标签:提示 stat crawl tree src int pid wow 技术
写在前面的话 :上一篇文章我们用requests和lxml.etree爬取了豆瓣电影Top250的电影信息,为了能对requests和lxml.etree有更深的理解,下面我们将继续用他们来爬取豆瓣电影的短评
温馨提示 :博主使用的系统为win10,使用的python版本为3.6.5
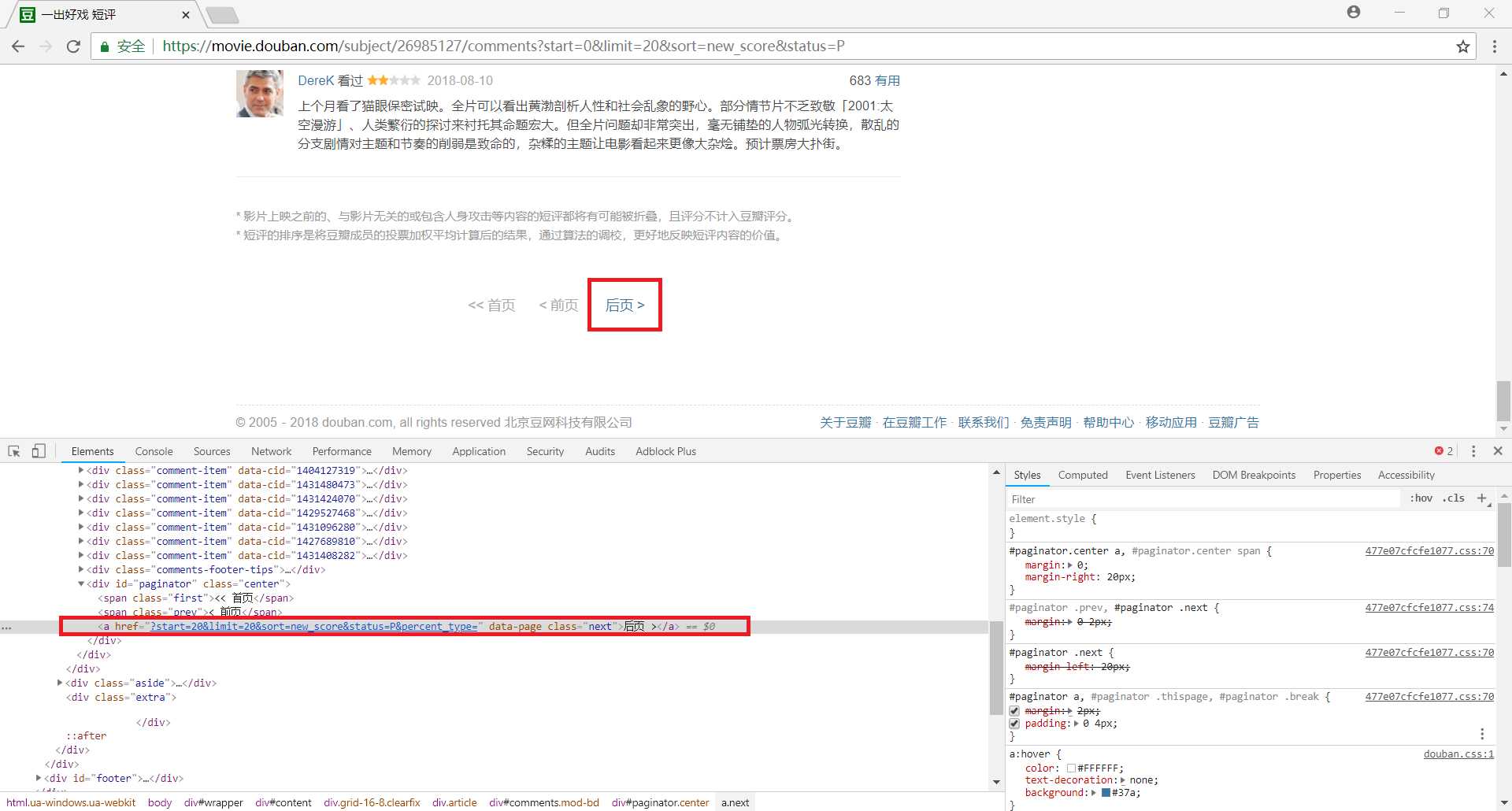
首先我们使用chrome浏览器打开某一部电影的评论(这里示例为最近很火的《一出好戏》),我们首先可以判断该网站是一个静态网页,和之前一样我们可以通过构造URL来获取全部网页的内容,但是这次我们尝试使用一种新方法——翻页
使用快捷键 Ctrl+Shift+I 打开Chrome浏览器自带的开发者工具,然后可以使用快捷键 Ctrl+Shift+C 来打开元素选择工具,用鼠标点击网页中的 后页,就会在源代码中自动定位到相应位置,用lxml.etree匹配下一页的链接为 html.xpath(‘//div[@id="paginator"]/a[@class="next"]/@href‘),这样我们就可以通过循环不断获取下一页的内容了
接下来我们需要解析每一页网页的内容以获取我们需要的数据,包括:评论者、赞同人数、评价和评论内容,这里我们使用lxml.etree进行匹配
//div[@class="comment-item"]/div[2]/h3/span[1]/span/text()//div[@class="comment-item"]/div[2]/h3/span[2]/a/text()//div[@class="comment-item"]/div[2]/h3/span[2]/span[2]/@title//div[@class="comment-item"]/div[2]/p/span/text()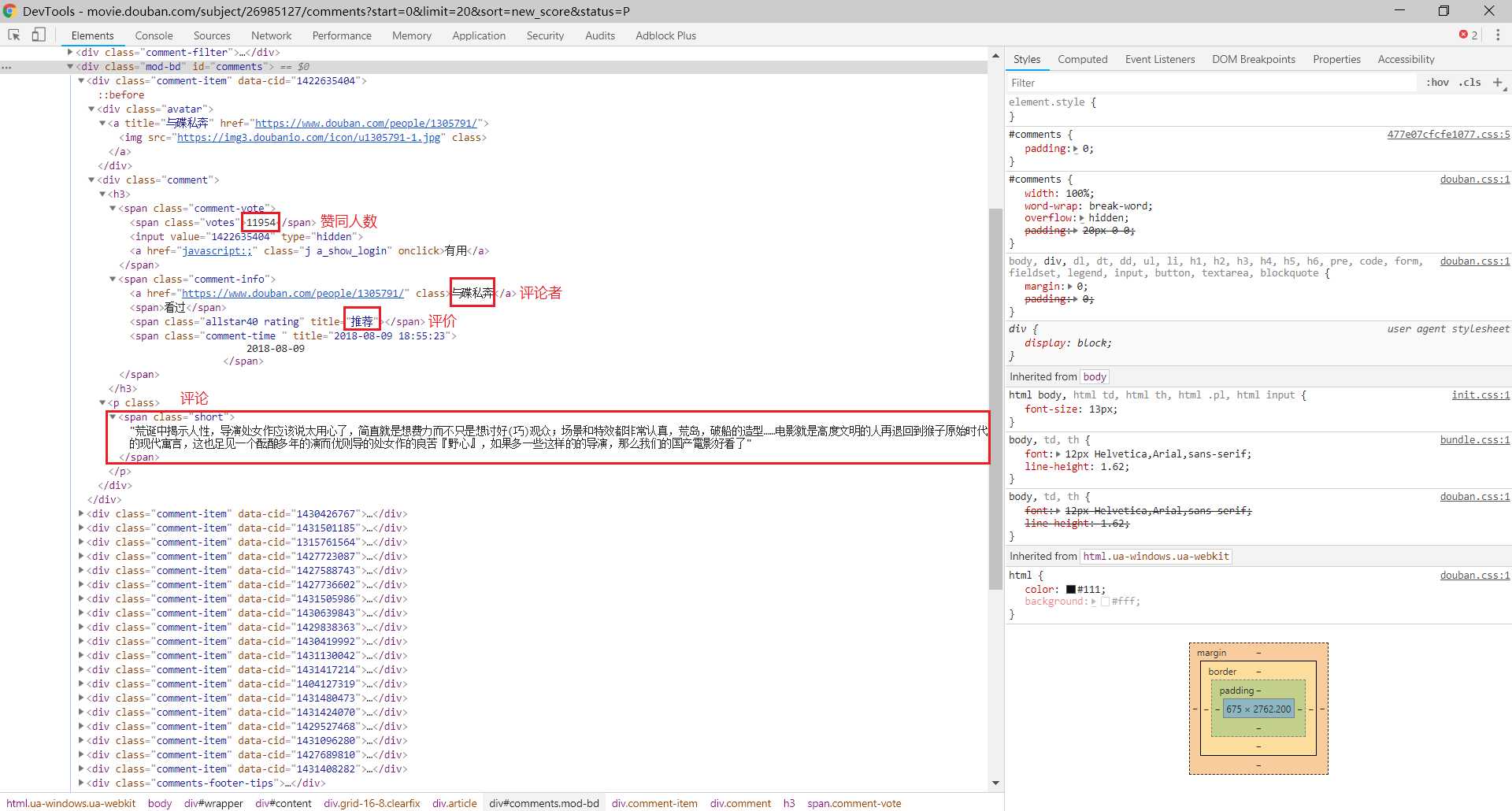
import requests
from lxml import etree
import time
import random
class DoubanSpider():
movieID = ""
def init(self):
self.movieID = input(‘请输入电影ID:‘)
def get_html(self,url):
headers = {
