标签:空格 span 回收 不成功 back val 文件夹 ogr book
本篇内容是Redis最简单最容易掌握的知识,如果你已经熟知了,就可以选择跳过啦!
要体验Redis,那么首先你得安装Redis,这边的话我就只讲一下Windows环境下的安装与操作:
下载地址:https://github.com/MSOpenTech/redis/releases。
Redis 支持 32 位和 64 位。这个需要根据你系统平台的实际情况选择,这里我们下载 Redis-x64-xxx.zip压缩包到 C 盘,解压后,将文件夹重新命名为 redis。
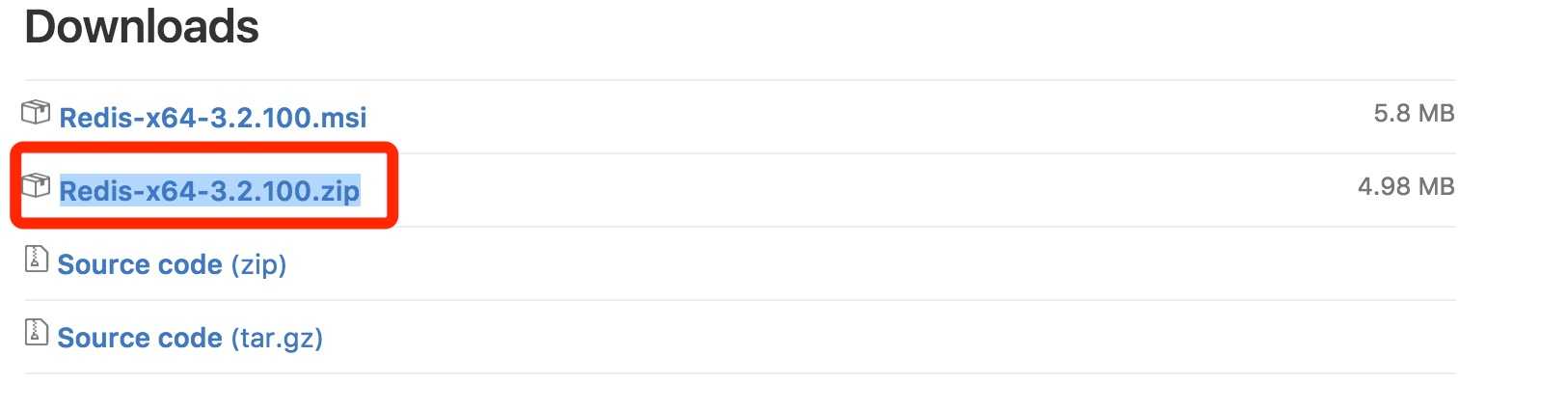
打开一个 cmd 窗口 使用cd命令切换目录到 C:\redis 运行 redis-server.exe redis.windows.conf 。
如果想方便的话,可以把 redis 的路径加到系统的环境变量里,这样就省得再输路径了,后面的那个 redis.windows.conf 可以省略,如果省略,会启用默认的。输入之后,会显示如下界面:
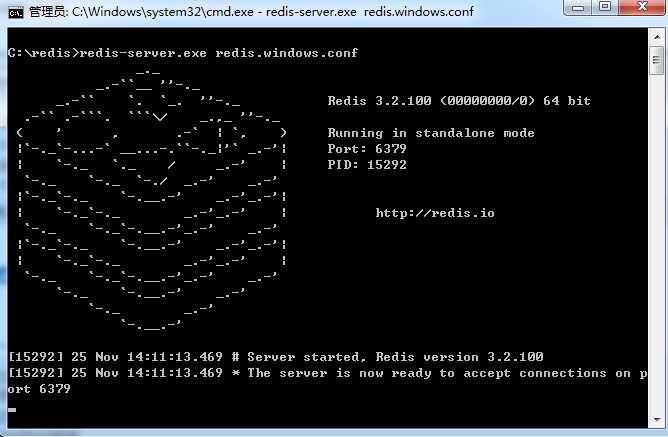
这时候另启一个cmd窗口,原来的不要关闭,不然就无法访问服务端了。
切换到redis目录下运行 redis-cli.exe -h 127.0.0.1 -p 6379 。
设置键值对 set myKey abc
取出键值对 get myKey
到这里,安装就结束啦!同样的Linux和Mac环境下的同学们可以在菜鸟教程上找到自己需要的,我就不搬砖了!
