标签:persist 技术分享 api文档 clust memory 实践 角色 分布 manager
spark 已经成为广告、报表以及推荐系统等大数据计算场景中首选系统,因效率高,易用以及通用性越来越得到大家的青睐,我自己最近半年在接触spark以及spark streaming之后,对spark技术的使用有一些自己的经验积累以及心得体会,在此分享给大家。
本文依次从spark生态,原理,基本概念,spark streaming原理及实践,还有spark调优以及环境搭建等方面进行介绍,希望对大家有所帮助。
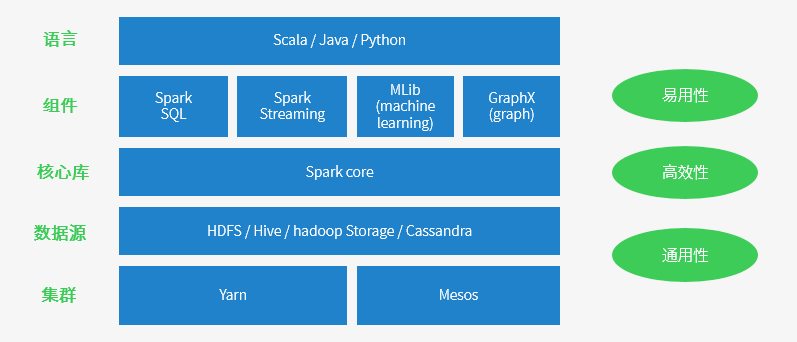
运行速度快 => Spark拥有DAG执行引擎,支持在内存中对数据进行迭代计算。官方提供的数据表明,如果数据由磁盘读取,速度是Hadoop MapReduce的10倍以上,如果数据从内存中读取,速度可以高达100多倍。
适用场景广泛 => 大数据分析统计,实时数据处理,图计算及机器学习
易用性 => 编写简单,支持80种以上的高级算子,支持多种语言,数据源丰富,可部署在多种集群中
容错性高。Spark引进了弹性分布式数据集RDD (Resilient Distributed Dataset) 的抽象,它是分布在一组节点中的只读对象集合,这些集合是弹性的,如果数据集一部分丢失,则可以根据“血统”(即充许基于数据衍生过程)对它们进行重建。另外在RDD计算时可以通过CheckPoint来实现容错,而CheckPoint有两种方式:CheckPoint Data,和Logging The Updates,用户可以控制采用哪种方式来实现容错。
目前大数据处理场景有以下几个类型:
复杂的批量处理(Batch Data Processing),偏重点在于处理海量数据的能力,至于处理速度可忍受,通常的时间可能是在数十分钟到数小时;
基于历史数据的交互式查询(Interactive Query),通常的时间在数十秒到数十分钟之间
基于实时数据流的数据处理(Streaming Data Processing),通常在数百毫秒到数秒之间
目前大数据在互联网公司主要应用在广告、报表、推荐系统等业务上。在广告业务方面需要大数据做应用分析、效果分析、定向优化等,在推荐系统方面则需要大数据优化相关排名、个性化推荐以及热点点击分析等。这些应用场景的普遍特点是计算量大、效率要求高。
腾讯 / yahoo / 淘宝 / 优酷土豆
