标签:html oba element odi 执行 应用 cal 取数据 https
一. Selenium和PhantomJS介绍
Selenium是一个用于Web应用程序测试的工具,Selenium直接运行在浏览器中,就像真正的用户在操作一样。由于这个性质,Selenium也是一个强大的网络数据采集工具,其可以让浏览器自动加载页面,这样,使用了异步加载技术的网页,也可获取其需要的数据。
Selenium模块是Python的第三方库,可以通过pip进行安装:
|
pip3 install selenium |
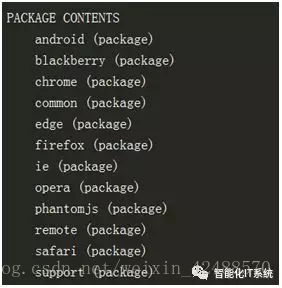
Selenium自己不带浏览器,需要配合第三方浏览器来使用。通过help命令查看Selenium的Webdriver功能,查看Webdriver支持的浏览器:
|
from selenium import webdriver help(webdriver) |
查看执行后的结果,如下图所示:
在这个案例中,采用PhantomJS。Selenium和PhantomJS的配合使用可以完全模拟用户在浏览器上的所有操作,包括输入框内容填写、单击、截屏、下滑等各种操作。这样,对于需要登录的网站,用户可以不需要通过构造表单或提交cookie信息来登录网站。
二. 案例介绍
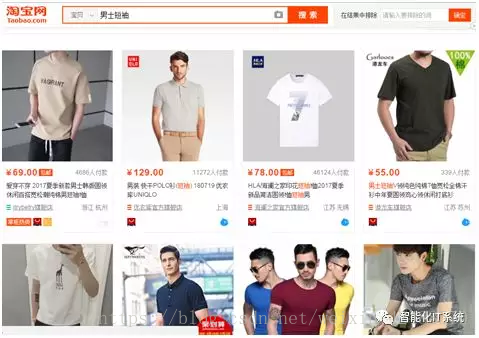
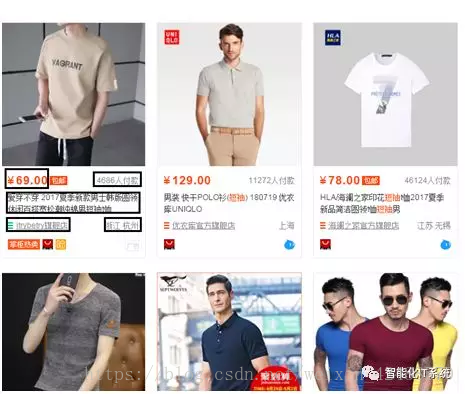
这里所举的案例,是利用Selenium爬取淘宝商品信息,爬取的内容为淘宝网(https://www.taobao.com/)上男士短袖的商品信息,如下图所示:
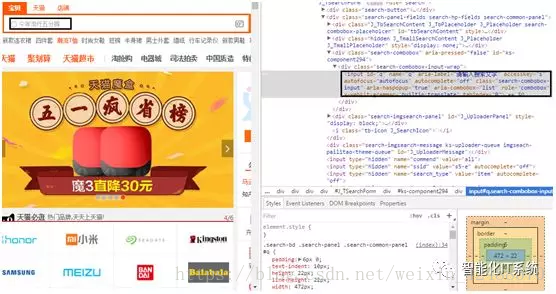
这里可以看到,在用户输入淘宝后,需要模拟输入,在输入框输入“男士短袖”。
案例中使用Selenium和PhantomJS,模拟电脑的搜索操作,输入商品名称进行搜索,如图所示,“检查”搜索框元素。
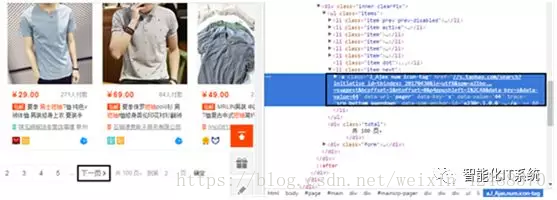
并且如下图所示,“检查”下一页元素:
爬取的内容有商品价格、付款人数、商品名称、商家名称和地址,如下图所示:
最后把爬取数据存储到MongoDB数据库中。
三. 相关技术
这里把除了selenium之外所需要的知识列一下,这里就不做详细解释了,如果不清楚的话可以百度了解下。
mongoDB的使用,以及在python中用mongodb进行数据存储。
lxml,爬虫三大方法之一,解析效率比较高,使用难度相比正则表达式要低(上一篇文章的解析方法是正则表达式)。
间歇休息的方法:driver.implicitly_wait
四. 源代码
代码如下所示,可复制直接执行:
from selenium import webdriver from lxml import etree import time import pymongo client = pymongo.MongoClient(‘localhost‘, 27017) mydb = client[‘mydb‘] taobao = mydb[‘taobao‘] driver = webdriver.PhantomJS() driver.maximize_window() def get_info(url,page): page = page + 1 driver.get(url) driver.implicitly_wait(10) selector = etree.HTML(driver.page_source) infos = selector.xpath(‘//div[@class="item J_MouserOnverReq"]‘) for info in infos: data = info.xpath(‘div/div/a‘)[0] goods = data.xpath(‘string(.)‘).strip() price = info.xpath(‘div/div/div/strong/text()‘)[0] sell = info.xpath(‘div/div/div[@class="deal-cnt"]/text()‘)[0] shop = info.xpath(‘div[2]/div[3]/div[1]/a/span[2]/text()‘)[0] address = info.xpath(‘div[2]/div[3]/div[2]/text()‘)[0] commodity = { ‘good‘:goods, ‘price‘:price, ‘sell‘:sell, ‘shop‘:shop, ‘address‘:address } taobao.insert_one(commodity) if page <= 50: NextPage(url,page) else: pass def NextPage(url,page): driver.get(url) driver.implicitly_wait(10) driver.find_element_by_xpath(‘//a[@trace="srp_bottom_pagedown"]‘).click() time.sleep(4) driver.get(driver.current_url) driver.implicitly_wait(10) get_info(driver.current_url,page) if __name__ == ‘__main__‘: page = 1 url = ‘https://www.taobao.com/‘ driver.get(url) driver.implicitly_wait(10) driver.find_element_by_id(‘q‘).clear() driver.find_element_by_id(‘q‘).send_keys(‘男士短袖‘) driver.find_element_by_class_name(‘btn-search‘).click() get_info(driver.current_url,page)
五. 代码解析
(1)1~4行
导入程序需要的库,selenium库用于模拟请求和交互。lxml解析数据。pymongo是mongoDB 的交互库。
(2)6~8行
打开mongoDB,进行存储准备。
(3)10~11行
最大化PhantomJS窗口。
(4)14~33行
利用lxml抓取网页数据,分别定位到所需要的信息,并把信息集成至json,存储至mongoDB。
(5)35~47行
分页处理。
(5)51~57行
利用selenium模拟输入“男士短袖”,并模拟点击操作,并获取到对应的页面信息,调取主方法解析。
———————————————————
公众号-智能化IT系统。每周都有技术文章推送,包括原创技术干货,以及技术工作的心得分享。扫描下方关注。
标签:html oba element odi 执行 应用 cal 取数据 https
原文地址:https://www.cnblogs.com/xtary/p/9517728.html