标签:lob 排除 localhost RKE word actor cost bre orm
说完了ES的索引与检索,接着再介绍一个ES高级功能API – 聚合(Aggregations),聚合功能为ES注入了统计分析的血统,使用户在面对大数据提取统计指标时变得游刃有余。同样的工作,你在Hadoop中可能需要写mapreduce或Hive,在mongo中你必须得用大段的mapreduce脚本,而在ES中仅仅调用一个API就能实现了。
开始之前,提醒老司机们注意,ES原有的聚合功能Facets在新版本中将被正式被移除,抓紧时间用Aggregations替换Facets吧。Facets真的很慢!
Aggregations的部分特性类似于SQL语言中的group by,avg,sum等函数。但Aggregations API还提供了更加复杂的统计分析接口。
掌握Aggregations需要理解两个概念:
对照一条SQL来加深我们的理解:
SELECT COUNT(color) FROM table GROUP BY color
GROUP BY相当于做分桶的工作,COUNT是统计指标。
下面介绍一些常用的Aggregations API。
2.1 AVG
2.2 Cardinality
2.3 Stats
2.4 Extended Stats
2.5 Percentiles
2.6 Percentile Ranks
3.1 Filter
3.2 Range
3.3 Missing
3.4 Terms
3.5 Date Range
3.6 Global Aggregation
3.7 Histogram
3.8 Date Histogram
3.9 IPv4 range
3.10 Return only aggregation results
ES中经常使用到的聚合结果集可以被缓存起来,以便更快速的系统响应。这些缓存的结果集和你掠过缓存直接查询的结果是一样的。因为,第一次聚合的条件与结果缓存起来后,ES会判断你后续使用的聚合条件,如果聚合条件不变,并且检索的数据块未增更新,ES会自动返回缓存的结果。
注意聚合结果的缓存只针对size=0的请求(参考3.10章节),还有在聚合请求中使用了动态参数的比如Date Range中的now(参考3.5章节),ES同样不会缓存结果,因为聚合条件是动态的,即使缓存了结果也没用了。
先加入几条index数据,如下:

curl -XPUT ‘localhost:9200/testindex/orders/2?pretty‘ -d ‘{
"zone_id": "1",
"user_id": "100008",
"try_deliver_times": 102,
"trade_status": "TRADE_FINISHED",
"trade_no": "xiaomi.21142736250938334726",
"trade_currency": "CNY",
"total_fee": 100,
"status": "paid",
"sdk_user_id": "69272363",
"sdk": "xiaomi",
"price": 1,
"platform": "android",
"paid_channel": "unknown",
"paid_at": 1427370289,
"market": "unknown",
"location": "local",
"last_try_deliver_at": 1427856948,
"is_guest": 0,
"id": "fa6044d2fddb15681ea2637335f3ae6b7f8e76fef53bd805108a032cb3eb54cd",
"goods_name": "一小堆元宝",
"goods_id": "ID_001",
"goods_count": "1",
"expires_in": 2592000,
"delivered_at": 0,
"debug_mode": true,