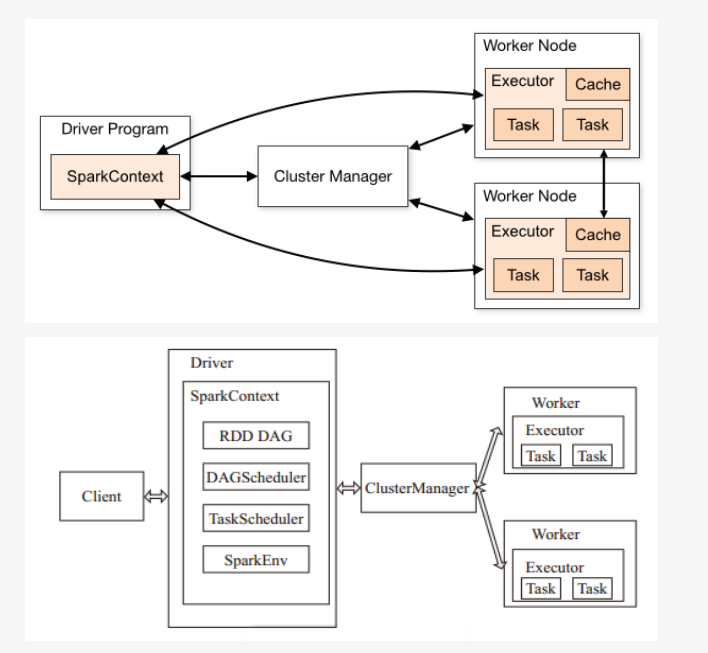
spark基础运行架构如下所示:
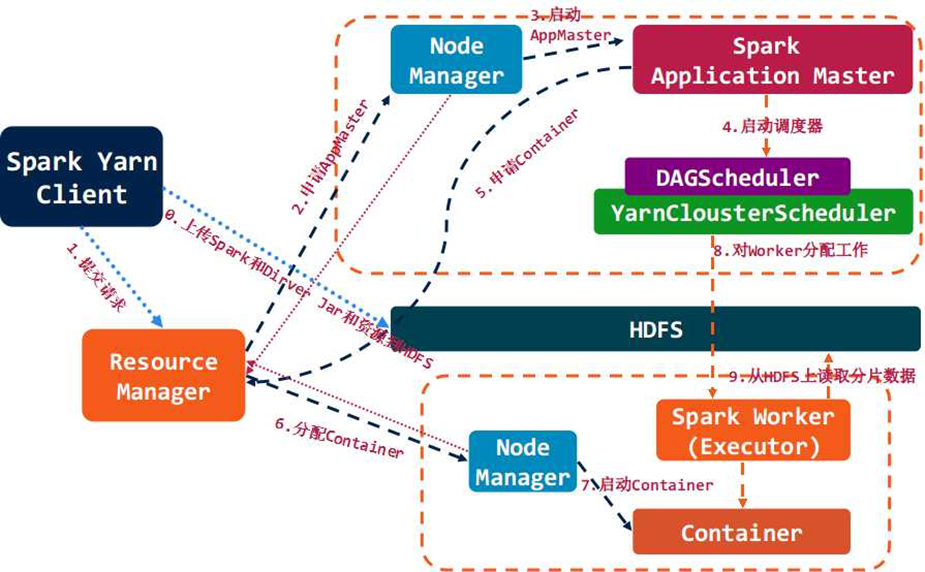
spark结合yarn集群背后的运行流程如下所示:
spark 运行流程:
Spark架构采用了分布式计算中的Master-Slave模型。Master是对应集群中的含有Master进程的节点,Slave是集群中含有Worker进程的节点。
Master作为整个集群的控制器,负责整个集群的正常运行;
Worker相当于计算节点,接收主节点命令与进行状态汇报;
Executor负责任务的执行;
Client作为用户的客户端负责提交应用;
Driver负责控制一个应用的执行。
Spark集群部署后,需要在主节点和从节点分别启动Master进程和Worker进程,对整个集群进行控制。在一个Spark应用的执行过程中,Driver和Worker是两个重要角色。Driver 程序是应用逻辑执行的起点,负责作业的调度,即Task任务的分发,而多个Worker用来管理计算节点和创建Executor并行处理任务。在执行阶段,Driver会将Task和Task所依赖的file和jar序列化后传递给对应的Worker机器,同时Executor对相应数据分区的任务进行处理。
Excecutor /Task 每个程序自有,不同程序互相隔离,task多线程并行
集群对Spark透明,Spark只要能获取相关节点和进程
Driver 与Executor保持通信,协作处理
三种集群模式:
1.Standalone 独立集群
2.Mesos, apache mesos
3.Yarn, hadoop yarn
基本概念:
Application =>Spark的应用程序,包含一个Driver program和若干Executor
SparkContext => Spark应用程序的入口,负责调度各个运算资源,协调各个Worker Node上的Executor
Driver Program => 运行Application的main()函数并且创建SparkContext
Executor => 是为Application运行在Worker node上的一个进程,该进程负责运行Task,并且负责将数据存在内存或者磁盘上。每个Application都会申请各自的Executor来处理任务
