标签:页面 更新 man release keyword 重启tomcat 文件中 false logs
目录
复制IK解压目录中的jar包: IKAnalyzer2012FF_u1.jar. 可在 我的github 下载.
粘贴到tomcat/webapps/solr/WEB-INF/lib目录.
复制IK解压目录中的配置文件:
粘贴到tomcat/webapps/solr/WEB-INF/classes目录.
<!--加入使用ik分词器的域类型-->
<fieldType name="text_ik" class="solr.TextField">
<analyzer class="org.wltea.analyzer.lucene.IKAnalyzer" />
</fieldType><!--加入使用ik分词器的域-->
<field name="content_ik" type="text_ik"
indexed="false" stored="true" multiValued="true"/>
选择任意Core, 然后在菜单栏里选择[Analysis], 输入中文语句, 进行分词测试:
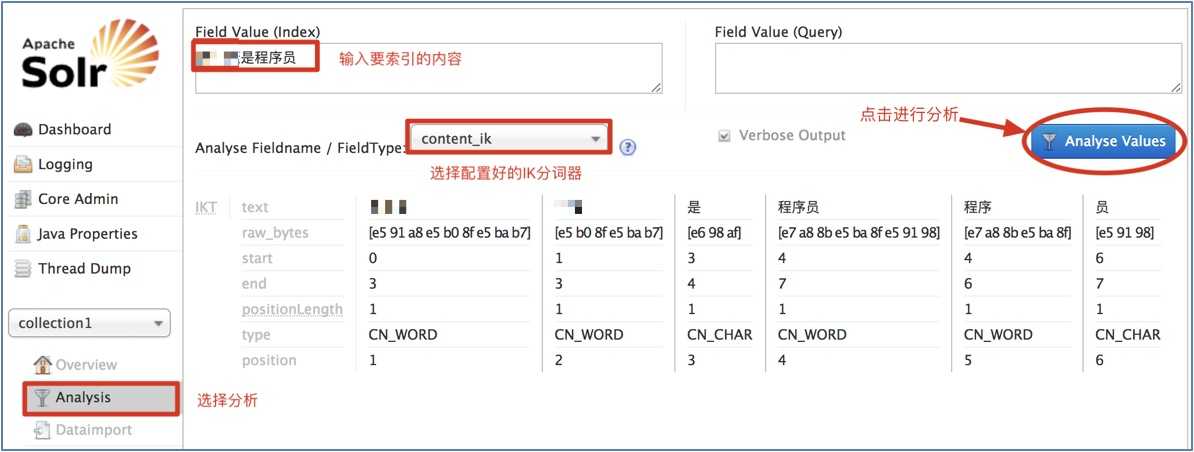
需求引入: 假设现在要使用Solr完成电商网站商品数据的搜索, 需要将保存在关系数据库中的商品数据导入到Solr索引库中.
DROP DATABASE IF EXISTS `solr`;
CREATE DATABASE `solr`;
USE `solr`;
SET FOREIGN_KEY_CHECKS=0;
DROP TABLE IF EXISTS `products`;
CREATE TABLE `products` (
`pid` int(11) NOT NULL AUTO_INCREMENT COMMENT '商品编号',
`name` varchar(255) DEFAULT NULL COMMENT '商品名称',
`catalog` int(11) DEFAULT NULL COMMENT '商品分类ID',
`catalog_name` varchar(50) DEFAULT NULL COMMENT '商品分类名称',
`price` double DEFAULT NULL COMMENT '价格',
`number` int(11) DEFAULT NULL COMMENT '数量',
`description` longtext COMMENT '商品描述',
`picture` varchar(255) DEFAULT NULL COMMENT '图片名称',
`release_time` datetime DEFAULT NULL COMMENT '上架时间',
PRIMARY KEY (`pid`)
) ENGINE=InnoDB AUTO_INCREMENT=6126 DEFAULT CHARSET=utf8;具体表数据可在 我的github 下载.