Redis常见的数据结构一共有五种,分别是:string(字符串)、List(列表)、set(集合)、zset(有序集合)、hash(哈希)
这五种基本数据结构需要我们熟练掌握!在Redis中,所有的数据结构都是以唯一的Key字符串作为名称,然后通过这个唯一Key值来获取相应的value数据。不同类型的数据结构的差异就在于value的结构不一样。
字符串string是Redis最简单的数据结构。
字符串结构的使用非常广泛,常见的用途就是缓存用户信息,我们将用户信息结构体使用JSON序列化成字符串,然后将序列化后的字符串塞进Redis来缓存,当我们取得用户信息时会经过一次反序列化的过程。
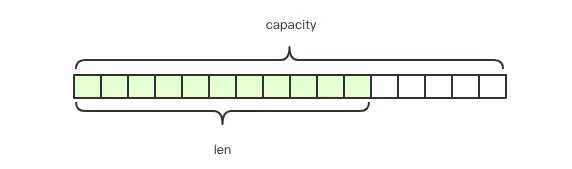
Redis的字符串是动态字符串,也就是说可修改的字符串,结构上类似于Java中的ArrayList,采用了预分配冗余空间的方式减少内存的频繁分配。上图中,字符串实际分配的空间capacity一般是>字符串的长度len的。在Redis中,字符串的长度小于1M时,扩容都是加倍现有的空间,如果超过了1M,那么扩容则只会增加1M的空间。而字符串的最大长度为512M。
> set name codehole //设置指定key的值 OK > get name //获取指定key "codehole" > exists name (integer) 1 > del name (integer) 1 > get name (nil)
> set name1 codehole OK > set name2 holycoder OK > mget name1 name2 name3 # 返回一个列表 1) "codehole" 2) "holycoder" 3) (nil) > mset name1 boy name2 girl name3 unknown > mget name1 name2 name3 1) "boy" 2) "girl" 3) "unknown"...
我们可以对key设置过期时间,到点自动删除,一般我们通过这个功能来控制缓存的失效时间。
> set name c1 OK > get name "c1" > expire name 5 //设置五秒后过期 (integer) 1 //.....等待五秒 > get name (nil) > setex name 5 c1 //5s 后过期,等价于 set+expire > get name "c1" //.....等待五秒 > get name (nil) > setnx name c1 // 如果 name 不存在就执行 set 创建 (integer) 1 > get name "c1" > setnx name c2 (integer) 0 // 因为 name 已经存在,所以 set 创建不成功 > get name "c1" // 没有改变...
如果value值是一个整数,还可以对他进行自增操作。自增是有范围的,它的范围是 signend long 的最大最小值,超过了这个值,Redis会报错。
> set age 30 OK > incr age //通过incr命令将key中存储的数值增一,如果key不存在,key的值会被先初始化为0,然后再进行INCR操作 (integer) 31 > incrby age 5 //通过incrby命令将key中存储的数值加上指定的增加量,如果key不存在,key的值会被先初始化为0,然后再进行INCR操作 (integer) 36 > incrby age -5 (integer) 31 > set c1 9223372036854775807 // Long.Max OK > incr c1 (error) ERR increment or decrement would overflow...
字符串由多个字节(Byte)组成,每个字节由8个bit组成,我们可以讲一个字符串看成很多bit的组合,这就是bitmap(位图)的数据结构。
Redis的list列表相当于Java中的LinkedList,它是链表而不是数组,意味着增删快而检索查询慢。
当 list 弹出了最后一个元素后,该数据结构会被自动删除,内存被回收。
Redis的 list 结构通常用来做异步队列使用。将需要延后处理的任务结构体序列化成字符串塞进 list 列表,另一个线程从这个列表中轮询数据进行处理。
> rpush book java (integer) 1 > rpush book python (integer) 2 > rpush book golong (integer) 3// 将一个或多个值 value 插入到列表 key 的表尾(最右边) // 也可写为
// > rpush books python java golang > llen book//返回列表的长度 (integer) 3 > lpop book "java" > lpop book "python" > lpop book//移除列表左侧的头元素 "golong"
> rpush book python java golang (integer) 3 > rpop book "golang" > rpop book "java" > rpop book "python" > rpop book (nil)...