Cluster Manager =>在集群上获取资源的外部服务 (例如:Standalone、Mesos、Yarn)
Worker Node => 集群中任何可以运行Application代码的节点,运行一个或多个Executor进程
Task => 运行在Executor上的工作单元
Job => SparkContext提交的具体Action操作,常和Action对应
Stage => 每个Job会被拆分很多组task,每组任务被称为Stage,也称TaskSet
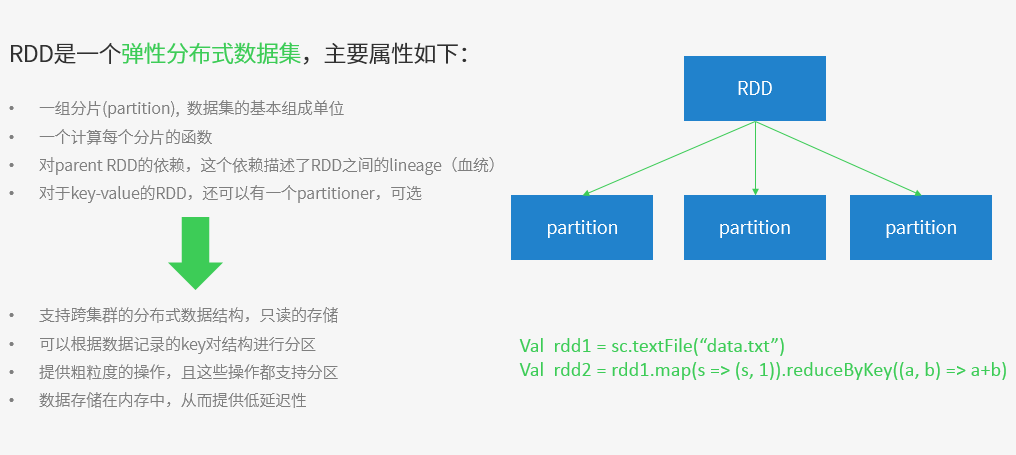
RDD => 是Resilient distributed datasets的简称,中文为弹性分布式数据集;是Spark最核心的模块和类
DAGScheduler => 根据Job构建基于Stage的DAG,并提交Stage给TaskScheduler
TaskScheduler => 将Taskset提交给Worker node集群运行并返回结果
Transformations => 是Spark API的一种类型,Transformation返回值还是一个RDD,所有的Transformation采用的都是懒策略,如果只是将Transformation提交是不会执行计算的
Action => 是Spark API的一种类型,Action返回值不是一个RDD,而是一个scala集合;计算只有在Action被提交的时候计算才被触发。
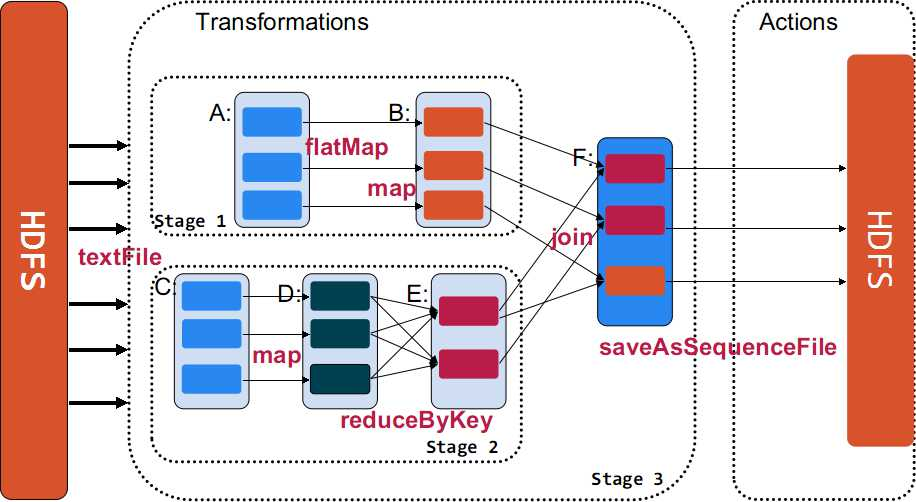
Transformation返回值还是一个RDD。它使用了链式调用的设计模式,对一个RDD进行计算后,变换成另外一个RDD,然后这个RDD又可以进行另外一次转换。这个过程是分布式的。 Action返回值不是一个RDD。它要么是一个Scala的普通集合,要么是一个值,要么是空,最终或返回到Driver程序,或把RDD写入到文件系统中。
Action是返回值返回给driver或者存储到文件,是RDD到result的变换,Transformation是RDD到RDD的变换。
只有action执行时,rdd才会被计算生成,这是rdd懒惰执行的根本所在。
Job => 包含多个task的并行计算,一个action触发一个job
stage => 一个job会被拆为多组task,每组任务称为一个stage,以shuffle进行划分
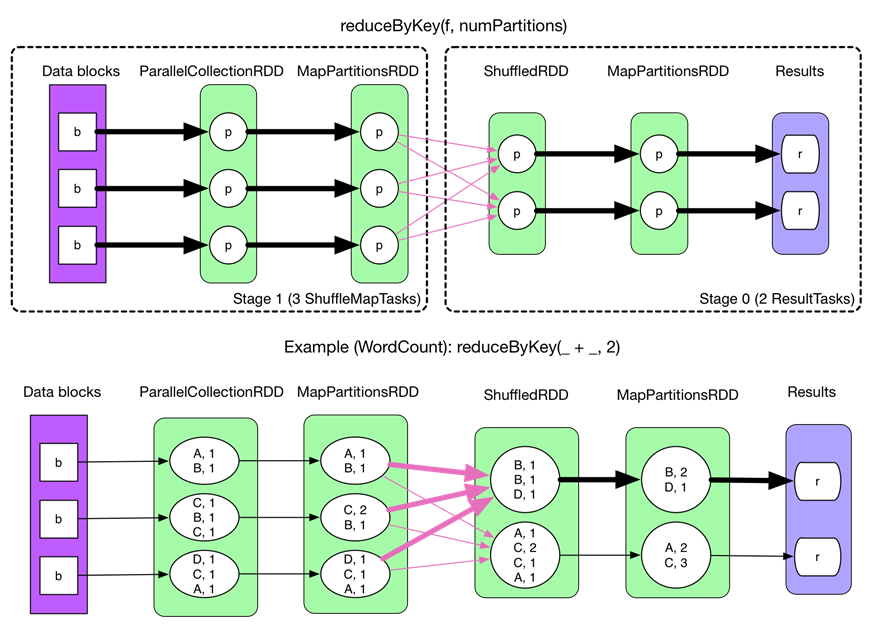