"created_at": 1427362509,
"cp_result": "exception encountered",
"cp_order_id": "cp.order.id.test",
"client_id": "9c98152c6b42c7cb3f41b53f18a0d868",
"app_user_id": "fvu100006"
}‘
Sum求和,dsl参考如下:
[sfapp@cmos1 ekfile]$ curl ‘http://10.202.11.117:9200/testindex/orders/_search?pretty‘ -d ‘
> {
> "size": 0,
> "aggs": {
> "return_expires_in": {
> "sum": {
> "field": "expires_in"
> }
> }
> }
> }‘
{
"took" : 3,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"failed" : 0
},
"hits" : {
"total" : 2,
"max_score" : 0.0,
"hits" : [ ]
},
"aggregations" : {
"return_expires_in" : {
"value" : 5184000.0
}
}
}
[sfapp@cmos1 ekfile]$
返回expires_in之和,其中size=0 表示不需要返回参与查询的文档。
Min求最小值
[sfapp@cmos1 ekfile]$ curl ‘http://10.202.11.117:9200/testindex/orders/_search?pretty‘ -d ‘
> {
> "size": 0,
> "aggs": {
> "return_min_expires_in": {
> "min": {
> "field": "expires_in"
> }
> }
> }
> }‘
{
"took" : 3,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"failed" : 0
},
"hits" : {
"total" : 2,
"max_score" : 0.0,
"hits" : [ ]
},
"aggregations" : {
"return_min_expires_in" : {
"value" : 2592000.0
}
}
}
[sfapp@cmos1 ekfile]$
Max求最大值
[sfapp@cmos1 ekfile]$ curl ‘http://10.202.11.117:9200/testindex/orders/_search?pretty‘ -d ‘
> {
> "size": 0,
> "aggs": {
> "return_max_expires_in": {
> "max": {
> "field": "expires_in"
> }
> }
> }
> }‘
{
"took" : 3,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"failed" : 0
},
"hits" : {
"total" : 2,
"max_score" : 0.0,
"hits" : [ ]
},
"aggregations" : {
"return_max_expires_in" : {
"value" : 2592000.0
}
}
}
[sfapp@cmos1 ekfile]$
AVG求平均值
[sfapp@cmos1 ekfile]$ curl ‘http://10.202.11.117:9200/testindex/orders/_search?pretty‘ -d ‘
> {
> "size": 0,
> "aggs": {
> "return_avg_expires_in": {
