标签:des style blog http io os ar strong 数据
考虑下图所示数据集:
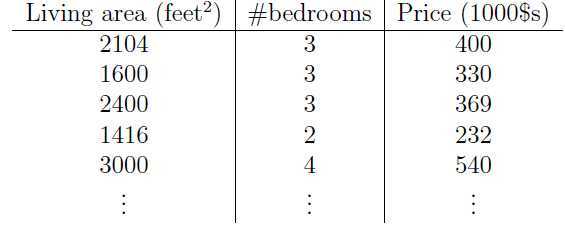
这是一个关于居住面积,卧室数量和房屋价格的数据集。
对于这个数据集,x就是二维的向量,因为每一个训练样本包含两个属性(居住面积,卧室数量)。
为了进行监督学习,必须提出一个合理的假设或函数,假如我们用线性函数
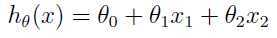
去近似y(对于上述数据集y就是房屋的价格),xi(i = 1,2,...m)代表第i个训练样本,θ就是我们要学习的参数,也可称之为权重。
现在知道训练集,该如何选择参数呢?我们的目的就是使得h(x)与y越接近越好,至少对于训练集如此。
所以定义一个损失函数(cost function)
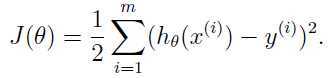
要满足学习目的,显然损失函数值越小越好,也就是说我们要优化损失函数,当损失函数最小时的参数就是我们要选择的参数。这就是典型的最小二乘法。
下面用梯度下降来最小化损失函数J(θ),更新公式如下:
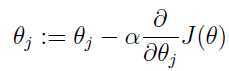
α是学习率,根据实际情况自己设定,所以关键是对J(θ)关于θ的求导:
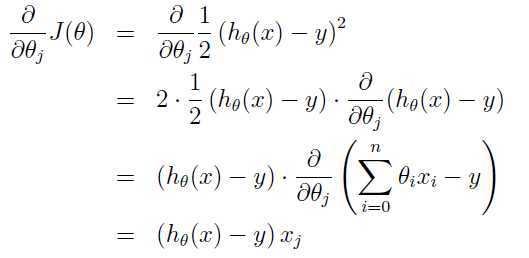
于是,可以得出关于参数更新的最终表达式:
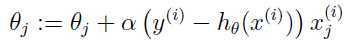
这条更新规则被称之为LMS(least mean squares)更新规则.自然而然且直观上理解就是当误差项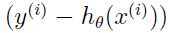 很小的情况下,就是我们的预测和实际值很接近的时候,对当前的参数就只需作出很小的改变,但是当这个误差项的值较大的时候,就是说预测和实际值的差别比较大,就需要我们对参数做出较大的改变。
很小的情况下,就是我们的预测和实际值很接近的时候,对当前的参数就只需作出很小的改变,但是当这个误差项的值较大的时候,就是说预测和实际值的差别比较大,就需要我们对参数做出较大的改变。
值得注意的是,上面的更新规则只针对了一个训练样本j,但是我们需要对整个训练集中的训练样本进行训练,而不只是某一个样本决定最终的参数。所以需要对上述参数更新公式做出调整,第一种调整如下:
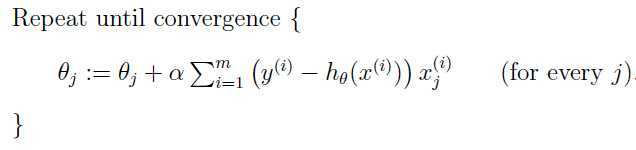
m是训练集中的样本数。这种更新方式下,每次更新一个参数θj需要遍历到训练集中的每一个样本,因此被称之为批量梯度下降(batch gradient descent),样本数量小的时候是完全可以,但是当样本数量非常巨大的时候,这样更新会使得算法效率很低,可以考虑下面的更新方式:
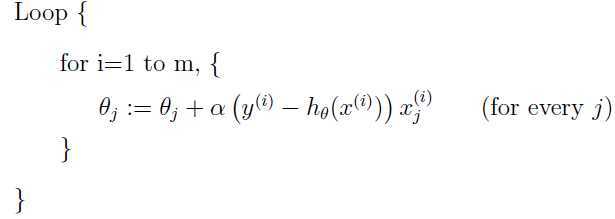
对于这种方式,每一步更新只需考虑一个训练样本,大大加速了参数更新的速度,因此被称之为随机梯度下降(stochastic gradient descent),但是这种更新方式有可能无法收敛到最小值,而是在最小值附近徘徊,庆幸的是虽然不能达到最小值,但是在实际中已经很接近最小值了,所以特别在样本数量非常巨大的时候,随机梯度下降要比批量梯度下降更好。
标签:des style blog http io os ar strong 数据
原文地址:http://www.cnblogs.com/90zeng/p/4008653.html