标签:shape https data 函数 目标 scribe row pytorch llb
all_data = pd.concat([train.loc[:,‘first_feature‘ : ‘last_feature‘], test.loc[:,‘first_feature‘ : ‘last_feature‘]])
print(train.shape, test.shape, all_data.shape)
%matplotlib inline import numpy as np import pandas as pd import scipy as sp from scipy import stats from matplotlib import pyplot as plt import seaborn as sns
import sys print(sys.version) print(np.__version__) print(pd.__version__) print(sp.__version__)
train = pd.read_csv("./kaggle/train.csv") test = pd.read_csv("./kaggle/test.csv") all_data = pd.concat([train.loc[:,‘MSSubClass‘:‘SaleCondition‘], test.loc[:,‘MSSubClass‘:‘SaleCondition‘]]) all_data = all_data.reset_index(drop=True)
# df_allX 少了 Id 和 SalePrice 两列 print(train.shape, test.shape, all_data.shape)

pd.read_csv(file,... na_values=None, keep_default_na=True, ...)‘‘、‘#N/A‘、‘#N/A N/A‘、‘#NA‘、‘-1.#IND‘、‘-1.#QNAN‘、‘-NaN‘、‘-nan‘、‘1.#IND‘、‘1.#QNAN‘、‘N/A‘、‘NA‘、‘NULL‘、‘NaN‘、‘nan‘
train.describe()
describe() 方法的用法,参考:Pandas 和 Series 的 describe() 方法
train.head()
train.describe().T


# 数值量特征 feats_numeric = all_data.dtypes[all_data.dtypes != ‘object‘].index.values # feats_numeric = [attr for attr in all_data.columns in all_data.dtypes[attr] != ‘boject‘] # 字符量特征 feats_object = all_data.dtypes[all_data.dtypes == ‘object‘].index.values # feats_object = [attr for attr in all_data.columns if all_data.dtypes[attr] == ‘object‘] # feats_object = train.select_dtypes(include = [‘object‘]).columns print(feats_numeric.shape, feats_object.shape)
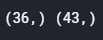
总共79个特征,pandas自动识别的 36个数值量,43个字符量。 —— 这是上表中第一个维度;
# 离散的数值量,需要人工甄别 feats_numeric_discrete = [‘MSSubClass‘, ‘OverallQual‘, ‘OverallCond‘]#户型、整体质量打分、整体条件打分 -- 文档中明确定义的类型量 feats_numeric_discrete += [‘TotRmsAbvGrd‘, ‘KitchenAbvGr‘, ‘BedroomAbvGr‘, ‘GarageCars‘, ‘Fireplaces‘]# 房间数量 feats_numeric_discrete += [‘FullBath‘, ‘HalfBoth‘, ‘BsmtHalfBath‘, ‘BsmtFullBath‘]# 浴室 feats_numeric_discrete += [‘MoSold‘, ‘YrSold‘]# 年份、月份,看成离散型特征 # 连续型特征 feats_continu = feats_numeric.copy() # 离散型特征 feats_discrete = feats_object.copy() for f in feats_numeric_discrete: feats_continu = np.delete(feats_continu, np.where(feats_continu == f)) feats_discrete = np.append(feats_discrete, f) print(feats_continu.shape, feats_discrete.shape)
# (22, ) (57, ):经过处理,得到表中第2个维度: 22个连续型特征,57个离散型特征;
def plotfeats(frame,feats,kind,cols=4): """批量绘图函数。 Parameters ---------- frame : pandas.DataFrame 待绘图的数据 feats : list 或 numpy.array 待绘图的列名称 kind : str 绘图格式:‘hist‘-直方图;‘scatter‘-散点图;‘hs‘-直方图和散点图隔行交替;‘box‘-箱线图,每个feat一幅图;‘boxp‘-Price做纵轴,feat做横轴的箱线图。 cols : int 每行绘制几幅图 """ rows = int(np.ceil((len(feats))/cols)) if rows==1 and len(feats)<cols: cols = len(feats) #print("输入%d个特征,分%d行、%d列绘图" % (len(feats), rows, cols)) if kind == ‘hs‘: #hs:hist and scatter fig, axes = plt.subplots(nrows=rows*2,ncols=cols,figsize=(cols*5,rows*10)) else: fig, axes = plt.subplots(nrows=rows,ncols=cols,figsize=(cols*5,rows*5)) if rows==1 and cols==1: axes = np.array([axes]) axes = axes.reshape(rows,cols) # 当 rows=1 时,axes.shape:(cols,),需要reshape一下 i=0 for f in feats: #print(int(i/cols),i%cols) if kind == ‘hist‘: #frame.hist(f,bins=100,ax=axes[int(i/cols),i%cols]) frame.plot.hist(y=f,bins=100,ax=axes[int(i/cols),i%cols]) elif kind == ‘scatter‘: frame.plot.scatter(x=f,y=‘SalePrice‘,ylim=(0,800000), ax=axes[int(i/cols),i%cols]) elif kind == ‘hs‘: frame.plot.hist(y=f,bins=100,ax=axes[int(i/cols)*2,i%cols]) frame.plot.scatter(x=f,y=‘SalePrice‘,ylim=(0,800000), ax=axes[int(i/cols)*2+1,i%cols]) elif kind == ‘box‘: frame.plot.box(y=f,ax=axes[int(i/cols),i%cols]) elif kind == ‘boxp‘: sns.boxplot(x=f,y=‘SalePrice‘, data=frame, ax=axes[int(i/cols),i%cols]) i += 1 plt.show()
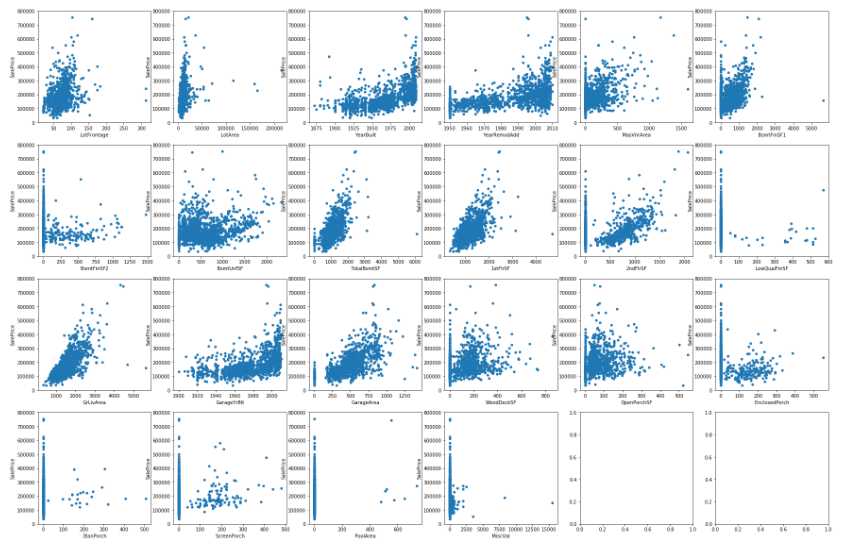
plotfeats(train, feats_continu, kind=‘scatter‘, cols=6)
标签:shape https data 函数 目标 scribe row pytorch llb
原文地址:https://www.cnblogs.com/volcao/p/9535296.html