lindex 相当于Java链表的 get(int index) 方法,他需要对链表进行遍历,性能随链表长度的增大而变差。
redis> LPUSH mylist "World" (integer) 1 redis> LPUSH mylist "Hello" (integer) 2 redis> LINDEX mylist 0 "Hello" redis> LINDEX mylist -1 "World" redis> LINDEX mylist 3 //index不在 mylist 的区间范围内 (nil)
Ltrim 和跟着的两个参数start_index和end_index定义了一个区间,在这个区间内的值,ltrim要保留,区间之外统统砍掉。我们可以通过ltrim来实现一个定长的链表。(其实就是裁剪)
index可以为负数,index=-1表示倒数第一个元素,同样index=-2表示倒数第二个元素。
Lrange 则是返回指定区间的元素。
> RPUSH mylist "hello" (integer) 1 > RPUSH mylist "hello" (integer) 2 > RPUSH mylist "foo" (integer) 3 > RPUSH mylist "bar" (integer) 4 > LTRIM mylist 1 -1 OK > LRANGE mylist 0 -1 1) "hello" 2) "foo" 3) "bar"
Redis的底层存储还不是一个简单的linkedList,而是称之为快速链表 quicklis的一个结构。

在列表元素较少的情况下会使用一块连续的内存存储,这个结构是ziplist即压缩列表。
它将所有的元素紧挨着一起存储,分配的是一块连续的内存。当数据较多的时候会改成quicklist。因为普通的链表需要的附加指针空间太大,会浪费空间,同时会加重内存的碎片化。
例如,一个列表中存储的只是 int 类型的数据,结构上还需要两个额外的指针prev和next。所以Redis将链表和ziplist结合起来组成了quicklist。也就是将多个ziplist使用双向指针穿起来使用。这样既满足了快速的插入删除性能,又不会出现太大的空间冗余。
Redis的hash相当于Java中的HashMap,是无序的。内部结构上也和HashMap是一致的,同样是数组+链表的结构。
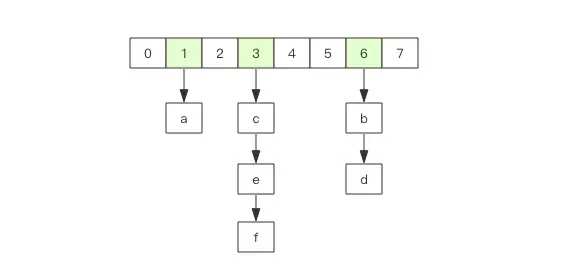
但是和HashMap不一样的是,Redis中的hash的值只能是字符串,另外他们的rehash的方式不一样,因为Java的HashMap在散列表很大时,rehash时一个耗时的操作,需要一次性全部rehash。而Redis为了高性能,不能堵塞服务,所以采取了渐进式rehash策略。
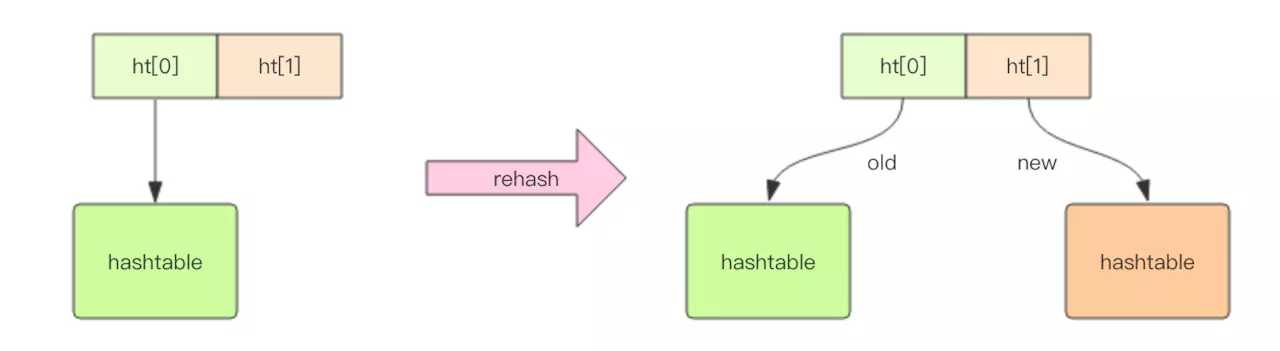
渐进式rehash会在rehash的同时,保留新旧两个hash结构,查询时会同时查询两个hash结构,然后在后续的定时任务中以及hash操作指令中,循序渐进的将旧hash的内容一点一点的迁移到新的hash结构中。当迁移完成了,就会用新的hash结构取而代之。
再简单一点讲,就是Redis在做扩容时,拷贝节点数据的过程全部平摊到后续的操作中,而不是一次性拷贝,而我们想要实现这样的平摊,就必须对节点进行操作,例如再次插入,查找,修改,删除时都会进行拷贝。
当hash移除了最后一个元素之后,该数据结构就会被自动删除,内存被回收。
hash结构也可以用来存储用户信息,不同于字符串一次性要全部序列化整个对象,hash可以对用户结构中的每个字段单独存储。这样我们需要获取用户信息时就可以进行部分获取。而用整个字符串的形式去保存用户信息的话,就只能一次性全部获取,比较浪费网络流量。
当然,hash也是有缺点的,hash的存储结构消耗要高于单个字符串,使用hash或者字符串时,需要根据实际的情况再三权衡。
> hset books java "think in java" //命令行的字符串如果包含空格,要用引号括起来。。。hset 字典名 键 值 (integer) 1 > hset books golang "concurrency in go" (integer) 1 > hset books python "python cookbook" (integer) 1 > hgetall books //entries(),key 和 value 间隔出现 1) "java" 2) "think in java" 3) "golang" 4) "concurrency in go" 5) "python" 6) "python cookbook" > hlen books (integer) 3 > hget books java "think in java" > hset books golang "learning go programming" //因为是更新操作,所以返回 0 (integer) 0 > hget books golang "learning go programming" > hmset books java "effective java" python "learning python" golang "modern golang programming" // 批量 set OK...
