标签:yml 存储方式 拆分 传输 put cal ext map rop
ElasticSearch核心概念-Cluster
1)代表一个集群,集群中有多个节点,其中有一个为主节点,这个主节点是可以通过选举产生的,主从节点是对于集群内部来说的。es的一个概念就是去中心化,字面上理解就是无中心节点,这是对于集群外部来说的,因为从外部来看es集群,在逻辑上是个整体,你与任何一个节点的通信和与整个es集群通信是等价的。
2)主节点的职责是负责管理集群状态,包括管理分片的状态和副本的状态,以及节点的发现和删除。
3)注意:主节点不负责对数据的增删改查请求进行处理,只负责维护集群的相关状态信息。
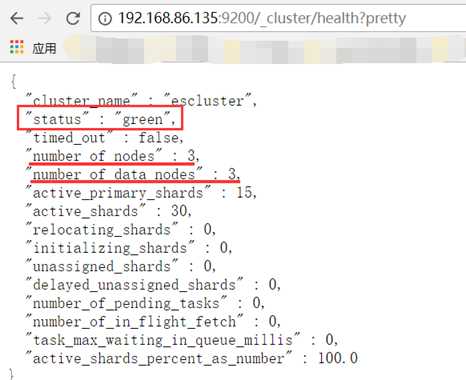
集群状态查看
http://192.168.20.135:9200/_cluster/health?pretty
ElasticSearch核心概念-shards
1)代表索引分片,es可以把一个完整的索引分成多个分片,这样的好处是可以把一个大的索引水平拆分成多个,分布到不同的节点上。构成分布式搜索, 提供性能和吞吐量。
2)分片的数量只能在创建索引库时指定,索引库创建后不能更改。
[hadoop@masternode elasticsearch-2.4.0]$ curl -XPUT ‘masternode:9200/zimo3/‘ -d‘{"settings":{"number_of_replicas":2}}‘
{"acknowledged":true}
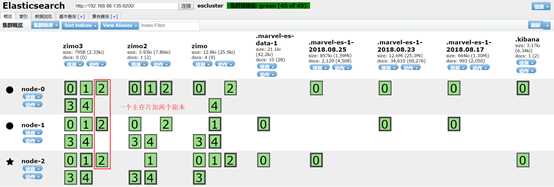
默认是一个索引库有5个分片
每个分片中最多存储2,147,483,519条数据
https://www.elastic.co/guide/en/elasticsearch/reference/2.4/_basic_concepts.html
ElasticSearch核心概念-replicas
代表索引副本,es可以给索引分片设置副本,
副本的作用:
一是提高系统的容错性,当某个节点某个分片损坏或丢失时可以从副本中恢复。
二是提高es的查询效率,es会自动对搜索请求进行负载均衡。
【副本的数量可以随时修改】
可以在创建索引库的时候指定
curl -XPUT ‘master:9200/zimo3/‘ -d‘{"settings":{"number_of_replicas":2}}‘
默认是一个分片有1个副本
index.number_of_replicas: 1
也可以修改已有库的副本数目
[hadoop@masternode elasticsearch-2.4.0]$ curl -XPUT ‘masternode:9200/zimo3/_settings‘ -d‘{"index":{"number_of_replicas":1}}‘ {"acknowledged":true}
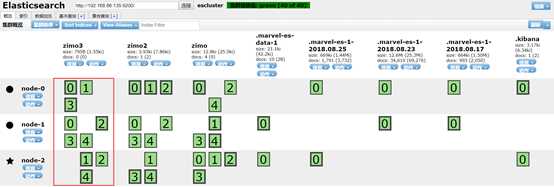
可以看到zimo3的副本数目较上面少了一个。
注意:主分片和副本不会存在一个节点中
ElasticSearch核心概念-recovery
代表数据恢复或叫数据重新分布,es在有节点加入或退出时会根据机器的负载对索引分片进行重新分配,挂掉的节点重新启动时也会进行数据恢复。
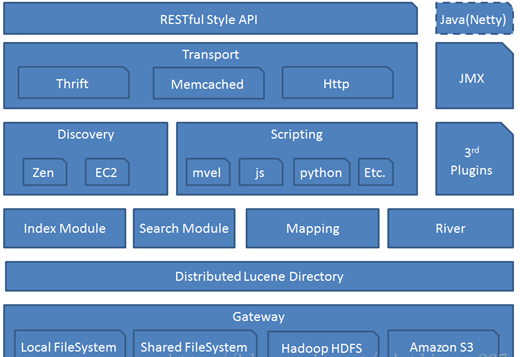
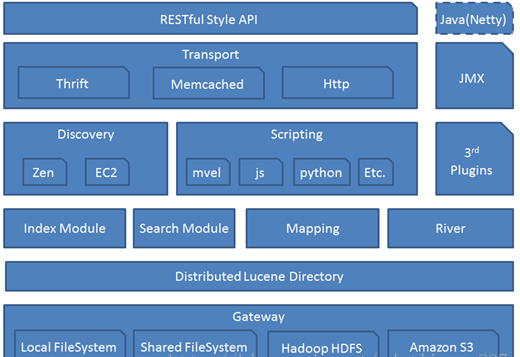
ElasticSearch核心概念-gateway
代表es索引的持久化存储方式,es默认是先把索引存放到内存中,当内存满了时再持久化到硬盘。当这个es集群关闭再重新启动时就会从gateway中读取索引数据。es支持多种类型的gateway,有本地文件系统(默认),分布式文件系统,Hadoop的HDFS和Amazon的s3云存储服务。
Hadoop插件安装
bin/plugin install elasticsearch/elasticsearch-repository-hdfs/2.2.0
官网安装说明
https://github.com/elastic/elasticsearch-hadoop/tree/master/repository-hdfs https://oss.sonatype.org/content/repositories/snapshots/org/elasticsearch/elasticsearch-repository-hdfs/
Hadoop 插件配置
vi elasticsearch.yml gateway: type: hdfs gateway: hdfs: uri: hdfs://localhost:9000
ElasticSearch核心概discovery.zen
代表es的自动发现节点机制,es是一个基于p2p的系统,它先通过广播寻找存在的节点,再通过多播协议来进行节点之间的通信,同时也支持点对点的交互。
