标签:评估 降级 size 数据 相关 访问 失败 事故 controls
转java 3年了,记一个最近的坑;
临近818,苏宁小店线上 app 搞了个秒杀活动,后台服务出现了异常。
活动是周五 10 点,收到了系统的告警短信,同事开始有人在公司豆芽(苏宁内部通信工具)反馈有部分用户下单失败;
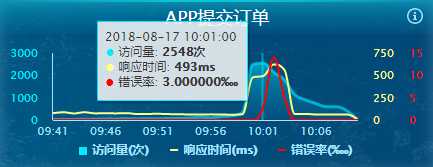
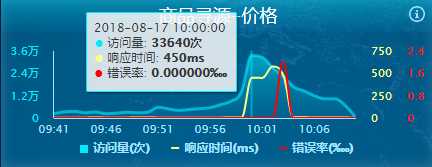
在监控仪表盘上也可以看到访问量开始剧增,同时响应时间开始变长,中台价格系统开始报错,导致后面的接口系统报错。
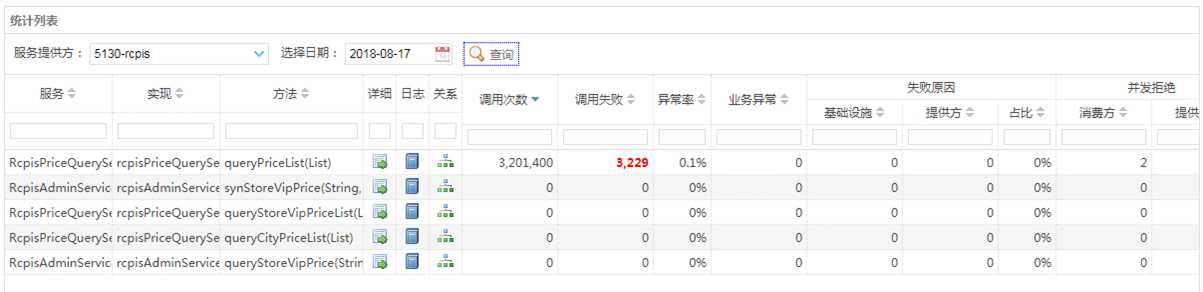
去日志平台查看了价格系统接口的调用情况。我们可以看到接口响应时间是慢慢变慢的,最后开始出现了报错现象。去查看报错信息 Timeout 报错。
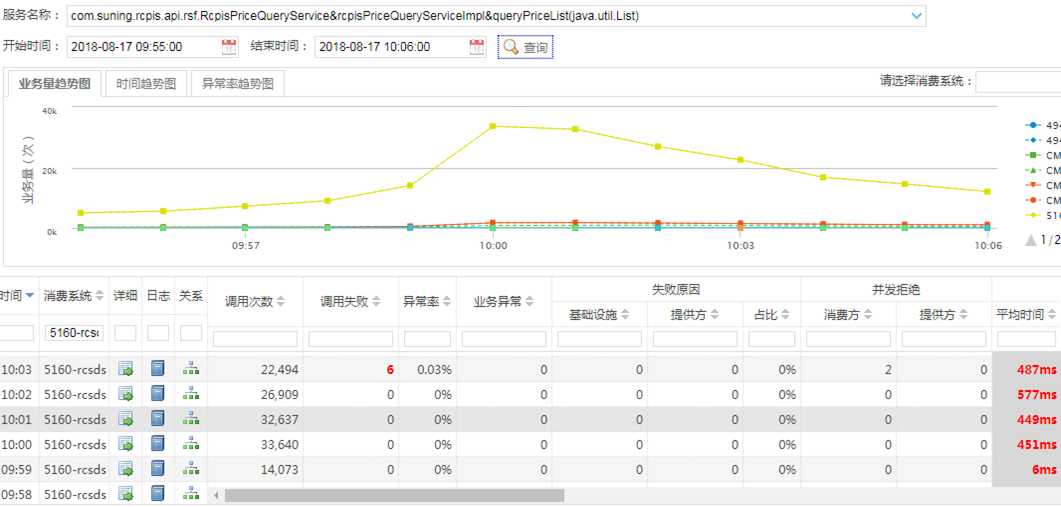
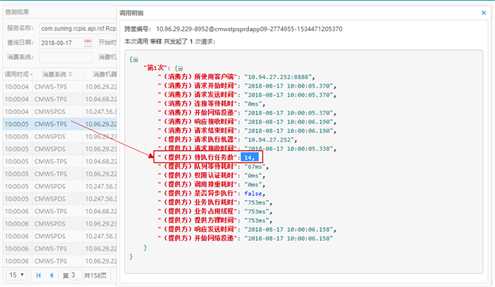
查看耗时过长接口的调用明细,可以看到价格系统的接口已经开始出现了积压,后面的接口需要等待前面的接口处理完成了才会处理,所以接口的耗时也不断的增长。查看了下代码逻辑只是从 Redis 里读取数据,应该几毫秒就处理的事情怎么会这么慢导致了积压呢?难道 Redis 出现了问题?