> "avg": {
> "field": "expires_in"
> }
> }
> }
> }‘
{
"took" : 4,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"failed" : 0
},
"hits" : {
"total" : 2,
"max_score" : 0.0,
"hits" : [ ]
},
"aggregations" : {
"return_avg_expires_in" : {
"value" : 2592000.0
}
}
}
[sfapp@cmos1 ekfile]$
{
"size": 0,
"aggs": {
"return_cardinality": {
"cardinality": {
"field": "gender"
}
}
}
}
结果为:
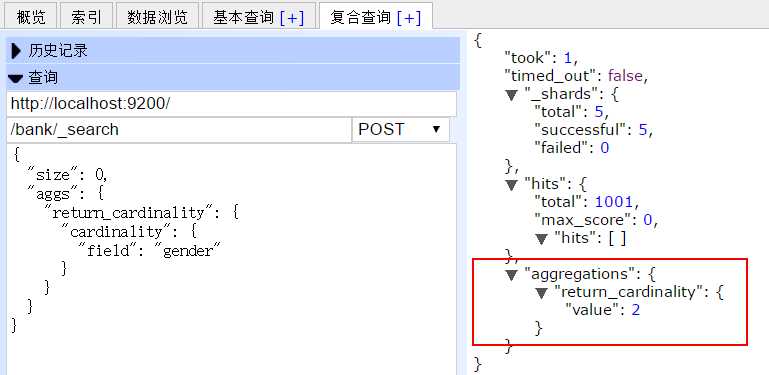
查看官方文档时候,没看懂,下面是自己测试时的例子,按照性别(F,M)查看工资范围的百分比
{
"size": 0,
"aggs": {
"states": {
"terms": {
"field": "gender"
},
"aggs": {
"banlances": {
"percentile_ranks": {
"field": "balance",
"values": [
20000,
40000
]
}
}
}
}
}
结果:
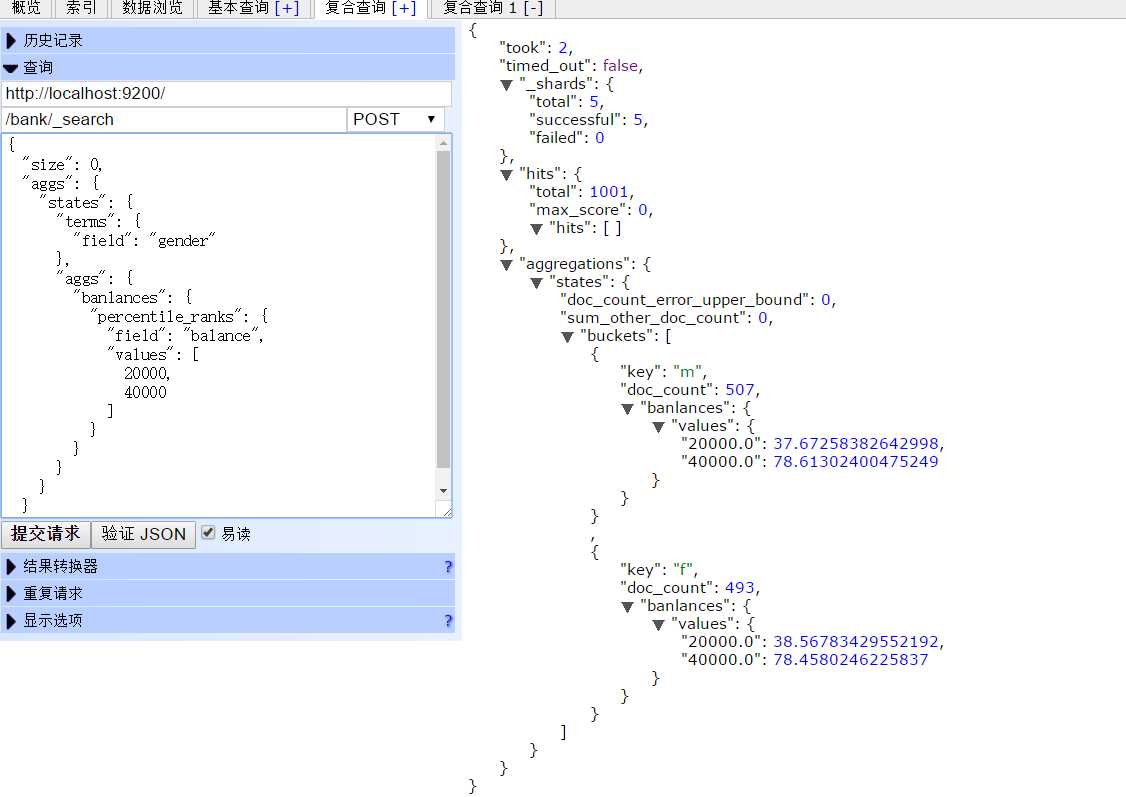
查看balance的统计情况:
{
"size": 0,
"aggs": {
"balance_stats": {
"stats": {
"field": "balance"
}
}
}
}
返回结果:
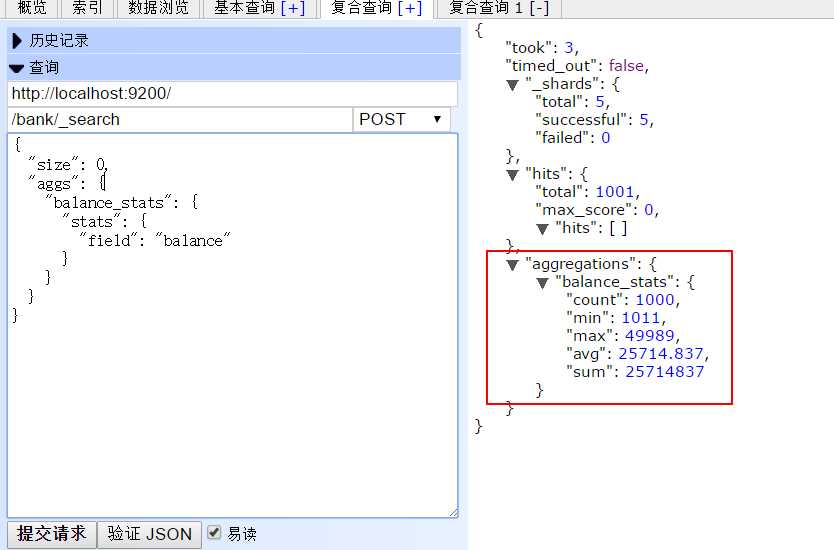
{
"size": 0,
"aggs": {
"balance_stats": {
"extended_stats": {
"field": "balance"
}
}
}
}
结果:
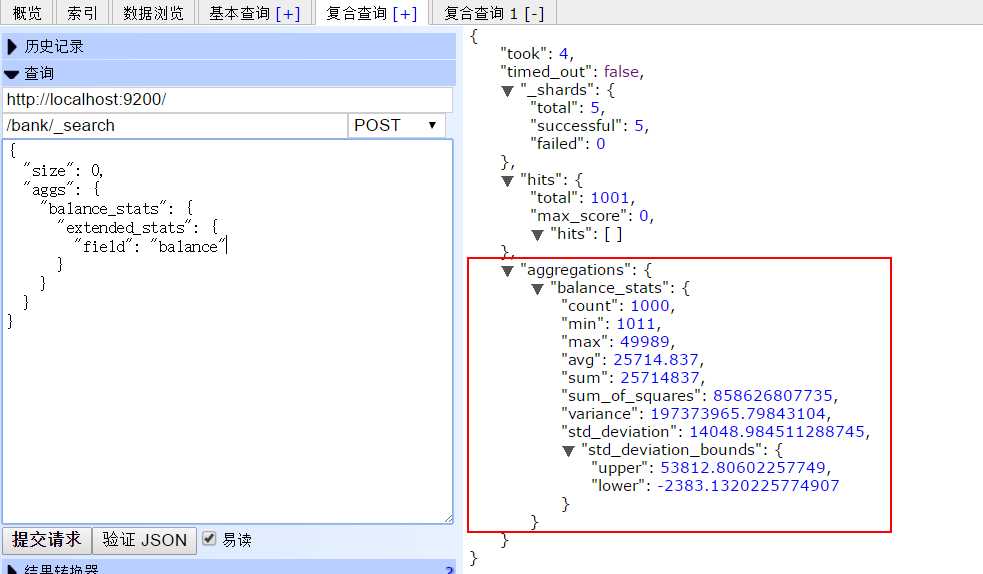
更加复杂的查询,后续慢慢在实践中道来。
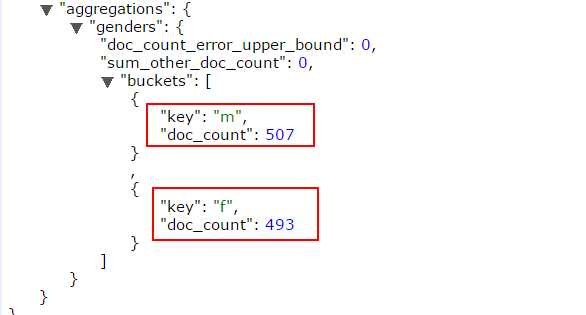
记录有多少F,多少M
返回结果如下:m记录507条,f记录493条
使用terms聚合,结果可能带有一定的偏差与错误性。
比如:
我们想要获取name字段中出现频率最高的前5个。
此时,客户端向ES发送聚合请求,主节点接收到请求后,会向每个独立的分片发送该请求。
分片独立的计算自己分片上的前5个name,然后返回。当所有的分片结果都返回后,在主节点进行结果的合并,再求出频率最高的前5个,返回给客户端。
这样就会造成一定的误差,比如最后返回的前5个中,有一个叫A的,有50个文档;B有49。 但是由于每个分片独立的保存信息,信息的分布也是不确定的。 有可能第一个分片中B的信息有2个,但是没有排到前5,所以没有在最后合并的结果中出现。 这就导致B的总数少计算了2,本来可能排到第一位,却排到了A的后面。
为了改善上面的问题,就可以使用size和shard_size参数。
通过这两个参数,如果我们想要返回前5个,size=5;shard_size可以设置大于5,这样每个分片返回的词条信息就会增多,相应的误差几率也会减小。
order指定了最后返回结果的排序方式,默认是按照doc_count排序。
{
"aggs" : {
"genders" : {
"terms" : {
"field" : "gender",
"order" : { "_count" : "asc" }
}
}
}
}
也可以按照字典方式排序:
{
"aggs" : {
"genders" : {
"terms" : {
"field" : "gender",
"order" : { "_term" : "asc" }