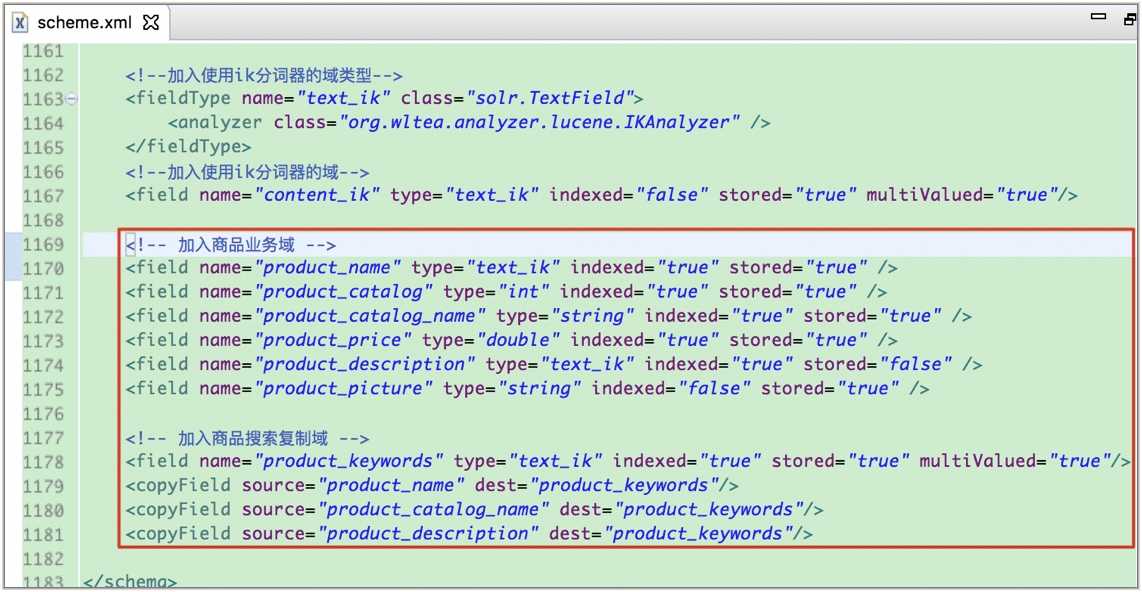
说明: 分析商品数据库表, 确定哪些字段需要在Solr中建立索引和存储.
字段: pid, name, catalog, catalog_name, price, description, picture
<field name="id" type="string" indexed="true" stored="true" required="true" multiValued="true"/> <field name="product_name" type="text_ik" indexed="true" stored="true" /> <field name="product_catalog" type="int" indexed="true" stored="true" /> <field name="product_catalog_name" type="string" indexed="true" stored="true" /> <field name="product_price" type="double" indexed="true" stored="true" /> <field name="product_description" type="text_ik" indexed="true" stored="false" /> <field name="product_picture" type="string" indexed="false" stored="true" /> <!-- 加入商品搜索复制域, 即将商品名、商品类型和描述都作为搜索关键词提供搜索 -->
<field name="product_keywords" type="text_ik" indexed="true" stored="true" multiValued="true"/>
<copyField source="product_name" dest="product_keywords"/>
<copyField source="product_catalog_name" dest="product_keywords"/>
<copyField source="product_description" dest="product_keywords"/>注意: 这里id使用Solr默认的id域(一定要有主键, 没有则需要将默认的id域删除, 也可更改id生成策略. 尝试过未在库中设置主键而此文件中的id域未删除也未重写, 此时可以建立索引, 却无法检索到结果(⊙﹏⊙)):
