标签:math 解释 ali vector 两种 全面 向量 tor 位置
Attention 机制
介绍Attention机制过程中,经常提到t时刻或者i位置,其实这两种表述本质上是一样的,只不过是序列在不同问题上表达方式不同而已. 在机器翻译中,使用术语位置更合适些;而在语音识别中使用术语时刻更合适些.
先清楚几个变量(以机器翻译为例)
2.1 \(X\): 待翻译语句\(X=(x_1, x_2, ..., x_{T_x})\),语句的长度为\(T_x\)
2.2 \(Y\): 目标翻译语句\(Y=(y_1, y_2, ..., y_{T_y})\), 语句的长度是\(T_y\)
2.3 \(\bf h\): 待翻译语句的特征表达\({\bf h} = (h_1, h_2, ..., h_{T_x})\),此处保持与待翻译语句一样的维度. 特征表达是经过encorder模块得到
2.4 \(s_i\): decorder模块每个输出位置都有对应一个状态
2.5 \(c_i\): decorder模块每个位置输出过程,decorder所关注特征表达也有所不同.
2.6 decorder模块包含很多个输出位置, 每个位置都对应一个输出y, 一个状态s和关注的特征h
下面再详细介绍一下,\(\bf h\), \(s_i\), \(c_i\)
\(\bf h\)是待翻译语句\(X\)经过encorder编码得到的特征表示, [1]中指出, 学习得到的\({\bf h} = (h_1, h_2, ..., h_{T_x})\)中的每个分量都包含了关于整个输入语句\(X\)的信息, 不过每个分量也所侧重. 分量\(h_j\)更多地关注输入语句第j个位置单词\(x_j\)周围的几个单词. 这是由于采用双向RNN结构的结果. 单向RNN, \(h_j = f(x_j, h_{j-1})\), 所以特征第i个分量\(h_j\), 是包含了输入语句第1个到第j个单词的信息, 但是不包括j+1之后的单词信息,采用了双向RNN结构, 就能保证每个特征分量都包含整个输入语句的信息. 如下图所示
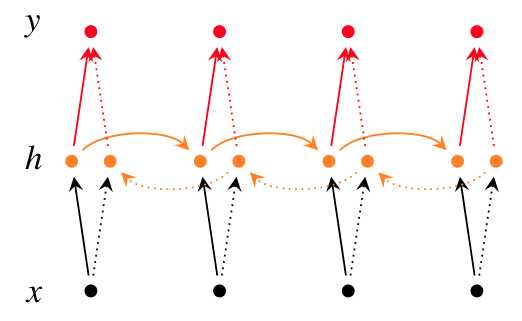
decorder模块每个位置都对应一个状态, 记第i个位置对应的状态为\(s_i\), 状态值与输入语句\(X\)有关, 输入语句变了, decorder模块的所有位置状态值都会发生变换.当然decorder第i个位置的状态\(s_i\), 还与前一个位置状态\(s_{i-1}\)和前一个位置输出\(y_{i-1}\). 公式化表示为\(s_i = f(y_{i-1}, s_{i-1}, {\bf h})\) . 由于是Attention based encorder-decorder, 计算第i个位置的状态,输出,依赖的特征向量\(\bf h\)都替换成下面将要提到的有所侧重的特征内容\(c_i\). 所以, \(s_i = f(y_{i-1}, s_{i-1}, c_i)\)
context vector \(c_i\), 在计算decorder模块第i位置的状态和输出时,都要用到的. 那么\(c_i\)的含义是什么呢?定义如下:\(c_i = \sum _j a_{ij}h_j\), \(a_{ij}\)解释为生成的第i个单词\(y_i\),对齐自或者翻译自输入语句的第j个单词\(x_j\)(特征表达的第j个分量)的概率. \(c_i\)就是输入语句特征表达(代表各个单词的特征分量)的期望,反映了生成第i个单词,decorder重点关注的输入单词/输入单词的特征表达.
其实,很多论文中都是定义为输入语句特征分量的加权和, 但是我也觉得使用点乘${\bf a_i * h} = (a_{11}h_1, a_{12}h_2, ..., a_{1T_{x}}h_{T_x}) $ 也可以作为\(c_i\)的定义.
那么上面的\(a_{ij}\)又该如何定义计算呢? \(a_{ij}=\frac{exp(e_{ij})}{\sum_k exp(e_{ik})}\), 其中\(e_{ij}=a(s_{i-1}, h_j)\)用于衡量decorder模块第i个位置输出单词\(y_i\)与输入语句第j个单词(输入语句特征表达第j个分量)的相关度.
[2]中对各种Attention机制介绍比较全面
[1] Neural machine translation by jointly learning to align and translate
[2] https://zhuanlan.zhihu.com/p/31547842
标签:math 解释 ali vector 两种 全面 向量 tor 位置
原文地址:https://www.cnblogs.com/wolfling/p/9535560.html