}
}
}
}
当然也可以通过order指定一个单值聚合,来排序。
{
"aggs" : {
"genders" : {
"terms" : {
"field" : "gender",
"order" : { "avg_balance" : "desc" }
},
"aggs" : {
"avg_balance" : { "avg" : { "field" : "balance" } }
}
}
}
}
同时也支持多值聚合,不过要指定使用的多值字段:
{
"aggs" : {
"genders" : {
"terms" : {
"field" : "gender",
"order" : { "balance_stats.avg" : "desc" }
},
"aggs" : {
"balance_stats" : { "stats" : { "field" : "balance" } }
}
}
}
}
返回结果:

聚合的字段可能存在一些频率很低的词条,如果这些词条数目比例很大,那么就会造成很多不必要的计算。
因此可以通过设置min_doc_count和shard_min_doc_count来规定最小的文档数目,只有满足这个参数要求的个数的词条才会被记录返回。
桶聚合也支持脚本的使用:
{
"aggs" : {
"genders" : {
"terms" : {
"script" : "doc[‘gender‘].value"
}
}
}
}
以及外部脚本文件:
{
"aggs" : {
"genders" : {
"terms" : {
"script" : {
"file": "my_script",
"params": {
"field": "gender"
}
}
}
}
}
}
filter字段提供了过滤的功能,使用两种方式:include可以匹配出包含该值的文档,exclude则排除包含该值的文档。
例如:
{
"aggs" : {
"tags" : {
"terms" : {
"field" : "tags",
"include" : ".*sport.*",
"exclude" : "water_.*"
}
}
}
}
上面的例子中,最后的结果应该包含sport并且不包含water。
也支持数组的方式,定义包含与排除的信息:
{
"aggs" : {
"JapaneseCars" : {
"terms" : {
"field" : "make",
"include" : ["mazda", "honda"]
}
},
"ActiveCarManufacturers" : {
"terms" : {
"field" : "make",
"exclude" : ["rover", "jensen"]
}
}
}
}
通常情况,terms聚合都是仅针对于一个字段的聚合。因为该聚合是需要把词条放入一个哈希表中,如果多个字段就会造成n^2的内存消耗。
不过,对于多字段,ES也提供了下面两种方式:
对于子聚合的计算,有两种方式:
默认情况下ES会使用深度优先,不过可以手动设置成广度优先,比如:
{
"aggs" : {
"actors" : {
"terms" : {
"field" : "actors",
"size" : 10,
"collect_mode" : "breadth_first"
},
"aggs" : {
"costars" : {
"terms" : {
"field" : "actors",
"size" : 5
}
}
}
}
}
}
缺省值指定了缺省的字段的处理方式:
{
"aggs" : {
"tags" : {
"terms" : {
"field" : "tags",
"missing": "N/A"
}
}
}
}标签:lob 排除 localhost RKE word actor cost bre orm
原文地址:https://www.cnblogs.com/-flq/p/9519806.html