以reduceByKey为例解释shuffle过程。
在没有task的文件分片合并下的shuffle过程如下:(spark.shuffle.consolidateFiles=false)

fetch 来的数据存放到哪里?
刚 fetch 来的 FileSegment 存放在 softBuffer 缓冲区,经过处理后的数据放在内存 + 磁盘上。这里我们主要讨论处理后的数据,可以灵活设置这些数据是“只用内存”还是“内存+磁盘”。如果spark.shuffle.spill = false就只用内存。由于不要求数据有序,shuffle write 的任务很简单:将数据 partition 好,并持久化。之所以要持久化,一方面是要减少内存存储空间压力,另一方面也是为了 fault-tolerance。
shuffle之所以需要把中间结果放到磁盘文件中,是因为虽然上一批task结束了,下一批task还需要使用内存。如果全部放在内存中,内存会不够。另外一方面为了容错,防止任务挂掉。
存在问题如下:
产生的 FileSegment 过多。每个 ShuffleMapTask 产生 R(reducer 个数)个 FileSegment,M 个 ShuffleMapTask 就会产生 M * R 个文件。一般 Spark job 的 M 和 R 都很大,因此磁盘上会存在大量的数据文件。
缓冲区占用内存空间大。每个 ShuffleMapTask 需要开 R 个 bucket,M 个 ShuffleMapTask 就会产生 MR 个 bucket。虽然一个 ShuffleMapTask 结束后,对应的缓冲区可以被回收,但一个 worker node 上同时存在的 bucket 个数可以达到 cores R 个(一般 worker 同时可以运行 cores 个 ShuffleMapTask),占用的内存空间也就达到了cores× R × 32 KB。对于 8 核 1000 个 reducer 来说,占用内存就是 256MB。
为了解决上述问题,我们可以使用文件合并的功能。
在进行task的文件分片合并下的shuffle过程如下:(spark.shuffle.consolidateFiles=true)
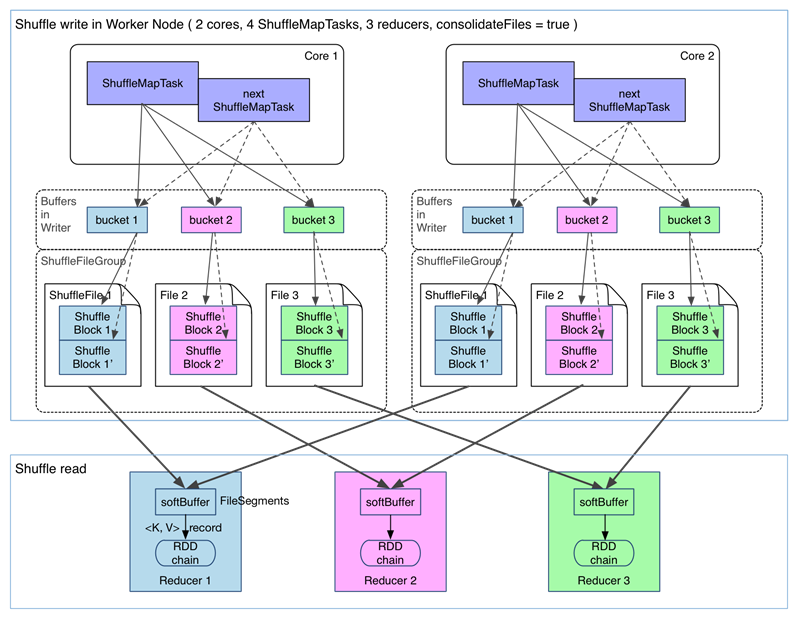