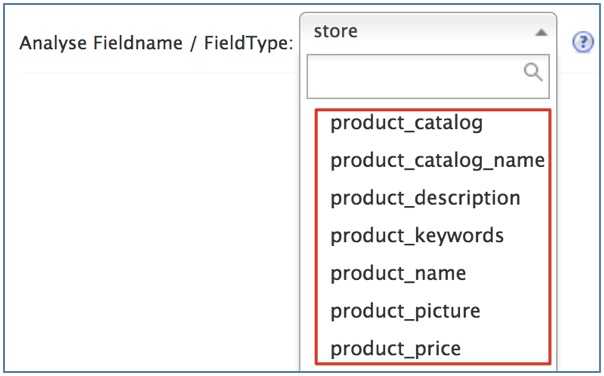
选中任意一个core, 选择Analysis, 在Fieldname / FieldType处查看, 观察配置是否成功:
复制Solr解压后dist目录中的: solr-dataimporthandler-4.10.4.jar;
粘贴到contrib/dataimporthandler/lib(lib文件夹需要手动创建):
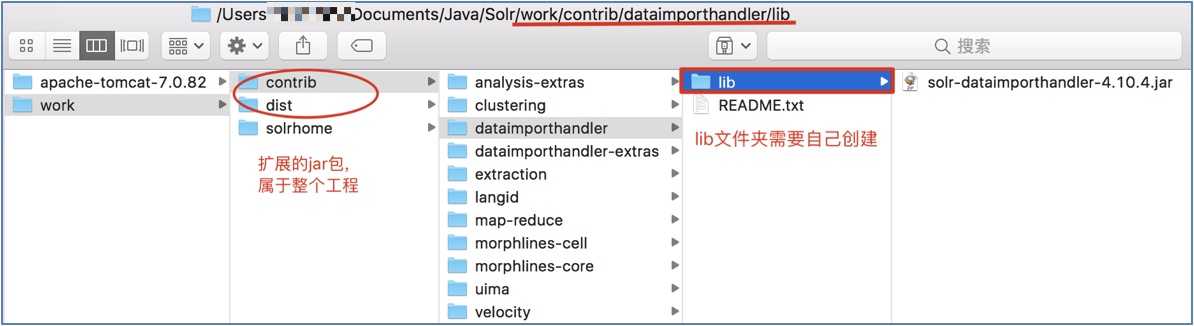
复制所用数据库服务器的相应jar包;
粘贴到contrib/db/lib(db/lib需要手动创建):
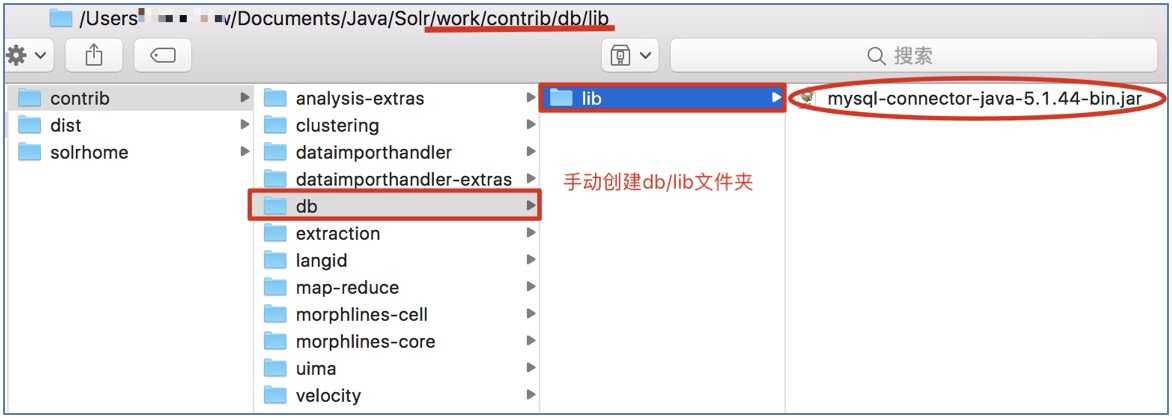
注意: 这里使用的MySQL服务器版本为5.7.20, 故导入5.1.44版本的jar包 -- 其他较低版本的jar包可能会出现一些不可预知的Bug.
在SolrCore(即collection1)中找到solrconfig.xml文件.
<!-- 配置加入数据导入、数据库驱动的jar包 -->
<lib dir="${solr.install.dir:../..}/contrib/dataimporthandler/lib" regex=".*\.jar"/>
<lib dir="${solr.install.dir:../..}/contrib/db/lib" regex=".*\.jar"/>Solr的数据索引分两种: 全量导入(full-import)和增量导入(delta-import), 顾名思义, 全量导入就是一次性全部导入所有数据, 而增量导入就是当数据库中的数据有更新时再作导入处理.
使用dataimport就需要在solrconfig.xml中添加DIH配置信息:
<!-- 加入数据导入的请求处理器 -->
<requestHandler name="/dataimport" class="org.apache.solr.handler.dataimport.DataImportHandler">
<lst name="defaults">
<str name="config">data-config.xml</str>
</lst>
</requestHandler>注意: 这里field的column属性是对应数据库中的字段, 而name属性的值必须与scheme.xml中新配置的field的name属性的值一致, 否则无法解析.
