标签:csdn .com 公式 推理 存在 nal 计算 加速 一起
DeepSpeech2中主要讲的几点
convolution layers --> rnn layers --> one fully connected layer
网络结构的输入是音频信号的频谱特征, 输出的是字母表中的一个个字母.(不同语言的字母表不一样). 训练是采用CTC损失函数.
在推理过程中,输入音频信号x,输出y是通过最大化下面的公式得到的:
\(Q(y) = log(P_{rnn}(y|x)) + \alpha log(P_{LM}(y)) + \beta wc(y)\)
其中wc表示输出序列的长度, 该公式就是鼓励翻译识别得到的句子包含更多的单词.为什么鼓励更多的单词呢?
我在语音识别训练中,遇到刚开始训练中,模型识别出来的字母都连在了一起,成了一大长串, 根本无法辨别.这种情况的识别得到的句子中单词是很少的.是这样解释吗?
实践发现, 在rnn layers中加入归一化, 能够加速模型的收敛和提高模型的泛化能力.归一化的方式主要有两种方式:(公式中W和U,与一些关于rnn表述的恰好相反)
方式1是在非线性函数前对其进行归一化\(h_t^{l} = f({B}(W^lh_t^{l-1}+U^lh_{t-1}^{l}))\)
方式2是仅仅对垂直连接方向进行归一化\(h_t^{l} = f({B}(W^lh_t^{l-1})+U^lh_{t-1}^{l})\)
实践表明,方式1效果不佳, 而方式2却能带来很大的性能提升
tensorflow中rnn是如何实现的??
参考https://blog.csdn.net/cjopengler/article/details/78227004
之前并没有了解rnn的结构及计算过程,或者是早就淡忘了,这里再来回忆加深一下认识
rnn结构的示意图如下图所示:
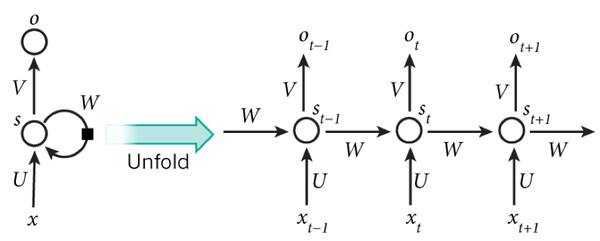
左侧是rnn的结构,右侧是并不是真实存在的结构,而是按照时间维度将左侧结构展开的示意图.一个rnn layer只有一个输入位,一个中间状态位,和一个输出位. 只不过针对一个序列, 不断的按序在输入位输入序列元素, 才会不断地得到中间状态值和输出值. 一般rnn中, 输入x,中间状态s和输出o都是向量. 中间状态s的维度就是通常所说的中间隐含节点的数目.
这样,按方式2对rnn layers进行归一化, 将会对各个隐含单元(rnn layer的状态向量的各个分量),计算其均值与方差. 计算是要遍历minibatch所有序列样本,从序列开始到序列结束.用文章中的原话就是, for each hidden unit we compute the mean and variance statistics over all items in the minibatch over the length of the sequences. 这样做也是十分合理的, 计算下一层的状态值, \(h_t^{l} = f(W^lh_t^{l-1}+U^lh_{t-1}^{l})\), 同一层同一时刻,不同样本,其值的差异也许是很大的; 即使同一序列样本,样本不同时刻的某层状态值也可能有很大差异性, 未来保证数值的稳定性, 因此要在对所有样本,样本的所有时刻进行归一化.
方式1计算均值方差,是遍历了minibatch中样本,但是没有遍历各个时刻. 方式1的计算方式是,对每个时刻单独求其均值与方差,忽略了不同时刻数值的差异性, 从而可能导致数值的不稳定性.
在运行Mozila开源的DeepSpeech过程中, 设置一个batchsize,运行开始时还很正常,运行一段时间后就出现了OOM问题. 最后查看issue得知,代码中对音频数据按大小升序排列, 所以运行到某个时刻, 加载的minibatch都是长度很长的音频数据,从而导致OOM问题. DeepSpeech2遇到的虽不是这个问题,但是也是由于序列过长导致的. 采用CTC损失函数,在训练初始阶段,遇到过长的序列,导致预测的概率接近于0,从而导致梯度不稳定训练不稳定. SortaGrad方法就是,对序列长度进行排序,选择长度适中的序列用于初始阶段的模型训练, 然后再使用全部的序列参与训练.
作者设计Lookahead Convolution的目的,是为了解决语音翻译实时性的问题.比如同声翻译,不能是别人说完了一整句话,你才能翻译.必须是边说边翻译,说几个词马上就能准确翻译.这就对现在的语音识别提出了更高的要求. 比如bidirectional rnn这个结构,就必须要求输入完整的一句话,才能进行计算.因为该结构t时刻的输出依赖t时刻之前的信息还依赖t时刻之后的信息. 如果改为常规的单向rnn结构,可以解决这个问题,但是单向rnn的性能比双向rnn的性能要差很多.主要还是未来的信息对当前识别还是很重要的.为此作者设计了一个新的结构Lookahead Convolution来解决这个问题.这个层t时刻输出不再依赖t时刻之后全部, 而是依赖t时刻之后若干个时间步. 这样翻译延迟就可以控制了.结构图如下所示:
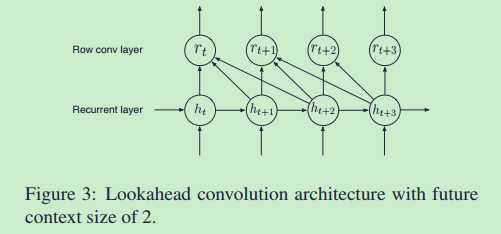
按照图中的结构,翻译延迟也就是2个时间步,相比bidirecitonal rnn还是可以接受的.公式化表示如下:
设\(h_t\)都是d维, Lookahead Convolution依赖未来\(\tau\)个时间步,参数矩阵\(W\in R^{(d,\tau)}\),从而得到\(r_t = \sum_{j=0}^{\tau-1}(\alpha_j, h_{t+j})\),其中\((\alpha_j, h_{t+j})\)表示点乘操作,故而\(\alpha\)也是d维的, 因此参数矩阵可以看作是由\(\alpha\)按列组合而成的即\(W = [\alpha_0, \alpha_2, ..., \alpha_{\tau - 1}]\)
标签:csdn .com 公式 推理 存在 nal 计算 加速 一起
原文地址:https://www.cnblogs.com/wolfling/p/9535541.html