可以明显看出,在一个 core 上连续执行的 ShuffleMapTasks 可以共用一个输出文件 ShuffleFile。先执行完的 ShuffleMapTask 形成 ShuffleBlock i,后执行的 ShuffleMapTask 可以将输出数据直接追加到 ShuffleBlock i 后面,形成 ShuffleBlock i‘,每个 ShuffleBlock 被称为 FileSegment。下一个 stage 的 reducer 只需要 fetch 整个 ShuffleFile 就行了。这样,每个 worker 持有的文件数降为 cores× R。FileConsolidation 功能可以通过spark.shuffle.consolidateFiles=true来开启。
val rdd1 = ... // 读取hdfs数据,加载成RDD
rdd1.cache
val rdd2 = rdd1.map(...)
val rdd3 = rdd1.filter(...)
rdd2.take(10).foreach(println)
rdd3.take(10).foreach(println)
rdd1.unpersist
cache和unpersisit两个操作比较特殊,他们既不是action也不是transformation。cache会将标记需要缓存的rdd,真正缓存是在第一次被相关action调用后才缓存;unpersisit是抹掉该标记,并且立刻释放内存。只有action执行时,rdd1才会开始创建并进行后续的rdd变换计算。
cache其实也是调用的persist持久化函数,只是选择的持久化级别为MEMORY_ONLY。
persist支持的RDD持久化级别如下:

需要注意的问题:
Cache或shuffle场景序列化时, spark序列化不支持protobuf message,需要java 可以serializable的对象。一旦在序列化用到不支持java serializable的对象就会出现上述错误。
Spark只要写磁盘,就会用到序列化。除了shuffle阶段和persist会序列化,其他时候RDD处理都在内存中,不会用到序列化。
spark程序是使用一个spark应用实例一次性对一批历史数据进行处理,spark streaming是将持续不断输入的数据流转换成多个batch分片,使用一批spark应用实例进行处理。
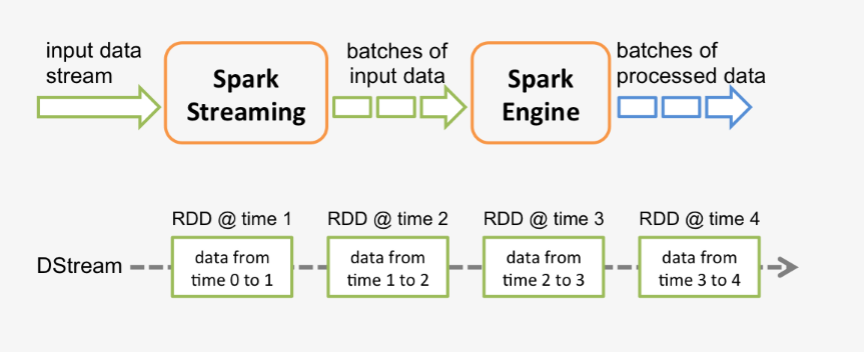
从原理上看,把传统的spark批处理程序变成streaming程序,spark需要构建什么?