<?xml version="1.0" encoding="UTF-8" ?>
<dataConfig>
<!-- 数据源配置 -->
<dataSource type="JdbcDataSource"
driver="com.mysql.jdbc.Driver"
url="jdbc:mysql://127.0.0.1:3306/solr?useSSL=true"
user="ur_login_name"
password="ur_pwd"/>
<document>
<!-- 配置sql语句执行结果, 与商品业务域的对应关系 -->
<entity name="product" pk="pid"
query="SELECT pid, name, catalog, catalog_name, price, description, picture
FROM products">
<field column="pid" name="id"/>
<field column="name" name="product_name"/>
<field column="catalog" name="product_catalog"/>
<field column="catalog_name" name="product_catalog_name"/>
<field column="price" name="product_price"/>
<field column="description" name="product_description"/>
<field column="picture" name="product_picture"/>
</entity>
</document>
</dataConfig>参数说明:
- dataSource: 定义了数据的位置, 对于数据库, 则是DSN(Data Source Name, 即数据源名称, 数据库服务器的主机名、端口和数据库名、用户、密码); 对于HTTP数据源, 则是基本的URL.
- entity: 实体会被处理生成包含多个字段的文档的集合, 会被发送给Solr进行索引. 对于RDBMS数据源, 一个实体是一个视图或表, 可能被一至多个SQL语句处理来生成一系列具有一或多个列(字段)的行(文档).
- processor: 一个实体处理器会完成整个从数据源抽取内容、转换并将其添加到索引的工作, 可用自定义实体处理器扩展或替换默认提供的处理器.
- transformer: 从实体中取得的每个字段的集都可以选择进行转换, 此过程可修改字段、创建新字段或从单个行生成多个行. 可通过公用接口自定义转换器.
<entity name="product" pk="pid"
query="SELECT * FROM products"
deltaImportQuery="SELECT * FROM products where pid='${dih.delta.id}'"
deltaQuery="SELECT pid FROM products where last_modified > '${dih.last_index_time}'" >