‘USER-AGENT‘:‘Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36‘
}
response = requests.get(url=url,headers=headers)
return response.text
def parse_page(self,html):
html = etree.HTML(html)
agrees = html.xpath(‘//div[@class="comment-item"]/div[2]/h3/span[1]/span/text()‘)
authods = html.xpath(‘//div[@class="comment-item"]/div[2]/h3/span[2]/a/text()‘)
stars = html.xpath(‘//div[@class="comment-item"]/div[2]/h3/span[2]/span[2]/@title‘)
contents = html.xpath(‘//div[@class="comment-item"]/div[2]/p/span/text()‘)
result = []
for i in range(len(agrees)):
data = {}
data[‘agree‘] = agrees[i].encode(‘utf-8‘).decode(‘utf-8‘)
data[‘authod‘] = authods[i].encode(‘utf-8‘).decode(‘utf-8‘)
data[‘star‘] = stars[i].encode(‘utf-8‘).decode(‘utf-8‘)
data[‘content‘] = contents[i].encode(‘utf-8‘).decode(‘utf-8‘)
result.append(data)
return result
def parse_link(self,html):
html = etree.HTML(html)
base_url = ‘https://movie.douban.com/subject/‘+str(self.movieID)+‘/comments‘
url = html.xpath(‘//div[@id="paginator"]/a[@class="next"]/@href‘)
if not url :
return "END"