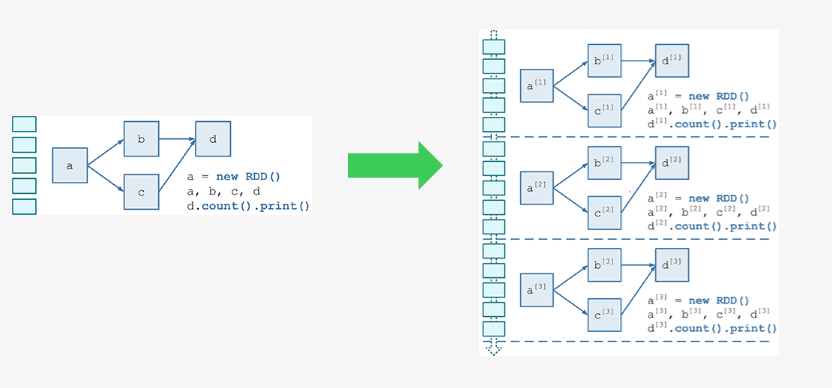
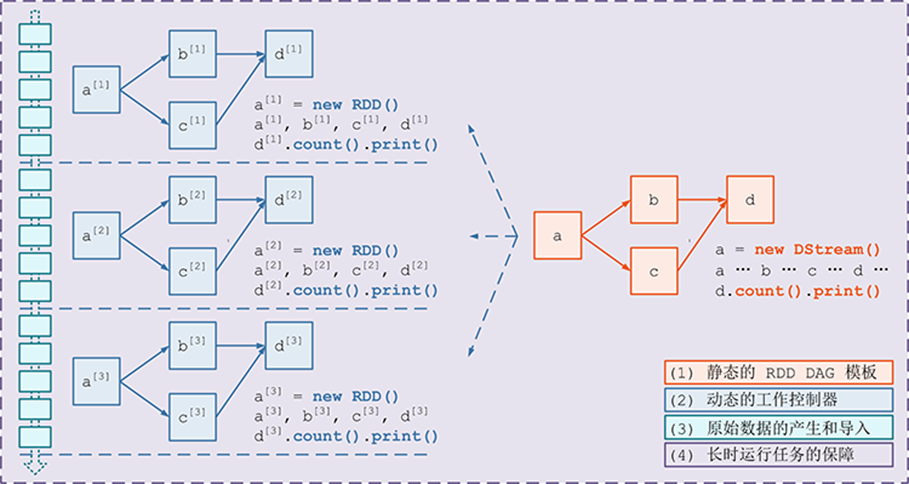
需要构建4个东西:
一个静态的 RDD DAG 的模板,来表示处理逻辑;
一个动态的工作控制器,将连续的 streaming data 切分数据片段,并按照模板复制出新的 RDD ;
DAG 的实例,对数据片段进行处理;
Receiver进行原始数据的产生和导入;Receiver将接收到的数据合并为数据块并存到内存或硬盘中,供后续batch RDD进行消费;
对长时运行任务的保障,包括输入数据的失效后的重构,处理任务的失败后的重调。
具体streaming的详细原理可以参考广点通出品的源码解析文章:
对于spark streaming需要注意以下三点:
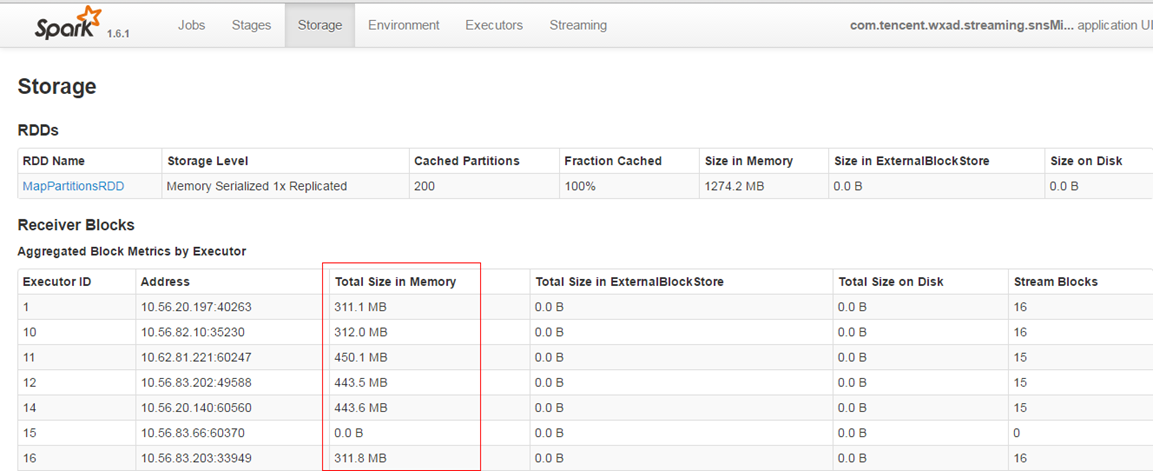