如果是不同网段的节点如何组成es集群
禁用自动发现机制
discovery.zen.ping.multicast.enabled: false
设置新节点被启动时能够发现的主节点列表
discovery.zen.ping.unicast.hosts: ["192.168.20.135", "192.168.20.136", "192.168.20.137"]
ElasticSearch核心概Transport
代表es内部节点或集群与客户端的交互方式,默认内部是使用tcp协议进行交互,同时它支持http协议(json格式)、thrift、servlet、memcached、zeroMQ等的传输协议(通过插件方式集成)。
ElasticSearch Setting
settings修改索引库默认配置
https://www.elastic.co/guide/en/elasticsearch/reference/current/indices-create-index.html
例如:分片数量,副本数量
查看:
[hadoop@masternode elasticsearch-2.4.0]$ curl -XGET http://masternode:9200/zimo/_settings?pretty { "zimo" : { "settings" : { "index" : { "creation_date" : "1535008575806", "number_of_shards" : "5", "number_of_replicas" : "1", "uuid" : "oGqP-hgzRGuIxPCssdj3jA", "version" : { "created" : "2040099" } } } } }
操作不存在索引(创建):
curl -XPUT ‘http://master:9200/zimo3/‘ -d ‘{"settings":{"number_of_shards":3,"number_of_replicas":2}}‘
操作已存在索引(修改):
curl -XPUT ‘http://master:9200/zimo3/_settings‘ -d ‘{"index":{"number_of_replicas":1}}’
ElasticSearch Mapping
就是对索引库中索引的字段名称及其数据类型进行定义,类似于mysql中的表结构信息。不过es的mapping比数据库灵活很多,它可以动态识别字段。一般不需要指定mapping都可以,因为es会自动根据数据格式识别它的类型,如果你需要对某些字段添加特殊属性(如:定义使用其它分词器、是否分词、是否存储等),就必须手动添加mapping。
https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping.html
查询索引库的mapping信息:
[hadoop@masternode elasticsearch-2.4.0]$ curl -XGET http://masternode:9200/zimo/_mapping?pretty { "zimo" : { "mappings" : { "user" : { "properties" : { "age" : { "type" : "string" }, "name" : { "type" : "string" } } } } } }
操作不存在的索引(创建):
[hadoop@masternode elasticsearch-2.4.0]$ curl -XPUT ‘http://masternode:9200/zimo4‘ -d‘{"mapping":{"user":{"properties":{"name":{"type":"string","analyzer":"ik_max_word"}}}}}‘ {"acknowledged":true}
操作已存在的索引(修改):
curl -XPOST http://masternode:9200/zimo4/user/_mapping -d‘{"properties":{"name":{"type":"string","analyzer":"ik_max_word"}}}‘
更新或者修改已存在mapping遇到的问题
http://stackoverflow.com/questions/38179683/how-to-update-the-mapping-in-elasticsearch-to-change-the-field-datatype-and-chan
ElasticSearch 全文检索— ElasticSearch 核心概念
标签:yml 存储方式 拆分 传输 put cal ext map rop
原文地址:https://www.cnblogs.com/zimo-jing/p/9533198.html