同字符串一样,hash结构中单个子key也可以计数,对应的指令 hincrby ,和incr基本一样。
HSET myhash field 5 (integer) 1 HINCRBY myhash field 1 (integer) 6 HINCRBY myhash field -1 (integer) 5 HINCRBY myhash field -10 (integer) -5
Redis的集合相当于Java中的HashSet,它内部的键值对时无序且唯一的。
当集合中最后一个元素移除之后,数据结构自动删除,内存被回收。
Set结构可以存储某些特殊场景的数据,比如活动中奖用户的ID,可以保证用一个用户不会中奖两次。
> sadd books python (integer) 1 > sadd books python # 重复 (integer) 0 > sadd books java golang (integer) 2 > smembers books // 注意顺序,和插入的并不一致,因为 set 是无序的 1) "java" 2) "python" 3) "golang" > sismember books java // 查询某个 value 是否存在,相当于 contains(o) (integer) 1 > sismember books rust (integer) 0 > scard books // 获取长度相当于 count() (integer) 3 > spop books // 弹出一个 "java"...
zset是Redis提供的最为特色的数据结构。可以把它想象成HashMap和SortedSet的结合体,一方面它是一个set,保证了内部value值得唯一性,另一方面它可以给每一个value都赋予一个score,代表这个value的排序权重,也就是说根据这个score的分数来排序。
zset中最后一个value被移除后,数据结构会自动删除,内存会被回收。
下面是一些常用的命令
> zadd books 9.0 "think in java" (integer) 1 > zadd books 8.9 "java concurrency" (integer) 1 > zadd books 8.6 "java cookbook" (integer) 1 > zrange books 0 -1 // 按 score 排序列出,0表示第一个成员,-1表示倒数第一个成员 1) "java cookbook" 2) "java concurrency" 3) "think in java" > zrevrange books 0 -1 // 按 score 逆序列出,参数区间为排名范围 1) "think in java" 2) "java concurrency" 3) "java cookbook" > zcard books // 统计这个列表中元素的个数 (integer) 3 > zscore books "java concurrency" // 获取指定 value 的 score "8.9000000000000004" // 内部 score 使用 double 类型进行存储,所以存在小数点精度问题 > zrank books "java concurrency" // 排名 (integer) 1 > zrangebyscore books 0 8.91 //根据分值区间遍历 zset 1) "java cookbook" 2) "java concurrency" > zrangebyscore books -inf 8.91 withscores // 根据分值区间 (-∞, 8.91] 遍历 zset,同时返回分值。inf 代表 infinite,无穷大的意思。 1) "java cookbook" 2) "8.5999999999999996" 3) "java concurrency" 4) "8.9000000000000004" > zrem books "java concurrency" // 删除 value (integer) 1 > zrange books 0 -1 1) "java cookbook" 2) "think in java"...
zset的内部排序是通过【跳跃列表】的数据结构实现的,这种数据结构比较复杂,也很特殊。
因为zset要支持随机的插入和删除,所以不好用数组来表示。这个我们到后面再具体探讨跳跃列表
list/set/hash/zset 这四种数据结构是容器型的数据结构,有如下两条通用规则:
1、create if not exists
如果容器不存在,那就创建一个,再进行操作。
2、drop if no elements
如果容器里的元素没有了,那么立刻删除容器,释放内存。
Redis 所有的数据结构都可以设置过期时间,时间到了,Redis会自动删除相应的对象。需要注意的是过期是一对象为单位,比如一个hash结构的过期是整个hash对象的过期,而不是其中的某个键值。
还有一个需要注意的是如果一个字符已经设置了过期时间,但是你调用了set方法修改他,它的过期时间就会消失。
Redis 之(二) Redis的基本数据结构以及一些常用的操作
标签:空格 span 回收 不成功 back val 文件夹 ogr book
原文地址:https://www.cnblogs.com/Fuxking4wesome/p/9511495.html