标签:字段 发送 5.0 ike turn scrapy win store show
ImagesPipeline是scrapy自带的类,用来处理图片(爬取时将图片下载到本地)用的。
image_urls字段Spider返回的Item,传递到Item PipelineItem传递到ImagePipeline,将调用Scrapy 调度器和下载器完成image_urls中的url的调度和下载。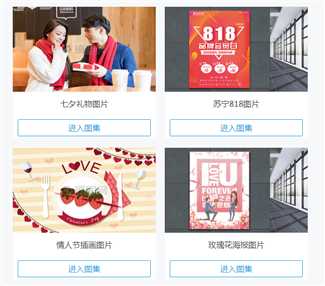
这里使用方法一进行实现:
步骤一:建立项目与爬虫
1.创建工程:scrapy startproject xxx(工程名)
2.创建爬虫:进去到上一步创建的目录下:scrapy genspider xxx(爬虫名) xxx(域名)
步骤二:创建start.py
1 from scrapy import cmdline 2 3 cmdline.execute("scrapy crawl 699pic(爬虫名)".split(" "))
步骤三:设置settings
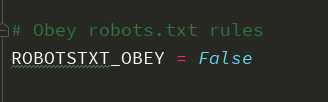
1.关闭机器人协议,改成False
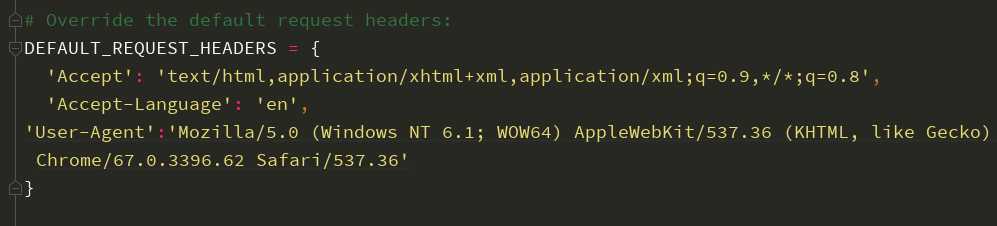
2.设置headers
3.打开ITEM_PIPELINES
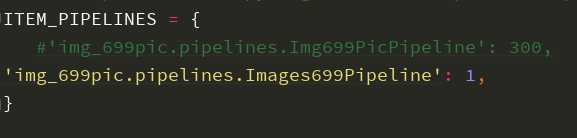
将项目自动生成的pipelines注释掉,黄色部分是下面步骤中自己写的pipeline,这里先不写。
步骤四:item
1 class Img699PicItem(scrapy.Item): 2 # 分类的标题 3 category=scrapy.Field() 4 # 存放图片地址 5 image_urls=scrapy.Field() 6 # 下载成功后返回有关images的一些相关信息 7 images=scrapy.Field()
步骤五:写spider
import scrapy from ..items import Img699PicItem import requests from lxml import etree class A699picSpider(scrapy.Spider): name = ‘699pic‘ allowed_domains = [‘699pic.com‘] start_urls = [‘http://699pic.com/image/1/‘] headers={ ‘User-Agent‘:‘Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.62 Safari/537.36‘ } def parse(self, response): divs=response.xpath("//div[@class=‘special-list clearfix‘]/div")[0:4] for div in divs: category=div.xpath("./a[@class=‘special-list-title‘]//text()").get().strip() url=div.xpath("./a[@class=‘special-list-title‘]/@href").get().strip() image_urls=self.parse_url(url) item=Img699PicItem(category=category,image_urls=image_urls) yield item def parse_url(self,url): response=requests.get(url=url,headers=self.headers) htmlElement=etree.HTML(response.text) image_urls=htmlElement.xpath("//div[@class=‘imgshow clearfix‘]//div[@class=‘list‘]/a/img/@src") return image_urls
步骤六:pipelines
import os from scrapy.pipelines.images import ImagesPipeline from . import settings class Img699PicPipeline(object): def process_item(self, item, spider): return item class Images699Pipeline(ImagesPipeline): def get_media_requests(self, item, info): # 这个方法是在发送下载请求之前调用的,其实这个方法本身就是去发送下载请求的 request_objs=super(Images699Pipeline, self).get_media_requests(item,info) for request_obj in request_objs: request_obj.item=item return request_objs def file_path(self, request, response=None, info=None): # 这个方法是在图片将要被存储的时候调用,来获取这个图片存储的路径 path=super(Images699Pipeline, self).file_path(request,response,info) category=request.item.get(‘category‘) image_store=settings.IMAGES_STORE category_path=os.path.join(image_store,category) if not os.path.exists(category_path): os.makedirs(category_path) image_name=path.replace("full/","") image_path=os.path.join(category_path,image_name) return image_path
步骤七:返回到settings中
1.将黄色部分填上

2.存放图片的总路径
IMAGES_STORE=os.path.join(os.path.dirname(os.path.dirname(__file__)),‘images‘)
使用Scrapy自带的ImagesPipeline下载图片,并对其进行分类。
标签:字段 发送 5.0 ike turn scrapy win store show
原文地址:https://www.cnblogs.com/Kctrina/p/9523553.html