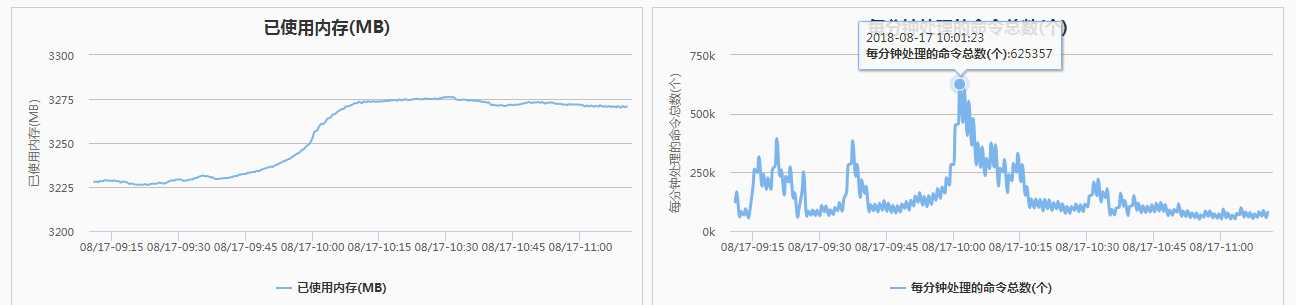
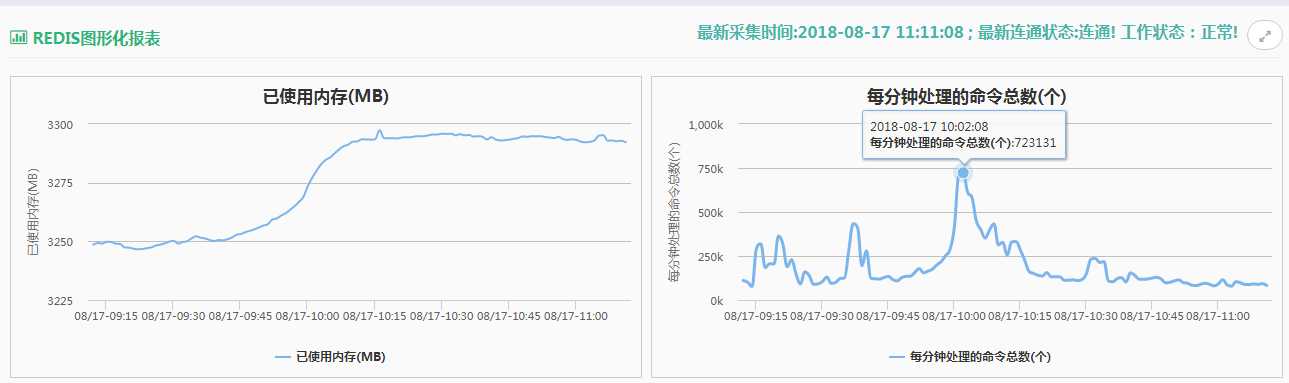
还真是,原来价格系统是和主数据系统共用的一套 Redis [两组(一主两从)]
图片贴出的是其中两台主库的压力分别是 72w 和 62w 。内存使用率也是居高不下。
给价格系统独立申请了两组 Redis,晚上通宵发布(苦逼啊)。
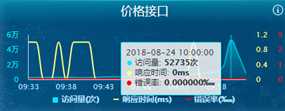
当晚升级后,做了次压测,价格接口可以支持峰值 70w 次/分钟的调用,这周五的活动从仪表盘上也是看到轻轻松松无压力了。(0ms 是因为仪表板精确到ms 四舍五入了)
总结
1.没有按活动人数评估系统压力做相应的压力测试,导致生成事故。做活动时候产品和运营应该预估好活动人数和开发沟通,开发应该对目前的系统能否支持这样的流量有一个认知不能想当然,如果不确定可以联系测试做压力测试。很显然这次的事故并没有做相关的工作。
2.没有降级方案对服务进行熔断或降级,导致前台系统直接报错。
如果你看到了这里,那么请长按二维码,关注我,一起成长!

标签:评估 降级 size 数据 相关 访问 失败 事故 controls
原文地址:https://www.cnblogs.com/fishlynn/p/9542477.html