link = base_url + url[0].encode(‘utf-8‘).decode(‘utf-8‘)
return link
def crawl(self):
print(‘Processing‘)
file = open(‘douban.txt‘,‘w‘,encoding=‘utf-8‘)
url = ‘https://movie.douban.com/subject/‘ + str(self.movieID) + ‘/comments?start=0&limit=20&sort=new_score&status=P&percent_type=‘
count = 0
while True :
time.sleep(random.random())
html = self.get_html(url)
result = self.parse_page(html)
for item in result:
count += 1
print(count)
file.write(‘--------------------‘+str(count)+‘--------------------\n‘)
file.write(‘评论者:‘)
file.write(item[‘authod‘])
file.write(‘\n‘)
file.write(‘赞同人数:‘)
file.write(item[‘agree‘])
file.write(‘\n‘)
file.write(‘评价:‘)
file.write(item[‘star‘])
file.write(‘\n‘)
file.write(‘评论内容:‘)
file.write(item[‘content‘])
file.write(‘\n‘)
url = self.parse_link(html)
if url==‘END‘ :
break
file.close()
print(‘Finished‘)
if __name__ == "__main__":
spider = DoubanSpider()
spider.init()
spider.crawl()写在后面的话 :通过之前的学习我们已经掌握了静态网页的爬取方法,下一篇文章我们将学习动态网页的爬取,谢谢大家
标签:提示 stat crawl tree src int pid wow 技术
原文地址:https://www.cnblogs.com/wsmrzx/p/9527087.html