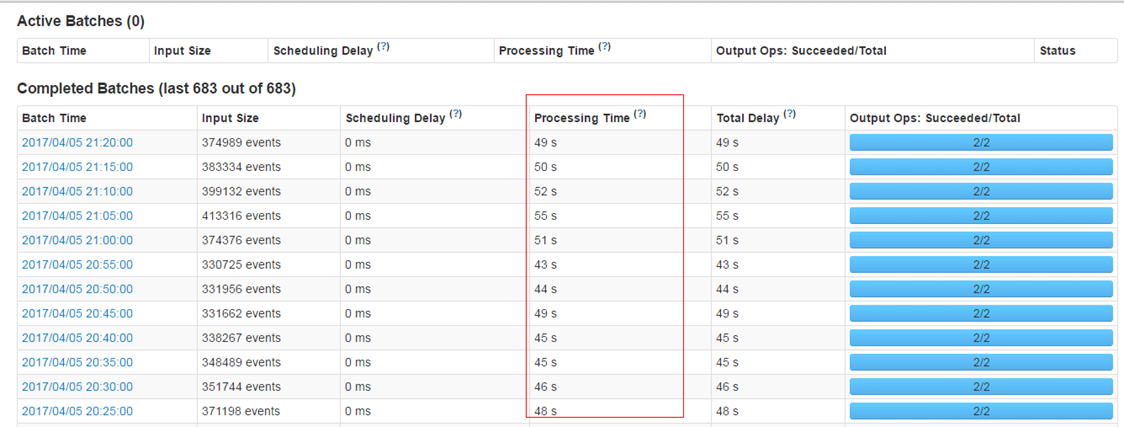
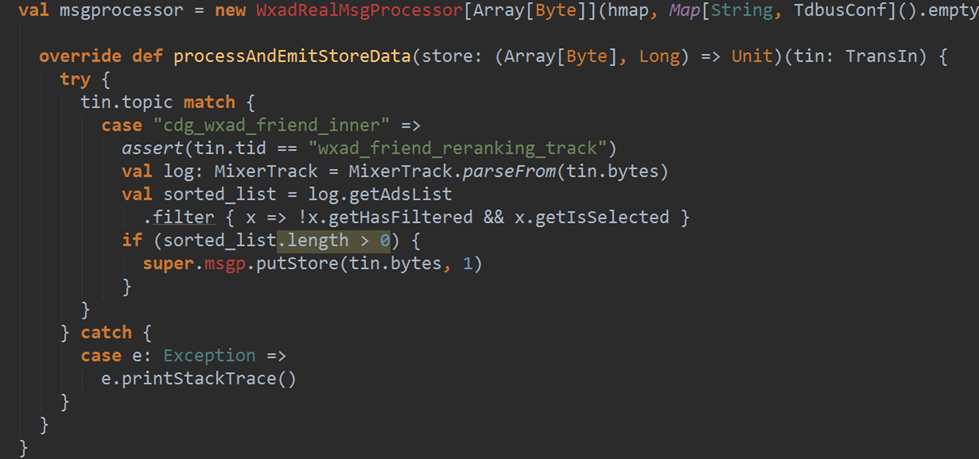
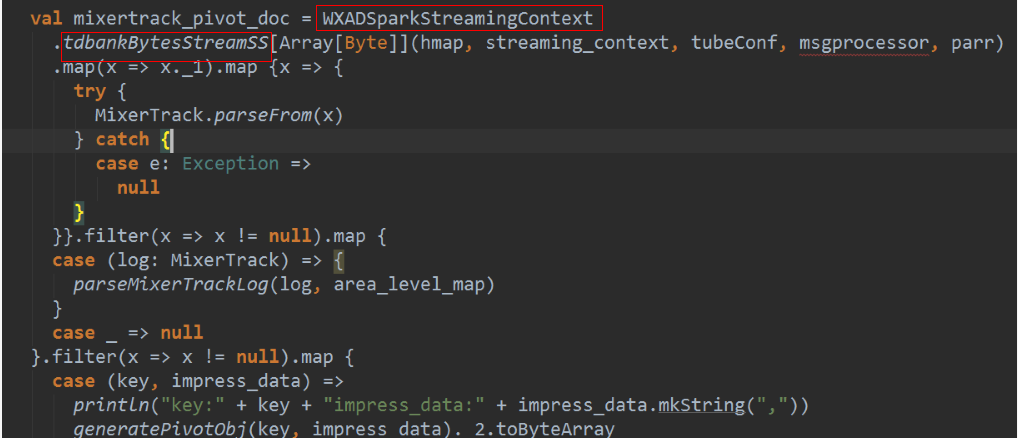
内存管理:
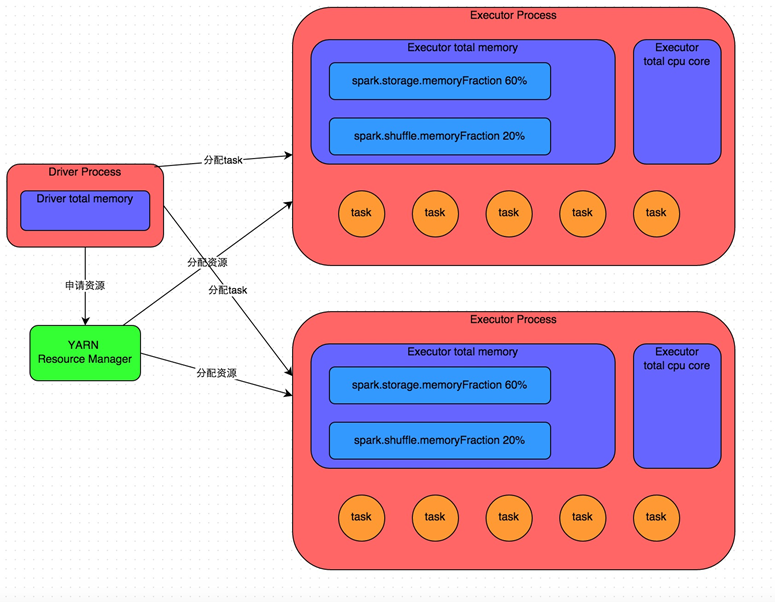
Executor的内存主要分为三块:
第一块是让task执行我们自己编写的代码时使用,默认是占Executor总内存的20%;
第二块是让task通过shuffle过程拉取了上一个stage的task的输出后,进行聚合等操作时使用,默认也是占Executor总内存的20%;
第三块是让RDD持久化时使用,默认占Executor总内存的60%。
每个task以及每个executor占用的内存需要分析一下。每个task处理一个partiiton的数据,分片太少,会造成内存不够。
其他资源配置:

具体调优可以参考美团点评出品的调优文章:
http://tech.meituan.com/spark-tuning-basic.html
http://tech.meituan.com/spark-tuning-pro.html
spark tdw以及tdbank api文档:
http://git.code.oa.com/tdw/tdw-spark-common/wikis/api
其他学习资料:
http://km.oa.com/group/2430/articles/show/257492
原文链接:https://www.qcloud.com/community/article/770164
标签:persist 技术分享 api文档 clust memory 实践 角色 分布 manager
原文地址:https://www.cnblogs.com/zourui4271/p/9537202.html