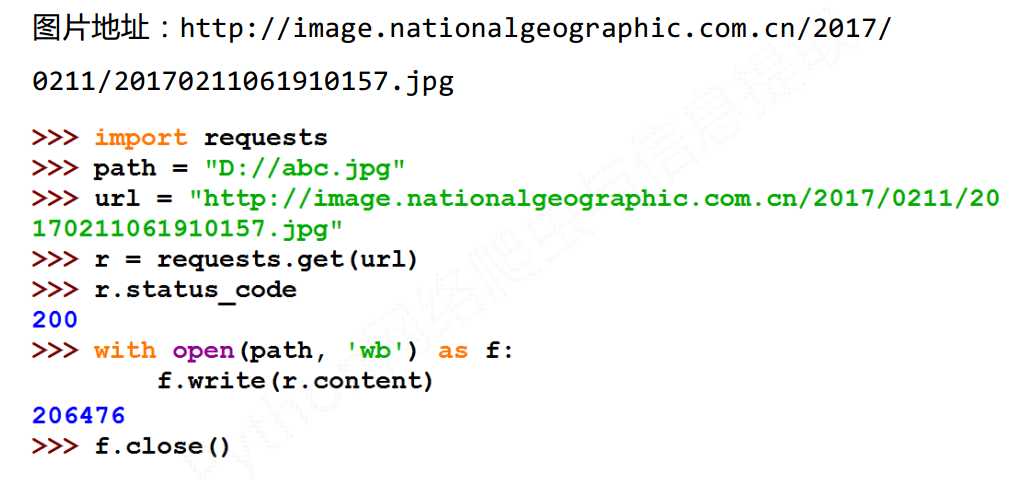
图片爬取全代码
import requests import os url = ‘http://image.nationalgeographic.com.cn/2017/0211/20170211061910157.jpg‘ root = "D://pics//" path = root + url.split(‘/‘)[-1] try: if not os.path.exists(root): os.makdir(root) if not os.path.exists(path): r = requests.get(path, ‘wb‘) with open(path, ‘wb‘) as f: f.write(r.content) f.close() print("文件保存成功") else: print("文件已存在") except: print("爬取失败")
4 IP归属地的自动查询
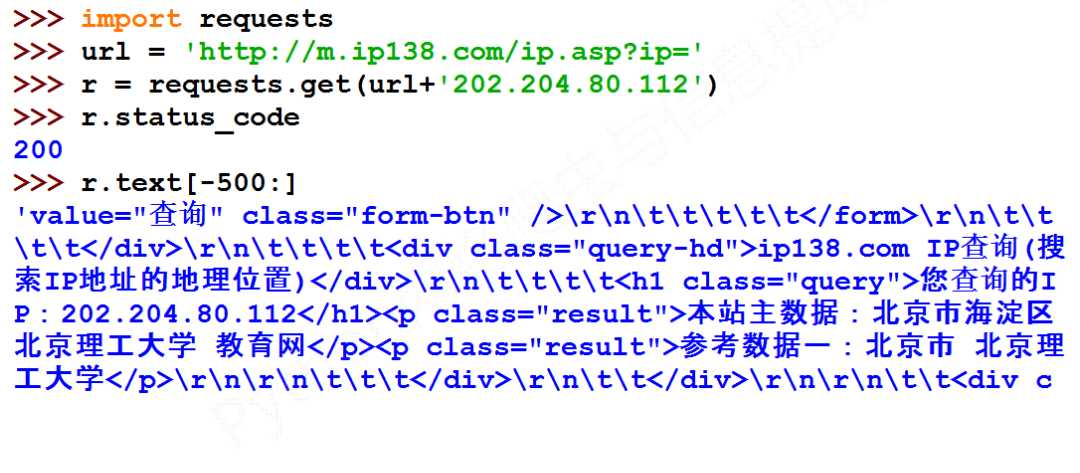
import requests
url = ‘http://m.ip138.com/ip.asp?ip=‘
try:
r = requests.get(url + ‘202.204.80.112‘)
r.raise_for_status
r.encoding = r.apparent_encoding
print(r.text[-500:])
except:
print("爬取失败")
标签:html pytho spl 失败 open pen raise 分享 .text
原文地址:https://www.cnblogs.com/key221/p/9513178.html