<field />
<!-- ...... -->
</entity>${dih.delta.id}来获取需要增量导入的数据的主键(之前使用的是${dataimporter.delta.ID}), 使用${dih.last_index_time}来获取dataimport.properties文件中last_index_time的属性值(之前使用的是${dataimporter.last_index_time}).重启Tomcat, 在菜单栏的[Dataimport]查看配置的Entity是否生效. 也可通过菜单栏的[Files]查看配置文件.
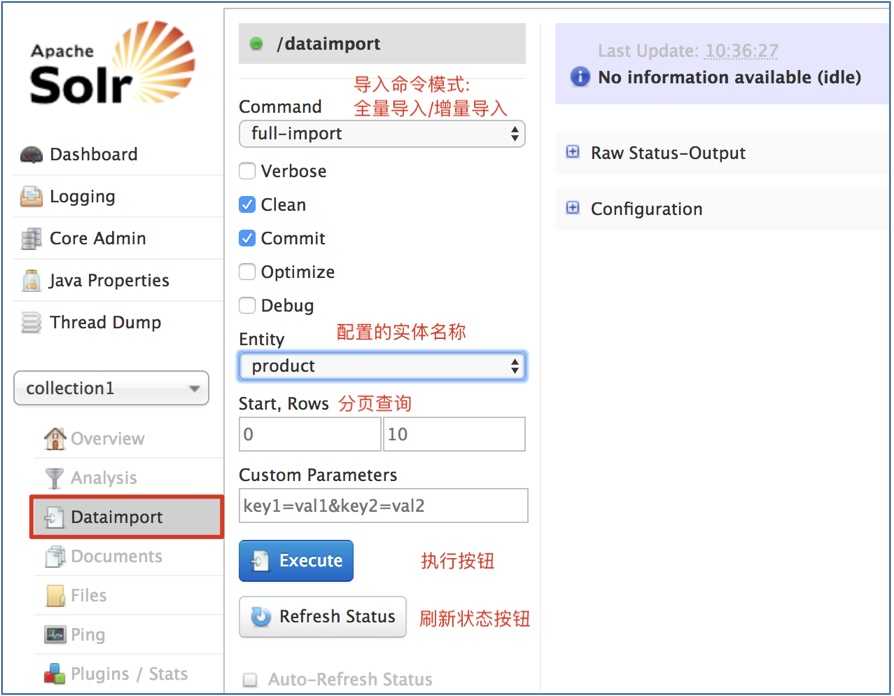
通过Solr管理界面的Dataimport方式导入:
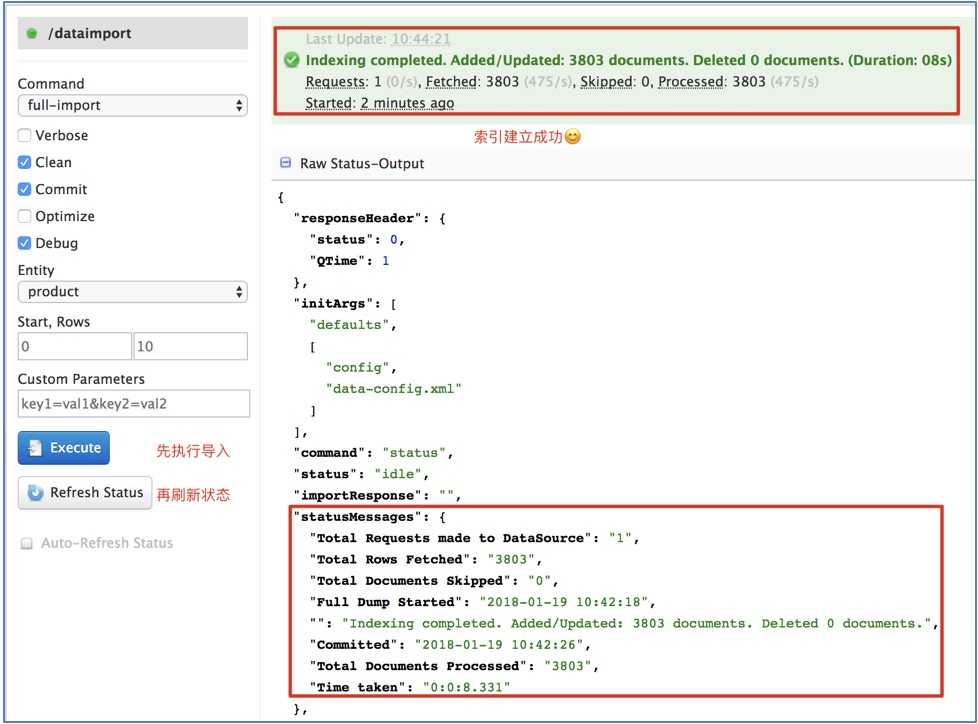
注意: 由于Solr管理界面的不稳定性, 索引状态的显示可能会消失, 可通过查看Dashboard中JVM-Memory的波动程度, 确定是否处于索引状态.
也可通过HTTP请求的方式导入, HTTP请求URL格式为:
http://ip:port/[web-dir]/CoreName/dataimport?command=command[¶ms], 其中参数params有:
| 参数 | 描述 |
|---|---|
| clean | 默认为true, 表示是否在建立下一次索引前清除原有索引(慎用) |
| commit | 默认为true, 表示是否在操作完成后提交 |
| debug | 默认为false, 表示是否以Debug模式运行. 此默认的commit默认为false. |
| entity | 用已指定操作的entity, 只能指定DIH配置文件中 |
| optimize | 默认为true, 表示在操作之后是否optimize(优化索引). |
示例:
1) 如果执行全量导入, 导入前清除索引, 导入后提交结果, 则发送如下URL请求:
http://ip:port/[webdir/]CoreName/dataimport?command=full-import&clean=true&commit=true
2) 如果执行增量导入, 导入前不清除索引, 导入后提交结果, 则发送如下URL请求:
http://ip:port/[webdir/]CoreName/dataimport?command=delta-import&clean=false&commit=true
版权声明
作者: ma_shoufeng(马瘦风)
出处: 博客园 马瘦风的博客
您的支持是对博主的极大鼓励, 感谢您的阅读.
本文版权归博主所有, 欢迎转载, 但未经博主同意必须保留此段声明, 且在文章页面明显位置给出原文链接, 否则博主保留追究法律责任的权利.
标签:页面 更新 man release keyword 重启tomcat 文件中 false logs
原文地址:https://www.cnblogs.com/shoufeng/p/9513674.html